Les 1
Leeruitkomsten
- De student kan werken in een R project.
- De student kan code verwerken in een R script en dit van informatieve comments voorzien.
- De student kan R packages gebruiken voor het verwerken van data.
- De student kan RDS bestanden inlezen in R.
- De student kent de verschillende data structuren in R (vectors, lists en dataframes/tibbles).
- De student kan algemene eigenschappen (bijvoorbeeld het aantal rijen en kolommen, en de kolomnamen) van de data achterhalen met R.
Voorbereiding
Introductie in R en RStudio
Wat is R en waarom zou je het leren?
R is een programmeertaal die binnen de Life Sciences veel wordt gebruikt voor het analyseren van data. Naast R bestaan er nog andere programmeertalen, zoals bijvoorbeeld Python en Bash. Omdat R de meest gebruikte programmeertaal is in het werkveld, hebben we ervoor gekozen om jullie deze taal te leren in het eerste jaar van de opleiding.
Het idee van programmeren is dat je de stappen die de computer voor jou uit moet voeren, uitschrijft in een bestand: het script. Het voordeel van dit uitschrijven is dat je de stappen eenvoudig kunt herhalen op een nieuwe dataset. In Excel en JASP moet je voor elke nieuwe dataset de stappen herhalen door te klikken in het programma. Met een script is dat klikken niet meer nodig en rolt de gewenste analyse of visualisatie ‘vanzelf’ uit R. Het schrijven van scripts is dus iets wat het leven makkelijker maakt. Bovendien vergroten scripts de reproduceerbaarheid van de data analyse: in een script zijn alle analysestappen uitgeschreven en weet je precies wat er gedaan is om tot een bepaald resultaat te komen. Dat is niet het geval bij een Excel of JASP bestand, want je kunt daarin niet eenvoudig herleiden waar de maker van dat bestand op geklikt heeft.
R is een heel veelzijdige programmeertaal. Je kunt R gebruiken als alternatief voor Excel en JASP: zo kun je met R data bewerken, grafieken maken en data statistisch analyseren. Maar met R kun je ook dingen doen die je niet met Excel en JASP zou kunnen doen, zoals het analyseren van grote sequencing datasets, het uitvoeren van machine learning modellen of het bouwen van interactieve webapplicaties.
Voor R geldt verder dat het een open-source software project is waaraan heel veel mensen bijdragen en wat gratis voor iedereen beschikbaar is gemaakt. Je kunt R dan ook gratis dowloaden en installeren op je laptop. In deze cursus maken we echter gebruik van een serveromgeving, omdat dat het leren van R wat makkelijker maakt.
Wat is RStudio en hoe kun je het gebruiken?
R is een programmeertaal en als je R installeert op je computer is er niet echt programma wat je kunt openen, zoals dat bij JASP en Excel wel het geval is. Om R gebruiksvriendelijker te maken, is er een GUI (= graphical user interface) gemaakt voor R: RStudio. RStudio is dus niets meer dan een programma wat je kunt openen op je computer en waarmee je makkelijker kunt werken met R.
In de onderstaande video wordt kort besproken hoe je RStudio kunt gebruiken:
Je kunt regels in een script uitvoeren in de console door met de cursor op de regel te gaan staan en vervolgens op CTRL + ENTER te drukken. Je kunt ook meerdere regels tegelijkertijd uitvoeren, door deze regels te selecteren en vervolgens op CTRL + ENTER te drukken.
Het heeft de voorkeur om scripts te gebruiken in plaats van R code direct in de console uit te voeren. Het gebruik van scripts heeft een aantal voordelen:
- De code in het script kan worden opgeslagen, waardoor het werk wat je gedaan hebt door anderen kan worden herhaald en je de code ook met anderen kan delen.
- De code kan verduidelijkt worden door het gebruik van comments. Comments worden in het script aangegeven met een
#. Alles na een#wordt door R genegeerd. De comments zijn dus voor de analyse zelf niet belangrijk, maar ze maken het script wel leesbaar voor anderen. - In een script kun je makkelijk je code aanpassen, bijvoorbeeld als er een foutje in de code aanwezig was.
R projecten
Omdat we de verschillende analysestappen willen bijhouden, werken we met scripts. Verder maken we in RStudio gebruik van de mogelijkheid om in projecten te werken. Een project is een map waarin de data en de scripts aanwezig zijn die nodig zijn om een analyse uit te voeren. Projecten maken het dan ook heel makkelijk om resultaten uit te wisselen: een project bevat namelijk alles wat nodig is om de analyse door iemand anders te laten herhalen.
Voor elk nieuw data analyseproject wat je doet, kun je een project aanmaken in RStudio. Tijdens deze cursus zou je bijvoorbeeld voor elke les een nieuw project kunnen aanmaken.
Zodra je een project opent, bevind je je in de map van dat project. Als je R dan vraagt om data in te lezen, zal R de data proberen te zoeken in deze map. Het is dus erg belangrijk dat de projectmap niet alleen de scripts, maar ook de databestanden bevat. De map waar R gaat zoeken naar data heeft een naam: de working directory. Door een project aan te maken/te openen, wordt de working directory automatisch verandert naar de map waarin het project zich bevindt.
In de onderstaande video wordt uitgelegd hoe je een project kunt aanmaken in RStudio:
Opdracht 1
Maak nu in RStudio een project aan voor les 1 in de map met de databestanden voor les 1.
Variabelen en functies
Als je data inleest in R, krijg je niet zoals bij Excel of JASP een tabel te zien met daarin de data. In plaats daarvan wordt de data in R opgeslagen als een variabele. Een variabele is een label (een naam) waaronder een R object is opgeslagen. Het onderliggende R object laat R normaal gesproken niet zien, tenzij je dit expliciet van R vraagt.
Zodra de data in een variabele is opgeslagen, kun je functies toepassen op de variabele. Dit is vergelijkbaar met de formules die we in Excel hebben gebruikt: net als formules in Excel worden functies in R gebruikt om de data te bewerken en te analyseren. R kent heel veel verschillende functies. Een voorbeeld van een functie is de sum functie die voor een reeks getallen de som uitrekent.
In de onderstaande video wordt getoond hoe je variabelen en functies in R kunt gebruiken:
Packages
De functies in R kun je verdelen in twee groepen: ingebouwde functies en functies in packages. De ingebouwde functies zijn direct beschikbaar als je R opent. Je hoeft hier niets voor te doen. Een voorbeeld van een ingebouwde functie is de hierboven genoemde sum functie.
Sommige functies zijn niet ingebouwd in R, maar zitten in packages. Packages zijn extra modules voor R die je apart van R kunt downloaden/installeren. Deze packages zijn gemaakt om nieuwe functionaliteiten toe te voegen aan R.
Er zijn heel veel packages voor R beschikbaar. In deze cursus maken we vooral gebruik van het tidyverse package. Om een package zoals tidyverse te kunnen gebruiken, moet je het package eerst installeren. Dit hoef je maar één keer te doen. Tijdens deze cursus hoeven jullie geen packages te installeren, omdat dat al voor jullie gedaan is. Het installeren kan worden gedaan met de install.packages functie:
Verder moet je om de functies in het package te gebruiken, het package laden in R. Hiervoor gebruik je de library functie:
Een package hoeft maar één keer geïnstalleerd te worden op een computer. Wel moet je het voor elk nieuw script opnieuw laden met de library functie. Start daarom elk nieuw script met het laden van de benodigde packages.
help functies
Alle functies die je in R kunt gebruiken, zijn goed gedocumenteerd. Om de documentatie voor een bepaalde functie op te roepen, kun je in de console een vraagteken typen gevolgd door de naam van de functie. Bijvoorbeeld:
NB: De documentatie in R is niet altijd makkelijk om te begrijpen. In het begin zul je daarom misschien extra informatie moeten opzoeken op het internet of de docenten om uitleg moeten vragen. Tijdens het tentamen mag je alleen deze reader en de documentatie in R gebruiken. Het loont dus als je goed overweg kunt met deze documentatie!
Het data analyse stappenplan (korte herhaling)
In de eerdere cursus Dataverwerking (TLSC-DAVE1V-24) hebben jullie al kennisgemaakt met het data analyse stappenplan. Om je geheugen op te frissen, worden de vijf stappen hieronder kort beschreven. In deze cursus gaan we hetzelfde stappenplan gebruiken om data te analyseren met R. De stappen komen dus nog uitgebreid terug in de lessen.
Stap 1: data inlezen
- Data inlezen in R (‘de data in R krijgen’), zodat je de data met R kunt analyseren.
- Controleren of het inlezen goed is gegaan (bijv. is tekst ingelezen als tekst en zijn nummers ingelezen als nummers).
- Controleren of er missende waarden aanwezig zijn en of die correct zijn gecodeerd.
- Data omzetten naar een tidy format.
Stap 2: data inspecteren
- Wat is er gemeten? Welke variabelen zijn er? Hoeveel observaties zijn er?
- Vaststellen of er uitschieters (‘outliers’) in de data aanwezig zijn en deze outliers eventueel verwijderen.
- Vaststellen hoe de data verdeeld is (bijv. normaal verdeeld of niet).
- Controleren of de data van voldoende kwaliteit is om te gebruiken voor verdere analyses (‘quality control’).
Stap 3: data bewerken
- De dataset voorbereiden voor het beantwoorden van de onderzoeksvraag (bijv. door variabelen te filteren of nieuwe variabelen te bepalen).
Stap 4: resultaten bepalen
- De onderzoeksvraag beantwoorden in de vorm van een getal (bijv. een gemiddelde, de mediaan of de determinatiecoëfficiënt).
- De betrouwbaarheid van het antwoord uitdrukken in een getal (bijv. de standaarddeviatie of het betrouwbaarheidsinterval).
Stap 5: resultaten communiceren
- De getallen die bij de vorige stap berekend zijn grafisch weergeven in informatieve grafieken.
- De complete data analyse uitwerken in een rapport dat gemakkelijk gebruikt kan worden door andere onderzoekers om jouw bevindingen te herhalen/controleren.
Werkcollege
Aan de slag met R!
Data inlezen
Als je R wilt gebruiken om data te analyseren, moet je eerst de data in R zien te krijgen. Je moet daarvoor de data inlezen vanuit een bestand op je computer in R. Data kan zijn opgeslagen in verschillende typen bestanden. Zo kan het zijn opgeslagen als Excel bestand of als csv bestand. Hoe je data vanuit dit soort bestanden inleest in R, leer je in de volgende lessen. In deze les gaan we data inlezen vanuit RDS bestanden.
RDS bestanden inlezen
Veel softwareprogramma’s hebben specifieke bestandstypen waarin je de resultaten op kunt slaan en kunt delen met anderen. Zo heeft Excel .xlsx bestanden en JASP .jasp bestanden. Voor R is dit het .RDS bestand. Als je in R variabelen aanmaakt, kun je deze variabelen opslaan in een RDS bestand. Hiervoor gebruik je de saveRDS functie:
Het eerste argument van de saveRDS functie is de variabele die je wilt opslaan in een RDS bestand. Het tweede argument is de naam die je het RDS bestand wilt geven.
Je kunt nu het RDS bestand wat je hebt gemaakt delen met iemand anders. Die persoon kan dan het bestand inlezen in R met behulp van de readRDS functie:
De readRDS functie heeft maar één argument, namelijk de naam van het RDS bestand. Om met de inhoud van het bestand in R te kunnen werken, moet je de output van de readRDS functie opslaan in een variabele.
Kies voor variabelen informatieve namen. Houd er verder rekening mee dat de namen van variabelen vaak in snake_case format worden geschreven. Hierbij worden woorden in kleine letters geschreven en gescheiden door underscores. Bijvoorbeeld: gewichten_studenten_lifescience.
Verschillende datastructuren in R
Als je data inleest in R, wordt de data vertaald naar datastructuur waar R mee kan werken. De belangrijkste datastructuren zijn vectors, lists, dataframes en tibbles.
Vectors
Een vector is een datastructuur die bestaat uit waarden van hetzelfde datatype. We zijn al eerder een voorbeeld tegengekomen van een vector:
In dit geval is de variabele getallenreeks een voorbeeld van een vector, omdat alle waarden in deze vector integers (hele getallen) zijn. Naast integer zijn er in R nog andere datatypen, namelijk double (alle getallen die geen integer zijn), character (tekst, zoals woorden en zinnen) en logical (waarden die aangeven of iets waar of niet waar is, TRUE/FALSE).
Opdracht 1
In de map voor les 1 staan drie RDS bestanden met daarin vectoren (vector1.rds, vector2.rds en vector3.rds). Lees deze RDS bestanden in in R en bepaal voor elke vector welk data type de waarden hebben.
Klik hier voor het antwoord
Eerst lezen we de RDS bestanden in met de readRDS functie:
vector1 <- readRDS("vector1.rds")
vector2 <- readRDS("vector2.rds")
vector3 <- readRDS("vector3.rds")Daarna bepalen we voor elke vector het datatype. We kunnen hier ook de typeof functie voor gebruiken.
## [1] 1.0 2.3 5.3 6.1 6.6 0.5## [1] "double"## [1] TRUE FALSE TRUE TRUE TRUE FALSE FALSE## [1] "logical"## [1] "R" "Excel" "JASP" "Python" "Word"## [1] "character"Lists
Een list is een datastructuur die complexer is dan een vector, want de elementen in een list kunnen van verschillende datatypen zijn. Laten we kijken naar een voorbeeld:
## [[1]]
## [1] 1
##
## [[2]]
## [1] "bert"
##
## [[3]]
## [1] 1 2 3 4 5 6 7 8 9 10
##
## [[4]]
## [1] TRUEDe list list1 bestaat uit:
- een integer vector met 1 element;
- een character vector met 1 element;
- een integer vector met 10 elementen;
- en een logical vector met 1 element.
Dataframes en tibbles
Als we met data werken, werken we vaak met tabellen. Tabellen hebben rijen en kolommen. In R bestaan twee datastructuren om tabellen weer te geven. De eerste datastructuur is de dataframe. Laten we een voorbeeld bekijken:
## sample treatment weight blood_pressure cholesterol
## 1 human1 control 80 80/120 20
## 2 human2 control 82 85/110 25
## 3 human3 control 78 78/115 32
## 4 human4 50 ng/mg 76 90/125 45
## 5 human5 50 ng/mg 83 92/120 43
## 6 human6 50 ng/mg 81 87/119 NADeze dataframe bestaat uit 5 kolommen en 6 rijen. De kolommen in een dataframe zijn eigenlijk vectoren. In de output hierboven kun je ook zien welk datatype de vectoren hebben: de sample, treatment en blood_pressure kolom zijn van het datatype character en de weight en cholesterol kolom zijn van het datatype double.
Dataframes hebben een aantal technische nadelen en daarom wordt er in de nieuwere functies van R gebruik gemaakt van een andere datastructuur om tabellen weer te geven: de tibble. In de praktijk zijn er veel overeenkomsten tussen dataframes en tibbles. We zullen in deze cursus vooral werken met tibbles.
We kunnen de bovenstaande dataframe eenvoudig omzetten naar een tibble met de as_tibble functie (NB: deze functie is onderdeel van het tidyverse package en we moeten dus eerst dit package laden):
# Laad de package tidyverse
library(tidyverse)
# Zet de dataframe om naar een tibble
tibble1 <- as_tibble(dataframe1)
# Laat de inhoud van de tibble zien
tibble1## # A tibble: 6 × 5
## sample treatment weight blood_pressure cholesterol
## <chr> <chr> <dbl> <chr> <dbl>
## 1 human1 control 80 80/120 20
## 2 human2 control 82 85/110 25
## 3 human3 control 78 78/115 32
## 4 human4 50 ng/mg 76 90/125 45
## 5 human5 50 ng/mg 83 92/120 43
## 6 human6 50 ng/mg 81 87/119 NAData inspecteren
Na het inlezen van de data volgt de data inspectie. Omdat we in deze cursus voornamelijk met tibbles zullen werken, zullen we hier een aantal functies bespreken die nuttig zijn om tibbles te inspecteren.
Een aantal handige functies voor het inspecteren van tibbles zijn de volgende:
- Met de
Viewfunctie wordt de tibble in een apart window getoond. De weergave is vergelijkbaar met die van Excel:
- Met de
headentailfunctie kun je de eerste en laatste regels van de tibble bekijken:
## # A tibble: 6 × 5
## sample treatment weight blood_pressure cholesterol
## <chr> <chr> <dbl> <chr> <dbl>
## 1 human1 control 80 80/120 20
## 2 human2 control 82 85/110 25
## 3 human3 control 78 78/115 32
## 4 human4 50 ng/mg 76 90/125 45
## 5 human5 50 ng/mg 83 92/120 43
## 6 human6 50 ng/mg 81 87/119 NA## # A tibble: 6 × 5
## sample treatment weight blood_pressure cholesterol
## <chr> <chr> <dbl> <chr> <dbl>
## 1 human1 control 80 80/120 20
## 2 human2 control 82 85/110 25
## 3 human3 control 78 78/115 32
## 4 human4 50 ng/mg 76 90/125 45
## 5 human5 50 ng/mg 83 92/120 43
## 6 human6 50 ng/mg 81 87/119 NA- Met de
namesfunctie kun je de kolomnamen van een tibble bekijken:
## [1] "sample" "treatment" "weight" "blood_pressure" "cholesterol"- Met de
dimfunctie kun je de dimensies van een tibble bekijken. De dimensies van een tibble zijn het aantal rijen (eerste getal dat dedimfunctie teruggeeft) en het aantal kolommen (tweede getal dat dedimfunctie teruggeeft):
## [1] 6 5Een alternatief is om met de nrow functie het aantal rijen te bepalen en met de ncol functie het aantal kolommen:
## [1] 6## [1] 5- Met de
strfunctie kun je een een overzicht krijgen van de verschillende kolommen in de tibble (hoeveel kolommen zijn er, wat is het datatype van elke kolom, hoeveel rijen heeft elke kolom en wat zijn de eerste waarden van de kolom):
## tibble [6 × 5] (S3: tbl_df/tbl/data.frame)
## $ sample : chr [1:6] "human1" "human2" "human3" "human4" ...
## $ treatment : chr [1:6] "control" "control" "control" "50 ng/mg" ...
## $ weight : num [1:6] 80 82 78 76 83 81
## $ blood_pressure: chr [1:6] "80/120" "85/110" "78/115" "90/125" ...
## $ cholesterol : num [1:6] 20 25 32 45 43 NAOpdracht 1
De flights dataset bevat de informatie voor alle vliegtuigvluchten vanaf New York in het jaar 2013. Lees de tibble flights in in R vanuit het bestand flights.rds. Beantwoord voor deze dataset de volgende vragen:
- Hoeveel kolommen en hoeveel rijen heeft deze dataset?
- Wat zijn de kolomnamen van deze dataset?
Klik hier voor het antwoord
# Bepaal het aantal rijen en kolommen
dim(flights) # het aantal rijen gevolgd door het aantal kolommen## [1] 336776 19## [1] 336776## [1] 19## [1] "year" "month" "day" "dep_time" "sched_dep_time"
## [6] "dep_delay" "arr_time" "sched_arr_time" "arr_delay" "carrier"
## [11] "flight" "tailnum" "origin" "dest" "air_time"
## [16] "distance" "hour" "minute" "time_hour"Kolommen selecteren
Voor het uitvoeren van berekeningen wil je soms aan de slag met één enkele kolom uit de tibble. Je kunt dit doen door de gewenste kolom te selecteren met een $ teken:
Omdat een kolom in een tibble in wezen een vector is, zal de variabele gewicht een vector zijn.
Resultaten bepalen
Om onderzoeksvragen te beantwoorden heb je vaak beschrijvende statistiek nodig. In R zijn hiervoor veel verschillende functies aanwezig. Hier volgen een aantal voorbeelden:
- Met de
meanfunctie kun je het gemiddelde berekenen van een vector:
## [1] 80- Met de
medianfunctie kun je de mediaan van een vector bepalen:
## [1] 80.5- Met de
minen demaxfuncties kunnen we het minimum en het maximum bepalen:
## [1] 76## [1] 83- Met de
summaryfunctie kun je in één keer het minimum, het maximum, het gemiddelde en de mediaan bepalen. Daarnaast geeft het ook het eerste en derde kwartiel:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 76.00 78.50 80.50 80.00 81.75 83.00- Met de
sdfunctie kun je de standaarddeviatie uitrekenen:
## [1] 2.607681Ontbrekende (NA) waarden
Soms bevatten kolommen ontbrekende waarden. In R worden deze waarden weergegeven met NA waarden. Zo bevat de cholesterol kolom een NA waarde:
## [1] 20 25 32 45 43 NAOm snel te kunnen zien hoeveel NA waarden een kolom bevat kunnen we de summary functie gebruiken:
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 20 25 32 33 43 45 1Door de aanwezigheid van NA waarden is het niet mogelijk om bijvoorbeeld de mediaan of de mean te bepalen. De NA waarden zorgen ervoor dat de uitkomst NA wordt:
## [1] NA## [1] NAHoe je het beste met ontbrekende waarden om kunt gaan is iets wat buiten de leerdoelen van deze cursus valt. Een mogelijkheid die we hier gaan gebruiken is het negeren van de NA waarden voor de berekeningen. Veel functies hebben hiervoor een apart na.rm argument:
# Bepaal het gemiddelde van de cholesterolkolom en
# laat hierbij NA waarden buiten beschouwing
mean(tibble1$cholesterol, na.rm = TRUE)## [1] 33# Bepaal de mediaan van de cholesterolkolom en
# laat hierbij NA waarden buiten beschouwing
median(tibble1$cholesterol, na.rm = TRUE)## [1] 32Opdracht 1
Voor deze vraag gebruiken we de flights dataset uit de vorige vraag. Beantwoord voor deze dataset de volgende vragen:
- Hoeveel NA waarden zijn er aanwezig in de kolom
dep_delay? - Wat is het gemiddelde van de
dep_delaykolom?
Resultaten communiceren
Met R kun je mooie grafieken van je data maken. In de volgende lessen komen we hier nog uitgebreid op terug. Hier laten we een paar snelle manieren zien om grafieken te maken van je data:
- Met de
plotfunctie kunnen we scatter plots maken:
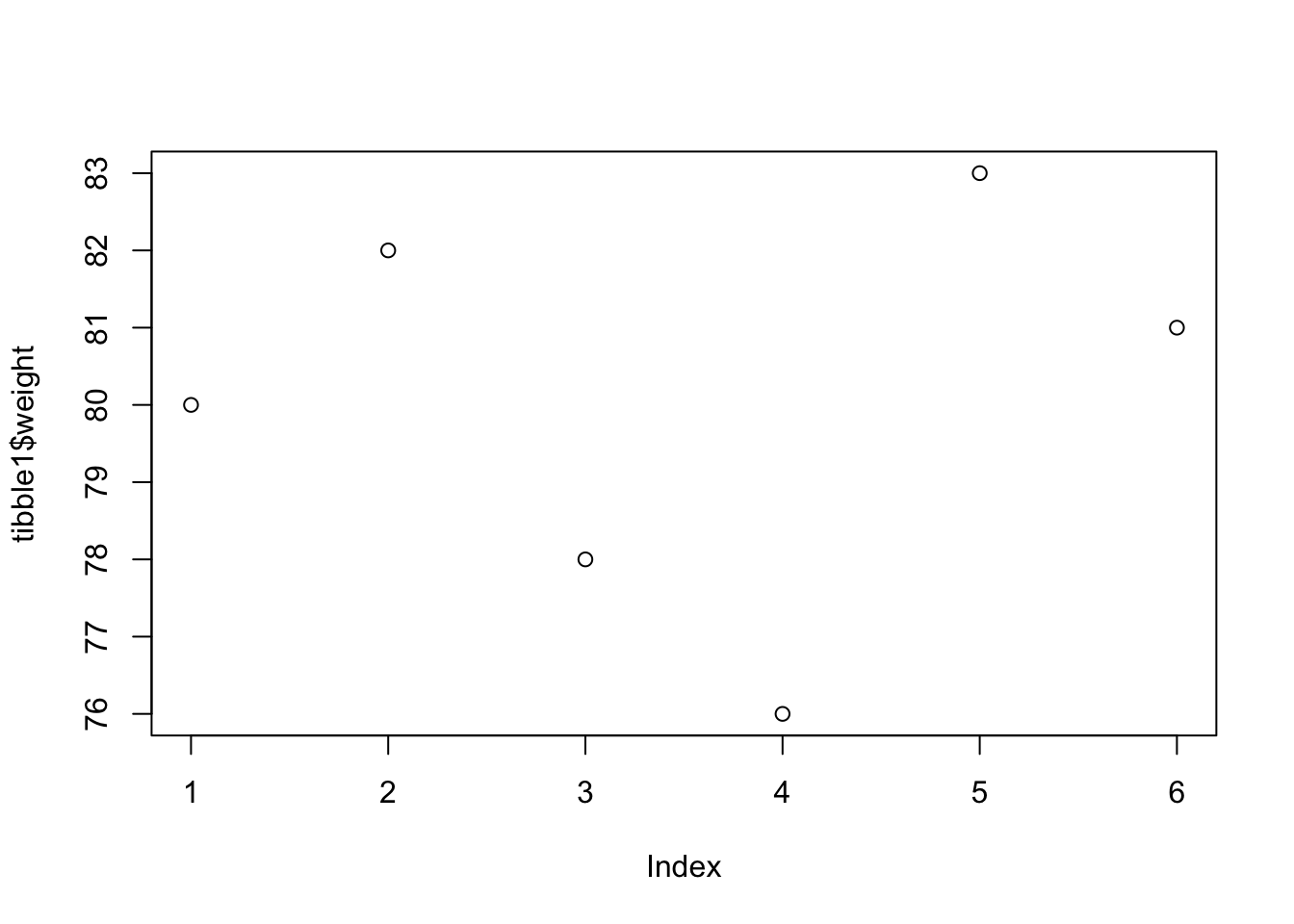
# Maak een scatter plot waarin het gewicht wordt uitgezet tegen
# het cholesterolgehalte in het bloed
plot(tibble1$weight, tibble1$cholesterol)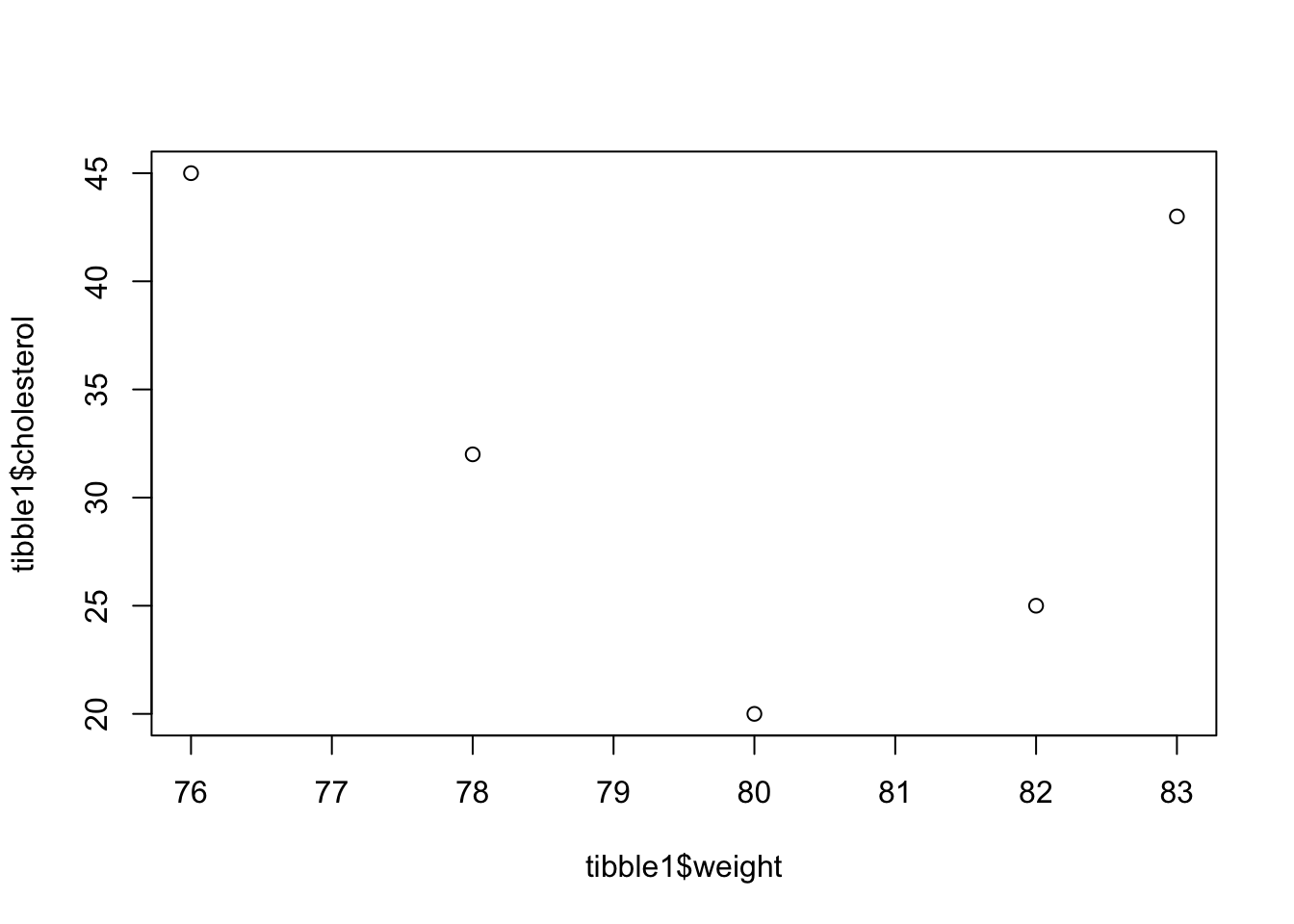
- Met de
histfunctie kun je histogrammen maken voor een bepaalde kolom:
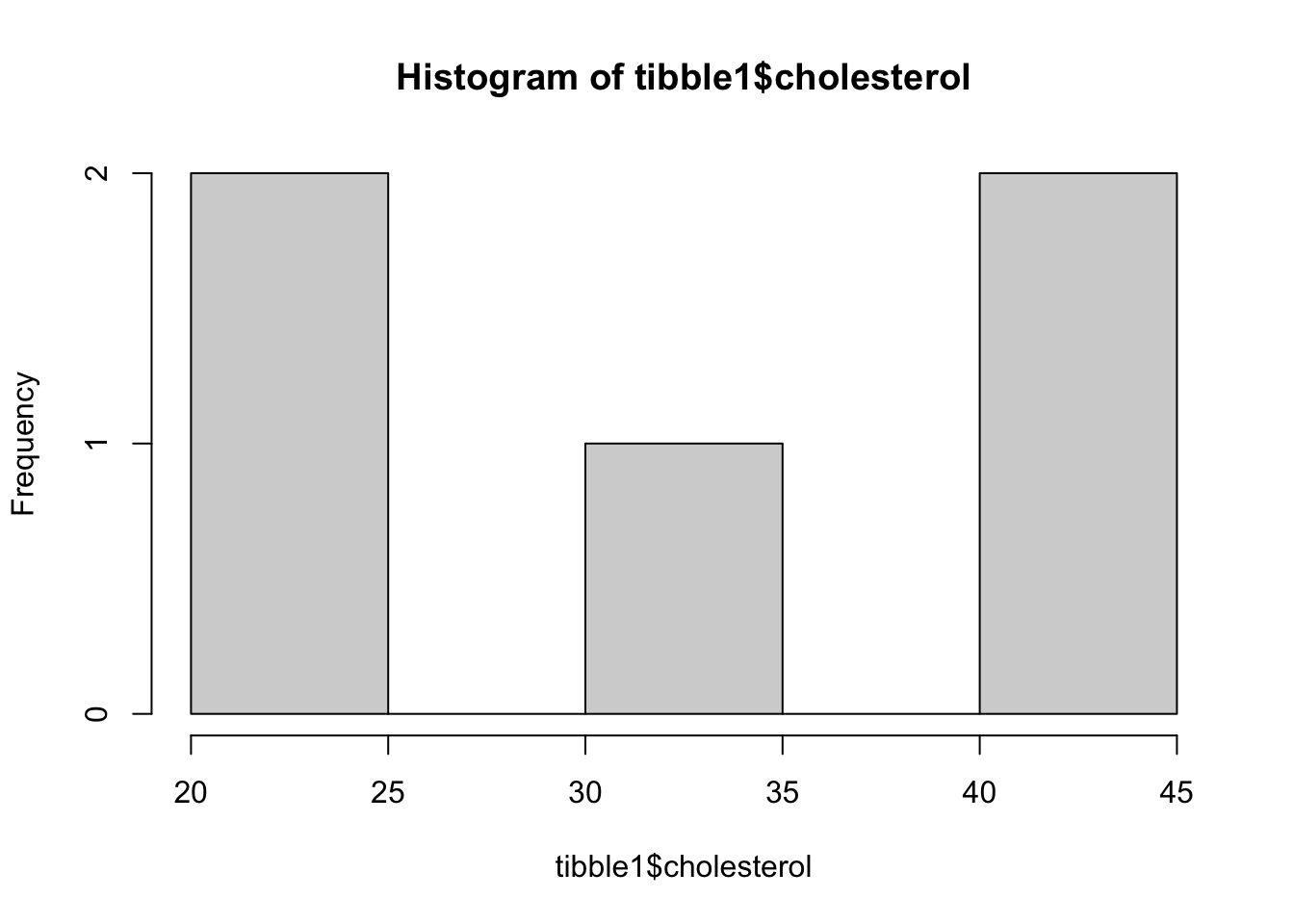
- Met de
boxplotfunctie kun je boxplots maken:
# Maak een boxplot voor het cholesterolgehalte waarbij je de data opsplitst
# op basis van de behandelingsgroep
boxplot(tibble1$cholesterol ~ tibble1$treatment)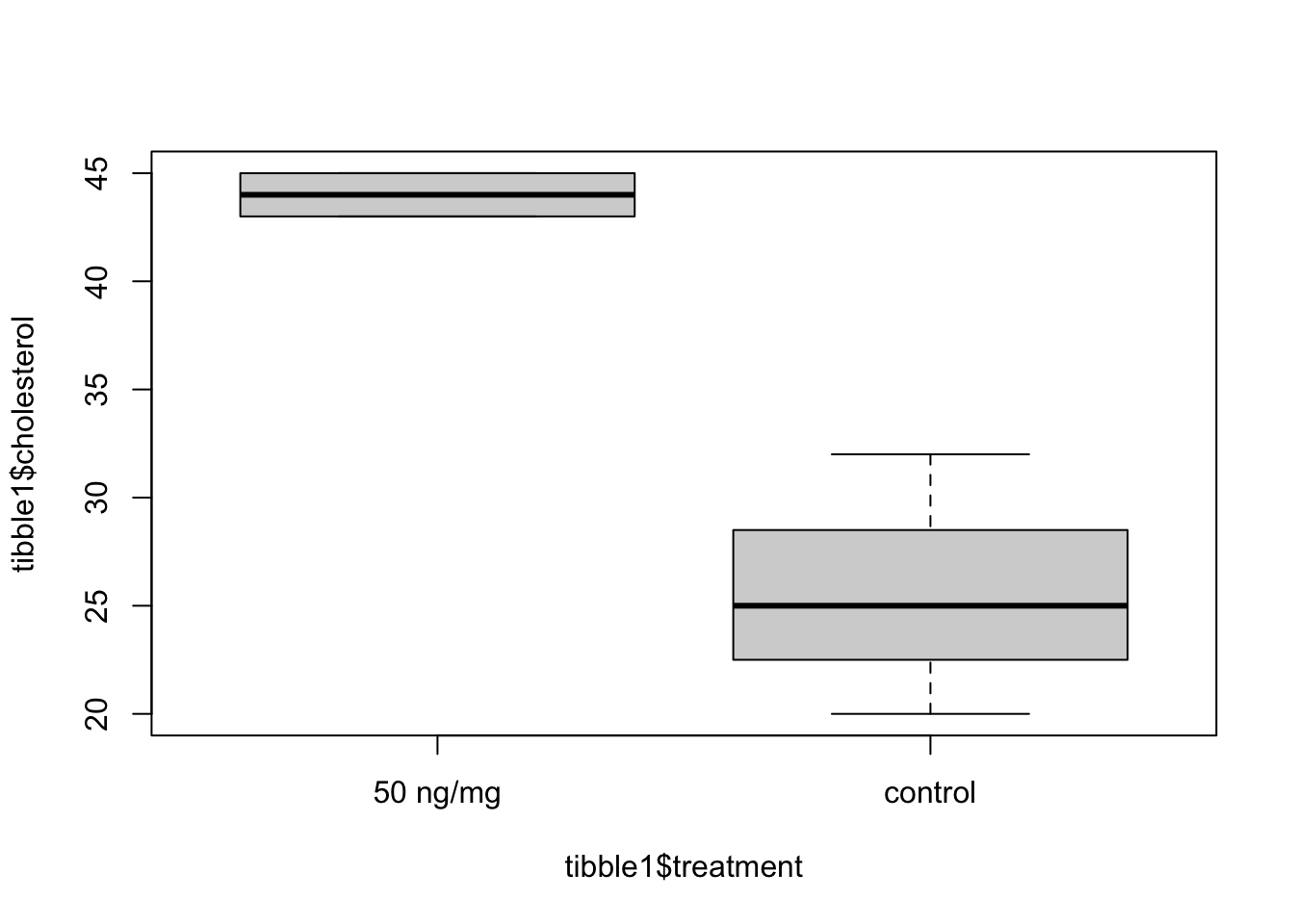
Opdracht 1
Voor deze vraag gebruiken we de flights dataset uit de vorige vraag.
We vragen ons af of er een verband is tussen de vertraging bij vertrek (
dep_delay) en de vertraging bij aankomst (arr_delay). Maak voor het beantwoorden van deze vraag een geschikte plot.We willen weten of er verschillen in de vertraging bij vertrek (
dep_delay) zijn tussen de verschillende maanden van het jaar (month). Maak voor het beantwoorden van deze vraag een geschikte plot.
Klik hier voor het antwoord
# Bepaal of er een verband is tussen de vertraging bij vertrek en
# de vertraging bij aankomst m.b.v. een scatter plot
plot(flights$dep_delay, flights$arr_delay)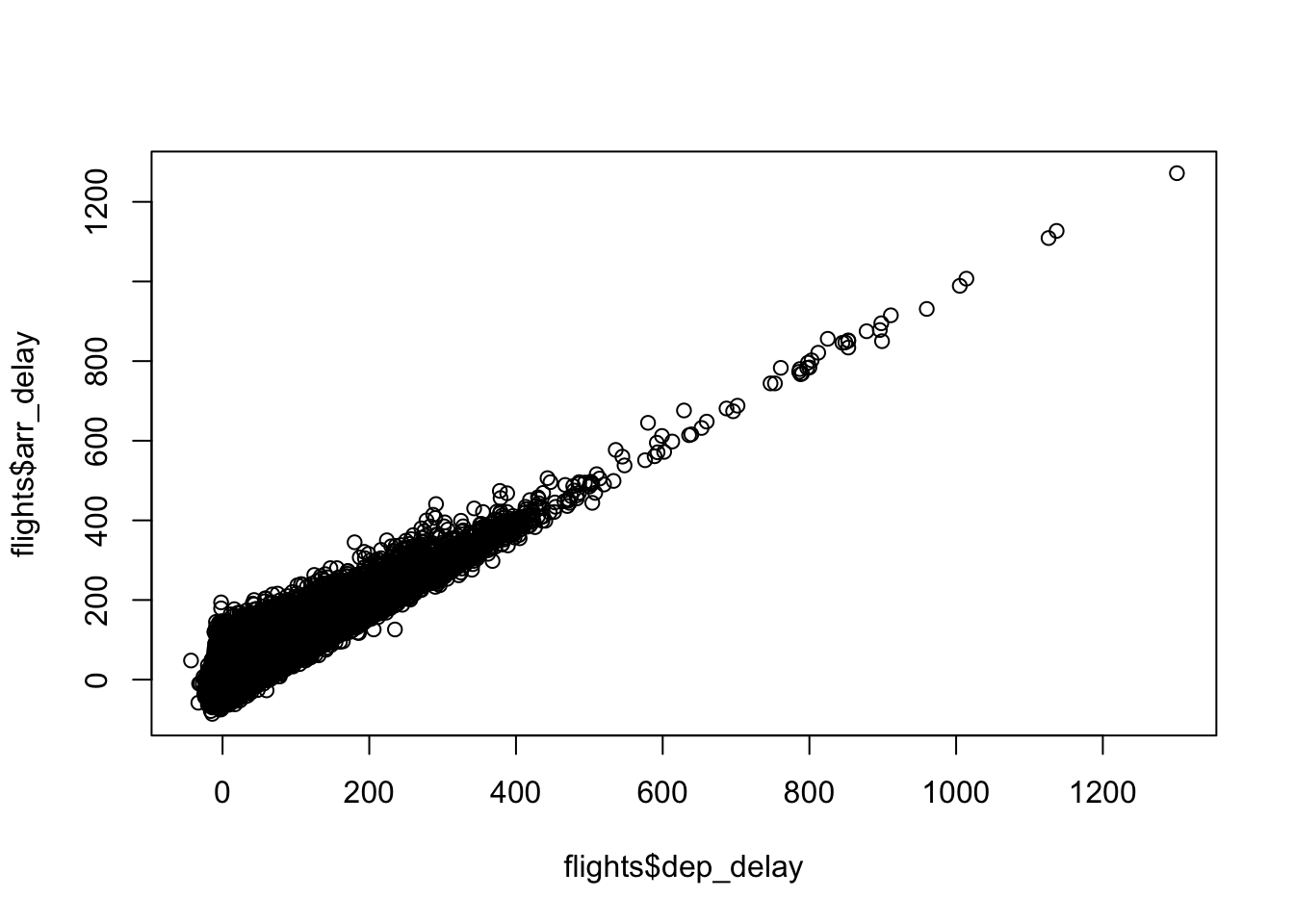
Er lijkt een sterk verband te zijn tussen de vertraging bij vertrek en de vertraging bij aankomst.
# Bepaal of er verschillen zijn in vertraging bij vertrek tussen de
# verschillende maanden m.b.v. een boxplot
boxplot(flights$dep_delay ~ flights$month)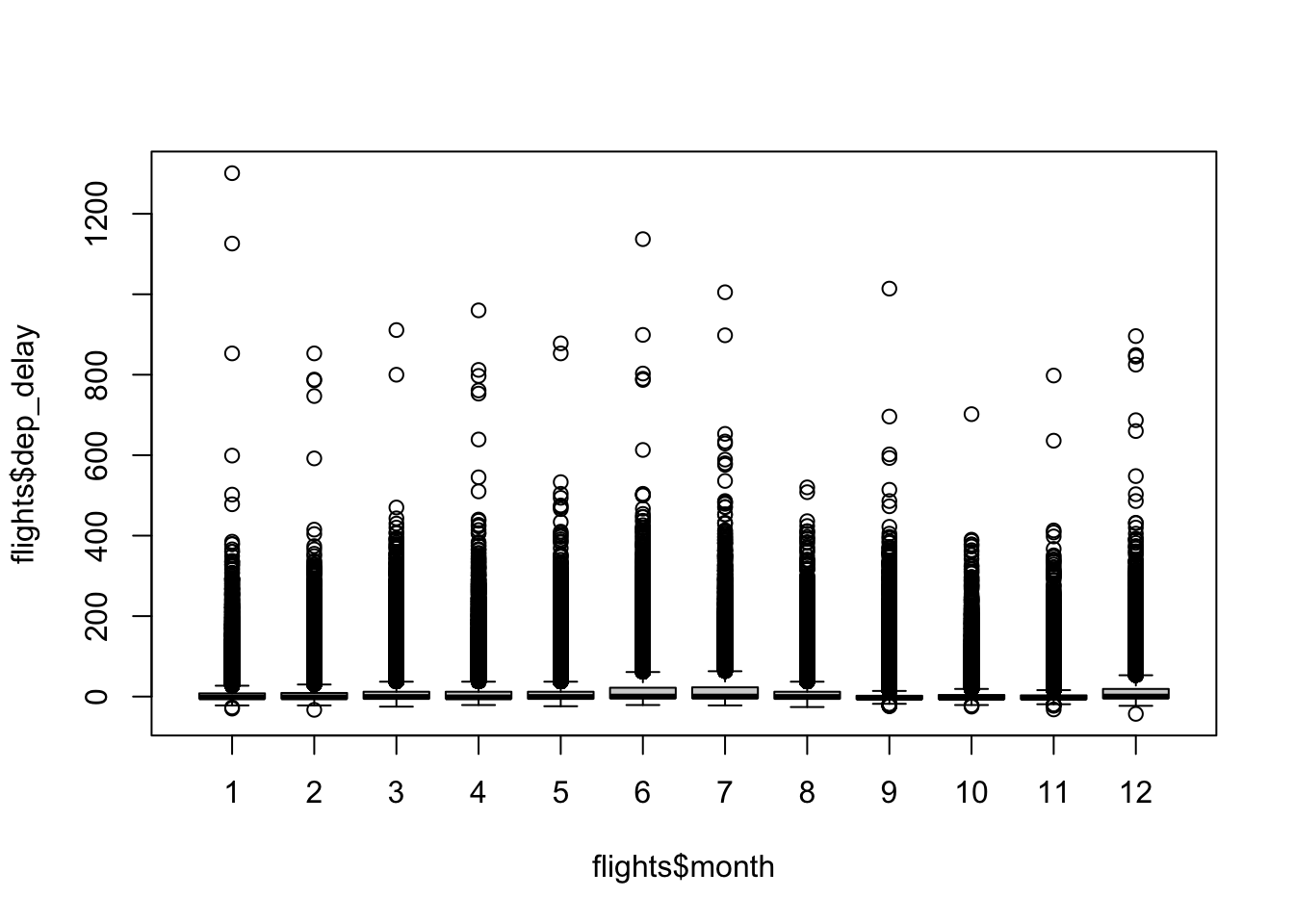
Casus Les 1
In deze casus gaan we kijken naar een dataset met bloemafmetingen. De dataset is te vinden in het bestand casus_les01.rds. De dataset bevat voor verschillende soorten irissen de bloemafmetingen: de lengtes en de breedtes van de kelkbladen (sepals) en kroonbladen (petals) in centimeter.

In deze casus willen we de volgende onderzoeksvraag beantwoorden:
- Is er een verschil in kroonbladlengte tussen de verschillende iris soorten?
Voer de onderstaande stappen van het data analyse stappenplan uit om deze onderzoeksvraag te beantwoorden. Verwerk alle gebruikte R code in een script en geef in dit script de gevonden resultaten/conclusies weer als comments.
Voorbereiding
Open een nieuw script voor je analyses en zorg ervoor dat dit script comments bevat die de stappen in het script beschrijven/toelichten.
Data inlezen
Laad de packages die je wilt gebruiken en lees de data in in R.
Data inspecteren
- Bepaal hoeveel rijen en kolommen de dataset heeft.
- Bekijk de inhoud van de verschillende kolommen en bedenk welke meting elke kolom bevat.
Resultaten communiceren
- Maak een grafiek om de onderzoeksvraag te beantwoorden.
- Trek een conclusie en beantwoord de onderzoeksvragen.
Extra opdrachten (voor als er tijd is)
De onderzoekers hebben nog een aantal andere onderzoeksvragen:
- Tussen welke lengtes variëren de kroonbladen? Hoe kort zijn de kortste kroonbladen en hoe lang zijn de langste kroonbladen?
- Is er een verband tussen de lengte en breedte van de kroonbladen?
- Is er een verband tussen de lengte en breedte van de kelkbladen?
Voer de onderstaande stappen van het data analyse stappenplan uit om deze onderzoeksvragen te beantwoorden. Verwerk alle gebruikte R code in het script wat je eerder voor deze casus hebt gemaakt, en geef in het script de gevonden resultaten/conclusies weer als comments.
Resultaten bepalen
- Bepaal of er ontbrekende (NA) waarden in de dataset aanwezig zijn.
- Bepaal de variatie in kroonbladlengte. Wat is de kleinste kroonbladlengte en wat is de grootste kroonbladlengte.
Resultaten communiceren
- Maak grafieken om de onderzoeksvragen te beantwoorden.
- Trek conclusies en beantwoord de onderzoeksvragen.