Les 2
Leeruitkomsten
- De student kan tab-separated values (TSV) bestanden inlezen in R.
- De student kan verschillende grafieken (scatter plots, histogrammen en boxplots) maken met het
ggplot2package. - De student kan
ggplot2grafieken voorzien van een duidelijke titel en informatieve aslabels. - De student kan variabelen omzetten naar een factor om aan te geven dat het een categorische variabele is.
Voorbereiding
Opdracht 2
De vorige les heb je geleerd om R projecten te gebruiken. Voor deze cursus is het handig om voor elke les een apart project te maken. Maak dus een nieuw R project aan voor les 2.
Data inlezen
In les 1 heb je geleerd hoe je variabelen (= data) kunt opslaan als RDS bestand en hoe je deze bestanden ook weer in kunt lezen in R. Vaak is het zo dat de data niet beschikbaar is als een RDS bestand, maar als een tekstbestand of een Excelbestand. In de komende lessen ga je leren hoe je de verschillende typen bestanden kunt inlezen in R. In deze les ga je leren hoe je tab-separated values (TSV) files kunt inlezen in R. Daarvoor is het wel van belang dat je kunt bepalen of de file die je wilt openen inderdaad een TSV file is, of dat het misschien een ander type file is.
Het scheidingsteken bepalen
Om erachter te komen met wat voor type databestand je te maken hebt, kun je naar de file extensie kijken. Voor Excel bestanden geldt bijvoorbeeld dat ze altijd eindigen op .xls of .xlsx. Maar voor veel tekstbestanden is dit niet zo duidelijk. Voor TSV bestanden geldt bijvoorbeeld dat ze kunnen eindigen op .tsv (wat specifiek is voor TSV bestanden), maar ook op .txt (wat ook gebruikt kan worden voor andere typen tekstbestanden).
Om er zeker van te zijn dat je te maken hebt met een TSV bestand, moet je dit bestand eerst in RStudio bekijken. In de onderstaande video wordt uitgelegd hoe je dat kunt doen:
Tab-separated values (TSV) files inlezen
Nu we weten dat het bestand iris.txt een TSV file is, kunnen we het inlezen in R. We gebruiken hiervoor de read_tsv functie. Deze functie is onderdeel van het tidyverse package, dus dit package moet eerst geladen worden met de library functie.
## Rows: 150 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (1): Species
## dbl (4): Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.De read_tsv functie leest het TSV bestand in in R en maakt er een tibble van:
## # A tibble: 150 × 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ℹ 140 more rowsOpdracht 2
Lees het bestand heights.txt in in R. Beantwoord voor dit bestand de volgende vragen:
- Hoeveel rijen en hoeveel kolommen heeft dit bestand?
- Bevat de data NA waarden?
- Wat is het laagste en het hoogste salaris (
earn) in de dataset? - Wat is de gemiddelde lengte (
height) in de dataset?
Klik hier voor het antwoord
## Rows: 1192 Columns: 6
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (2): sex, race
## dbl (4): earn, height, ed, age
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Het aantal rijen en kolommen kun je bepalen met de dim functie of de nrow en ncol functies.
## [1] 1192 6## [1] 1192## [1] 6Met de summary functie kun je bepalen of de data NA waarden bevat:
## earn height sex ed age race
## Min. : 200 Min. :57.50 Length:1192 Min. : 3.0 Min. :18.00 Length:1192
## 1st Qu.: 10000 1st Qu.:64.01 Class :character 1st Qu.:12.0 1st Qu.:29.00 Class :character
## Median : 20000 Median :66.45 Mode :character Median :13.0 Median :38.00 Mode :character
## Mean : 23155 Mean :66.92 Mean :13.5 Mean :41.38
## 3rd Qu.: 30000 3rd Qu.:69.85 3rd Qu.:16.0 3rd Qu.:51.00
## Max. :200000 Max. :77.05 Max. :18.0 Max. :91.00Er zijn dus geen NA waarden aanwezig. In de output van de summary functie is ook te zien dat het laagste salaris 200 is en het hoogste 200000. Je kunt dit ook bepalen met de min en max functies:
## [1] 200## [1] 2e+05De gemiddelde lengte kun je bepalen met de mean functie:
## [1] 66.91515Controleren of de data goed is ingelezen
Het is altijd belangrijk om te controleren of R het bestand inderdaad goed heeft ingelezen. We kunnen dit doen door het tekstbestand te openen in RStudio door op de file te klikken (zie de video hierboven). Je kunt nu kijken of de waarden die in de kolommen staan overeen komen met de waarden die in de tibble zichtbaar zijn.
Voor de iris.txt file is het inlezen goed gegaan. R heeft de eerste vier kolommen ingelezen als kommagetallen en de laatste kolom als tekstwaarden. In de onderstaande video bekijken we een bestand (heights_komma.txt) waar het inlezen niet goed gaat en laten we zien wat je eraan kunt doen:
Controleer altijd of de data goed is ingelezen in R. Vergelijk hiervoor de output in R met het originele bestand door dit bestand in RStudio te openen.
Als er sprake is van een Nederlandse dataset, waarbij de komma als decimaalscheidingsteken wordt gebruikt, dan moet je deze informatie aan R geven om de data goed in te lezen. Dit doe je door gebruik te maken van het locale argument in de read_tsv functie. Bijvoorbeeld:
Resultaten communiceren
In de vorige les hebben we gezien hoe je met een aantal eenvoudige functies grafieken kunt maken in R. Nadeel van deze grafieken is dat ze er niet zo mooi uit zien. Vandaar dat je in de komende lessen gaat leren hoe je grafieken kunt maken met het ggplot2 package. Dit package is onderdeel van het tidyverse package en hoef je dus niet apart te laden als je het tidyverse package al geladen hebt. In deze les ga je leren hoe je met ggplot2 scatter plots, histogrammen en boxplots kunt maken. Als voorbeelddata gebruiken we het bestand iris.txt wat we hierboven al hebben ingelezen.
Scatter plots
Als we willen weten of er een verband is tussen twee variabelen, dan kunnen we hiervoor een scatter plot maken. Stel dat we willen weten of er een verband is tussen de lengte van de kroonbladen (Petal.Length) en de lengte van de kelkbladen (Sepal.Length). We kunnen hiervoor een scatter plot maken met ggplot2:
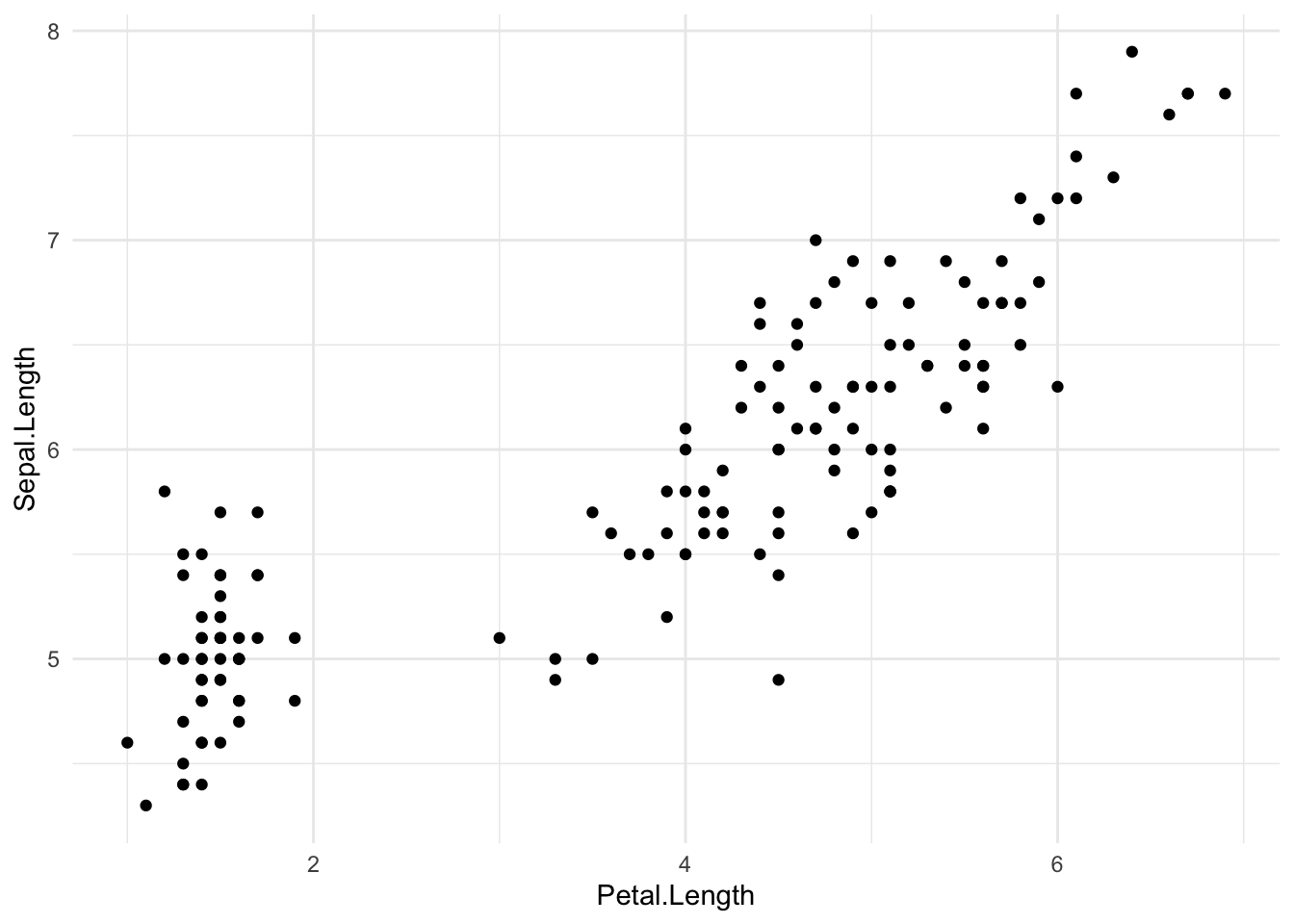
In de bovenstaande code vallen een aantal dingen op:
- De R code voor het maken van een grafiek bestaat uit verschillende onderdelen die worden gescheiden door een
+teken. - In het eerste onderdeel van de code (de eerste regel) wordt de
ggplotfunctie aangeroepen. In deze functie moeten we aangeven welke data gebruikt moet worden voor de grafiek en wat de x en y variabelen zijn. De x en y variabelen moeten worden gedefinieerd in deaesfunctie (zie code hierboven). - In het tweede onderdeel van de code (de tweede regel) wordt aangegeven wat voor type grafiek we willen maken. In dit geval is dat een scatter plot en daarvoor gebruiken we de
geom_pointfunctie. - Als laatste (de derde regel) geven we een algemene stijl/layout mee aan de grafiek met de functie
theme_minimal. Naast deze functie zijn er nog meer stijlfuncties die allemaal beginnen mettheme_.
Opdracht 2
Lees het bestand penguins.txt in in R. Deze data bevat meetwaarden voor verschillende soorten pinguins.
Bepaal met een scatter plot of er een verband is tussen de lengte van de flippers (flipper_length_mm) en het lichaamsgewicht (body_mass_g).
Klik hier voor het antwoord
## Rows: 344 Columns: 8
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (3): species, island, sex
## dbl (5): bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g, year
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# Maak een scatter plot waarin je het lichaamsgewicht uitzet tegen
# de lengte van de flippers
ggplot(data = pinguin, aes(x = body_mass_g, y = flipper_length_mm)) +
geom_point() +
theme_minimal()## Warning: Removed 2 rows containing missing values or values outside the scale range (`geom_point()`).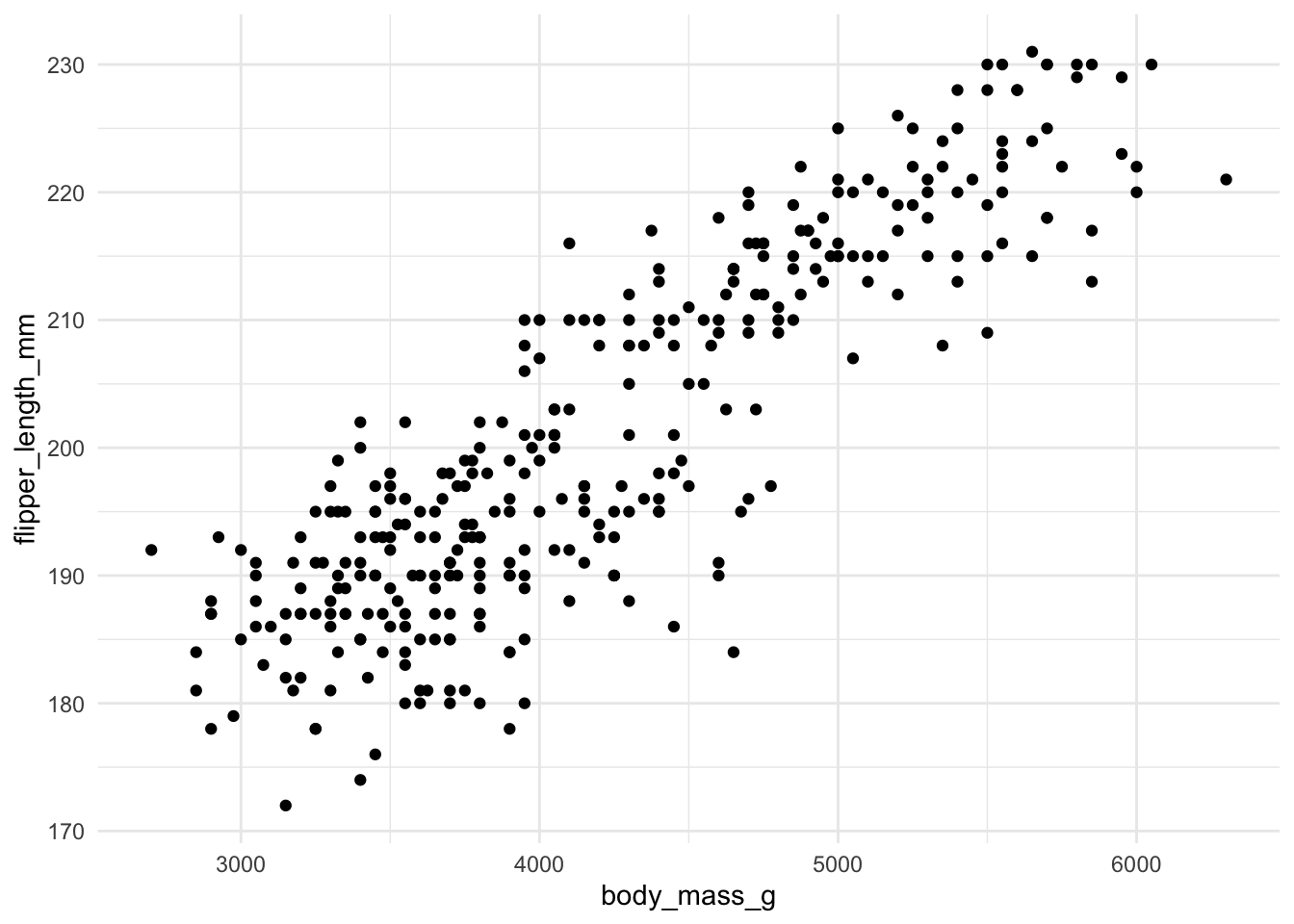
We kunnen de bovenstaande scatter plot nog informatiever maken door de punten in de scatter plot te kleuren op basis van het soort iris. Hierdoor kunnen we in een keer zien of de verschillende irissoorten ook verschillende kroon- en kelkbladlengtes hebben. Omdat je de punten wilt kleuren op basis van een variabele is het belangrijk dat je dit aangeeft binnen de aes functie:
ggplot(data = irisdata,
aes(x = Petal.Length, y = Sepal.Length, colour = Species)) +
geom_point() +
theme_minimal()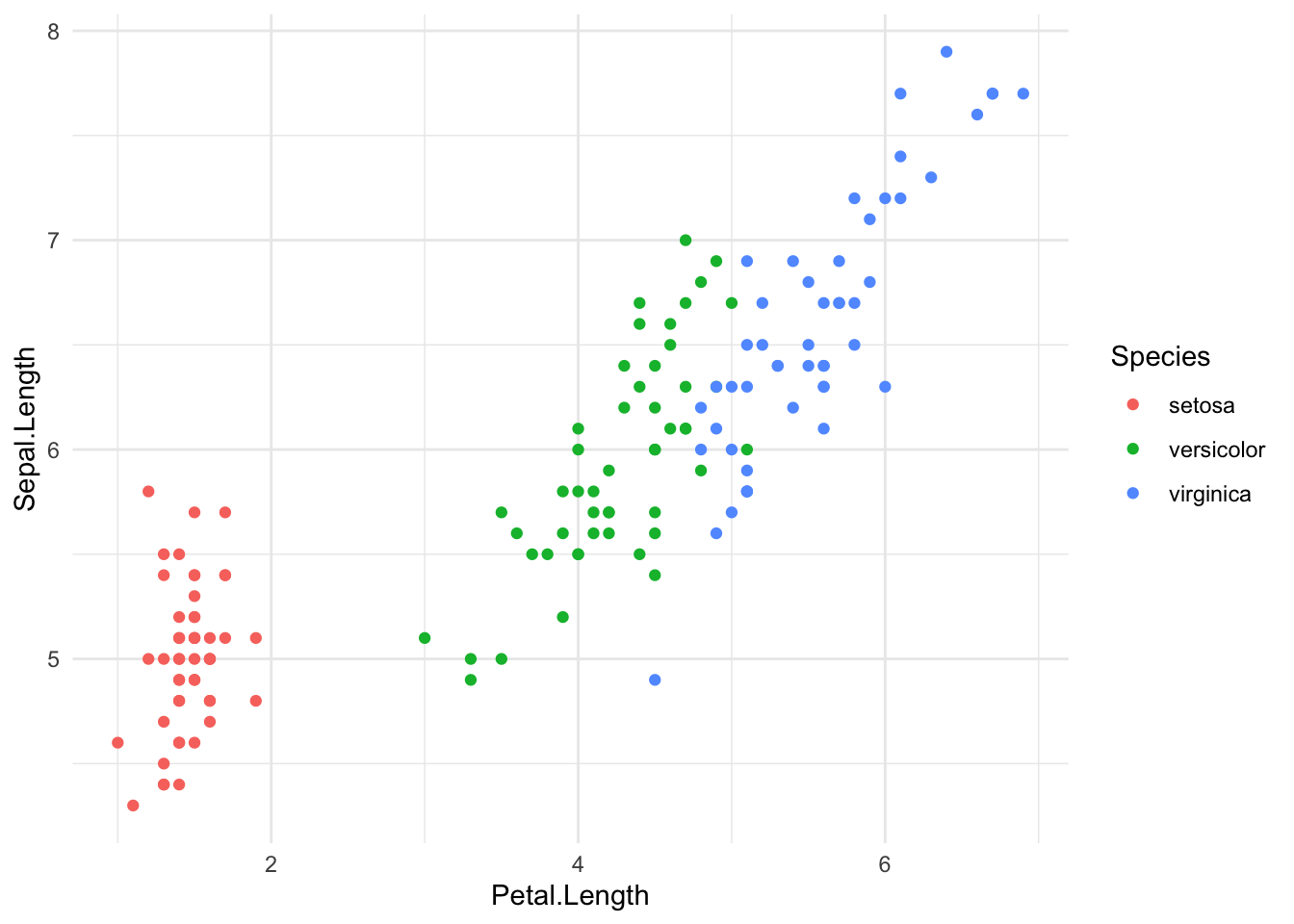
Histogrammen
Om te zien hoe een bepaalde variabele verdeeld is (bijvoorbeeld normaal verdeeld of bimodaal), kunnen we een histogram maken van die variabele. Als voorbeeld maken we een histogram voor de kelkbladlengtes (Sepal.Length):
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.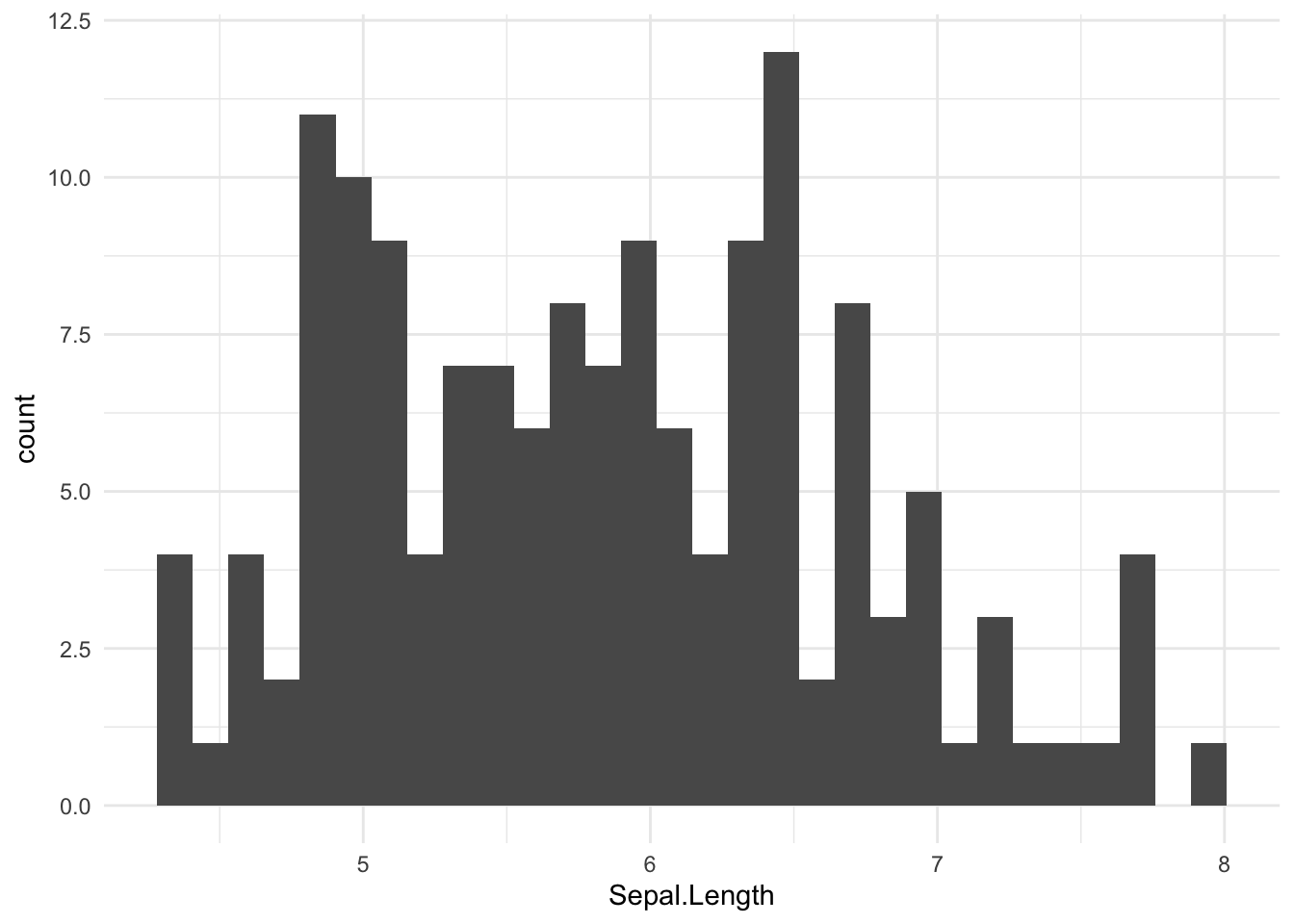
De R code om een histogram te maken is vergelijkbaar met de R code voor scatter plots. Er zijn twee verschillen:
- In plaats van de
geom_pointfunctie gebruiken we degeom_histogramfunctie om een histogram te maken. - De
geom_histogramfunctie accepteert alleen een x-variabele (in dit gevalx = Sepal.Length) binnen deaesfunctie. Degeom_histogramtelt vervolgens hoe vaak de waarden van de x-variable vallen binnen een bepaald bereik. Dit bereik wordt een bin genoemd en wordt automatisch ingesteld door degeom_histogramfunctie (in dit geval zijn er 30 bins). Het aantal waarnemingen per bin wordt geplot als y-variabele.
Opdracht 2
Maak voor deze vraag gebruik van de pinguindata die je hiervoor hebt ingelezen.
Maak een histogram voor de snavellengte (bill_length_mm) van de pinguins.
Klik hier voor het antwoord
# Maak een histogram van de snavellengte
ggplot(data = pinguin, aes(x = bill_length_mm)) +
geom_histogram() +
theme_minimal()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 2 rows containing non-finite outside the scale range (`stat_bin()`).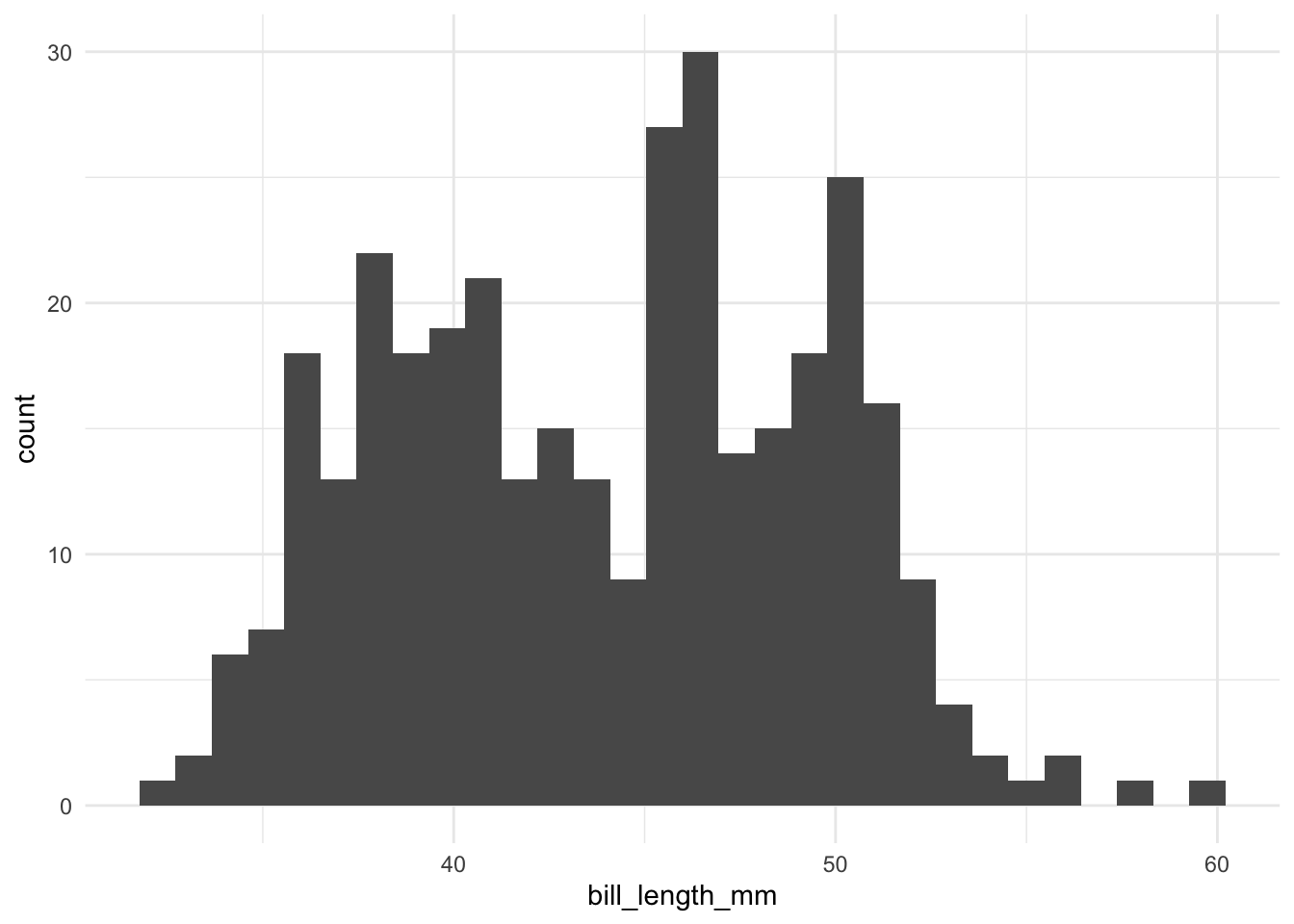
Boxplots
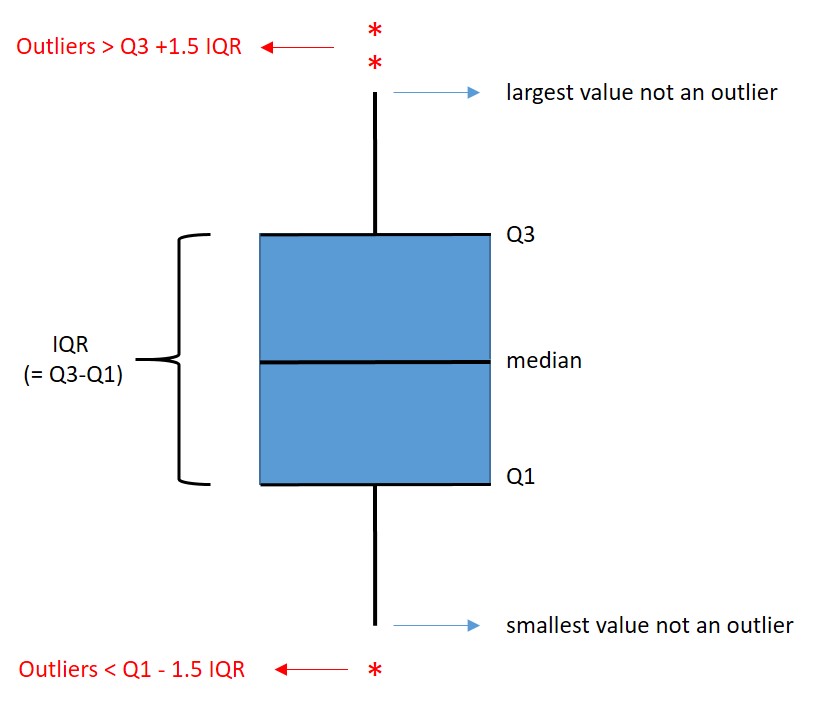
De verdeling van een variabele kunnen we niet alleen weergeven met een histogram, maar ook met een boxplot. Een boxplot bestaat uit verschillende onderdelen (zie het figuur hieronder). Zo zijn de kwartielen (Q1, Q2/mediaan, Q3) weergegeven als horizontale streepjes. De kwartielen worden bepaald door alle datapunten op volgorde te zetten en vervolgens de datapunten te verdelen in vier gelijke groepen met elk 25% van de data. De hoogste waarde van de laagste 25% datapunten is Q1. De hoogste waarde van de laagste 50% datapunten is de mediaan, oftewel Q2. En de hoogste waarde van de laagste 75% datapunten is Q3.
Ook zijn in boxplots de uitschieters weergegeven. R bepaalt deze waarden in verschillende stappen. Eerst rekent R het verschil uit tussen het derde kwartiel (Q3) en het eerste kwartiel (Q1), de zogenaamde interkwartielafstand (in het Engels afgekort als IQR). Een uitschieter is gedefinieerd als een datapunt dat meer dan 1.5xIQR weg ligt van Q1 of meer dan 1.5xIQR weg ligt van Q3.
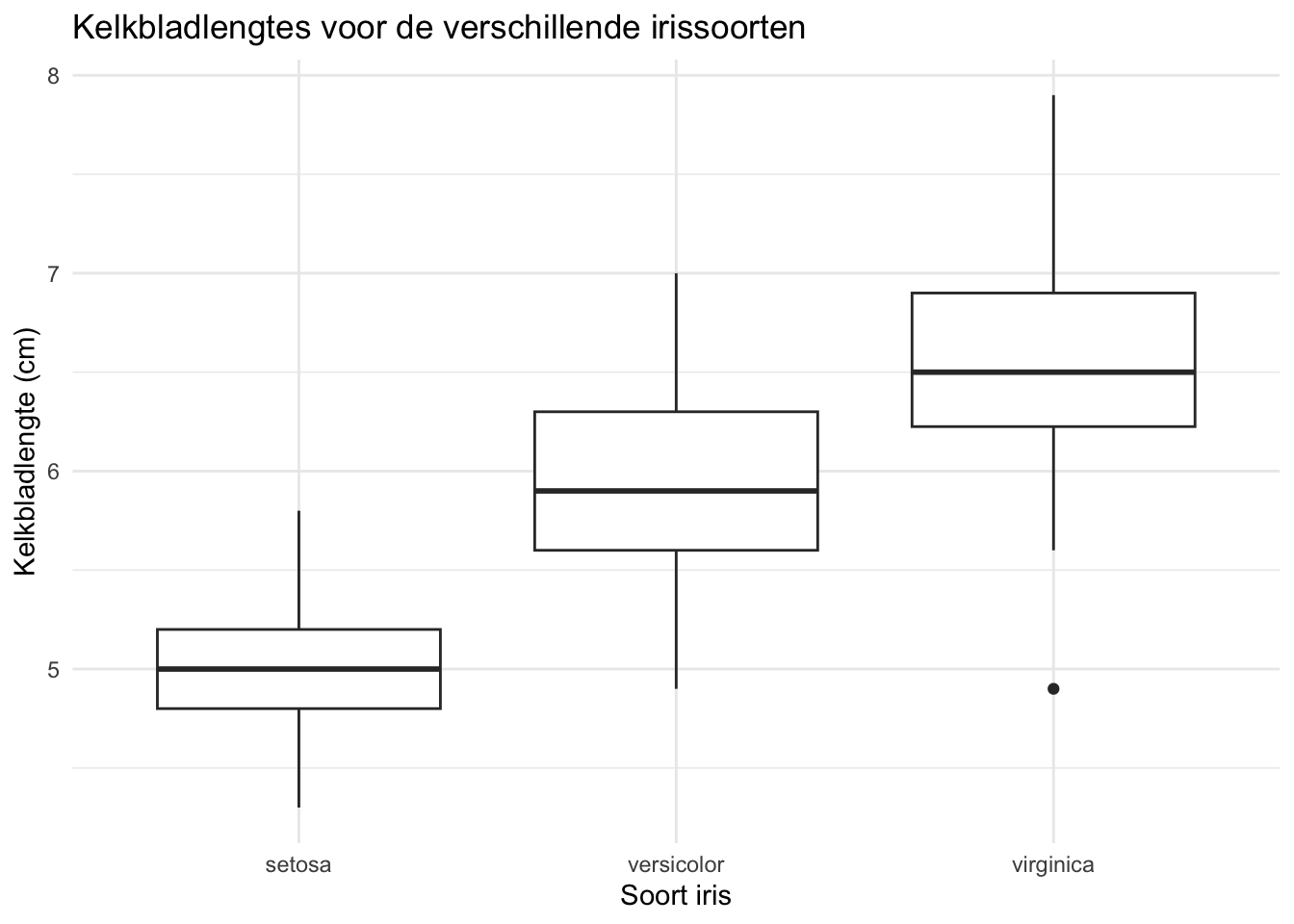
Als voorbeeld maken we een boxplot voor de kelkbladlengtes van de verschillende irissoorten:
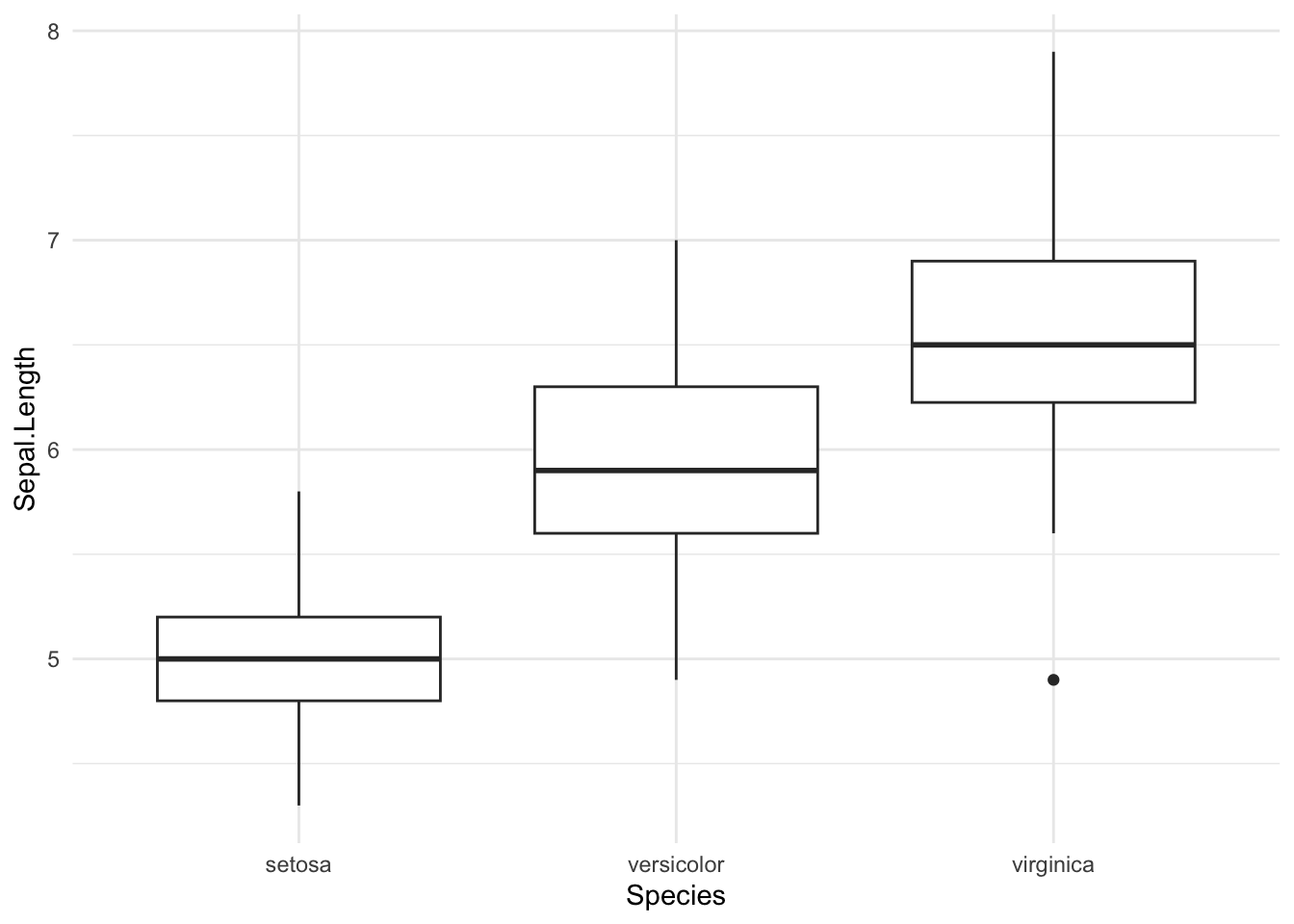
Een aantal opmerkingen bij deze grafiek:
- Om een boxplot te maken gebruiken we de functie
geom_boxplot. - Met de
x = Specieswordt aangegeven welke groepen op de x-as van de boxplot weergegeven moeten worden (in dit geval de irissoorten). - Met de
y = Sepal.Lengthwordt aangegeven op welke meetgegevens de boxplot is gebaseerd (in dit geval de kelkbladlengtes). - In de bovenstaande boxplot is één uitschieter weergegeven als een punt onder de boxplot van de soort
virginica.
De weergave van outliers kan ook worden aangepast. Dit kun je doen door extra argumenten te gebruiken in de geom_boxplot functie:
ggplot(data = irisdata, aes(x = Species, y = Sepal.Length)) +
geom_boxplot(outlier.colour = "red", outlier.shape = 8) +
theme_minimal()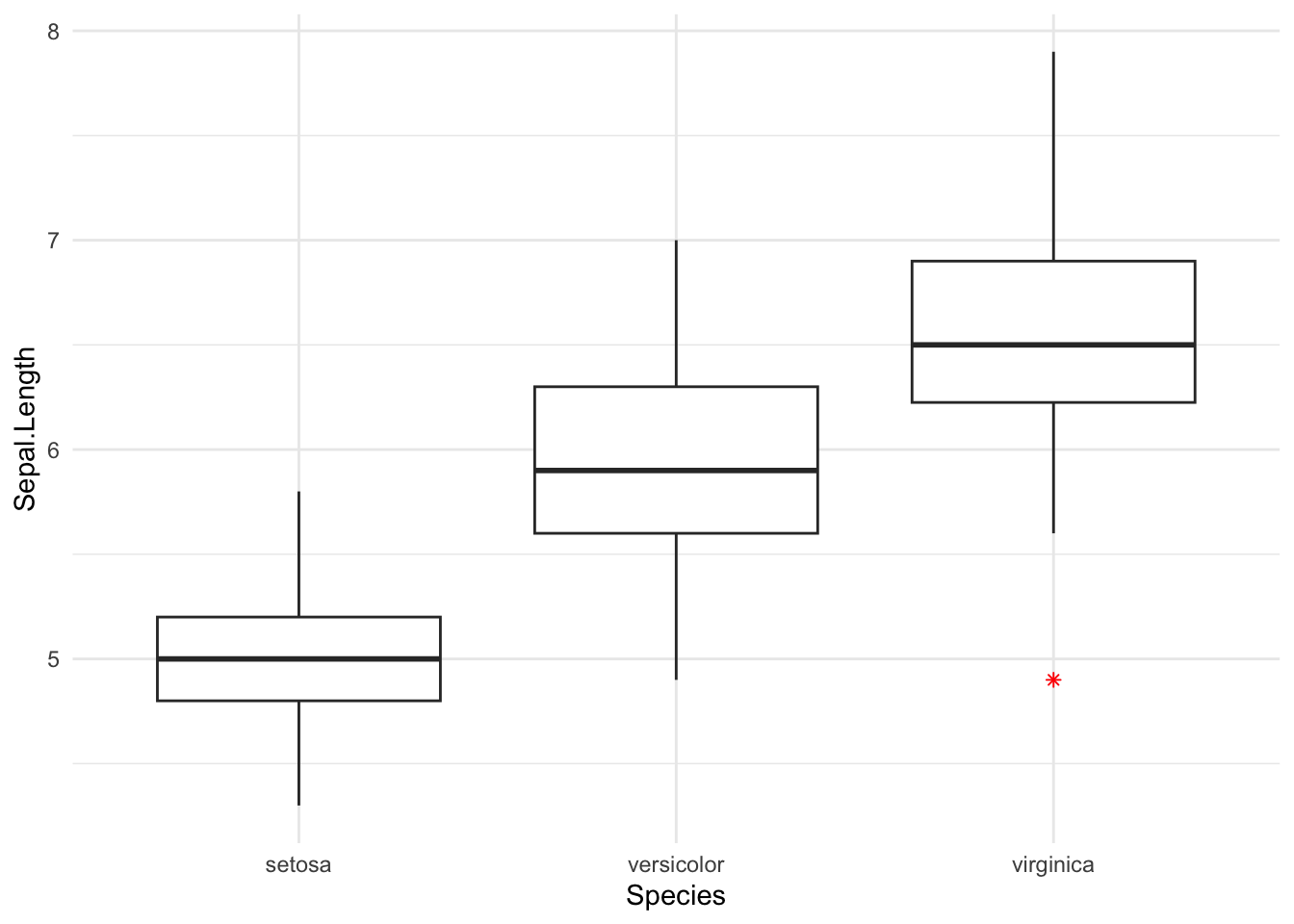
Opdracht 2
Maak voor deze vraag gebruik van de pinguindata die je hiervoor hebt ingelezen.
Maak een boxplot waarin de flipperlengte (flipper_length_mm) wordt uitgezet voor de verschillende pinguinsoorten (species).
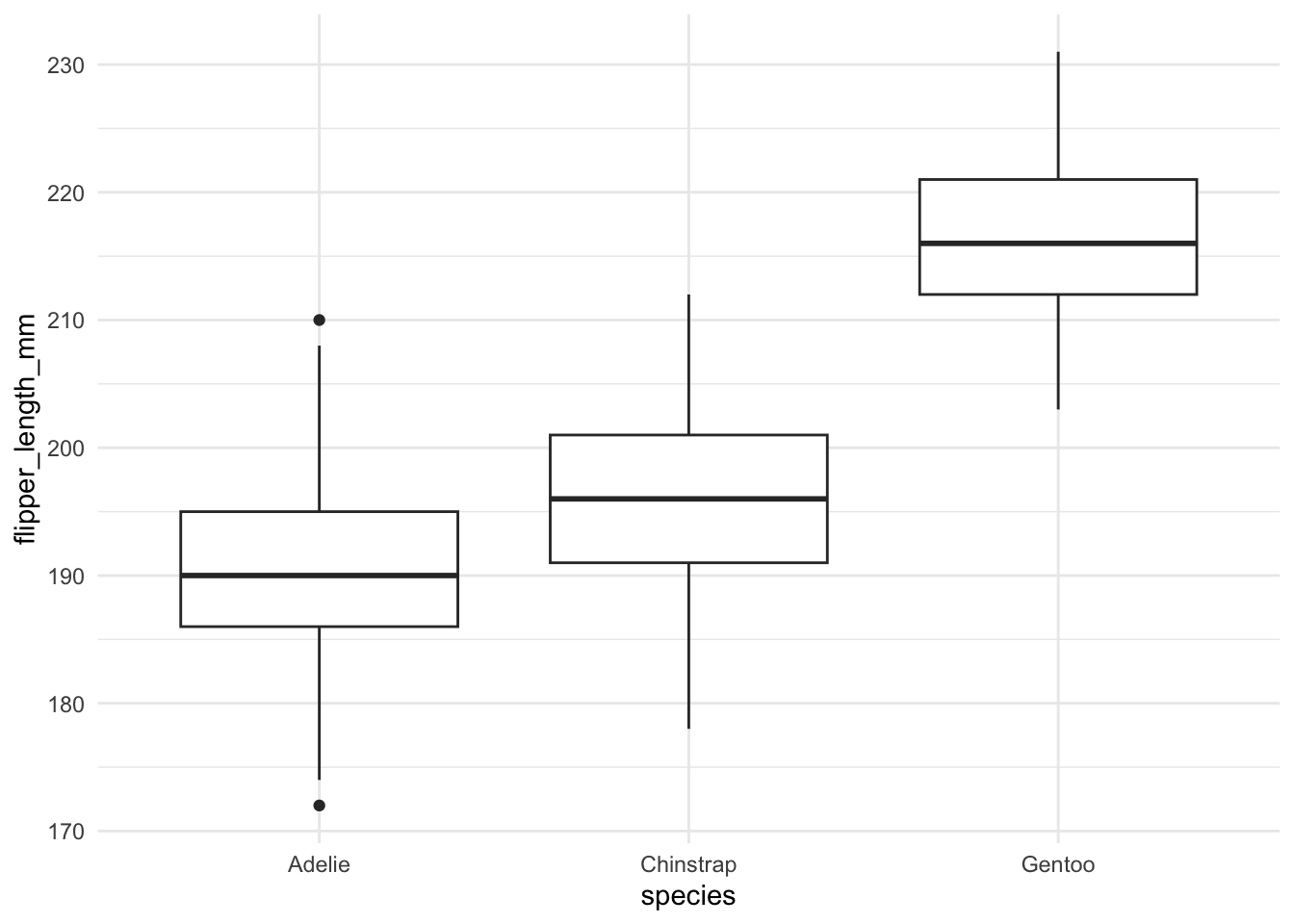
Grafiek- en astitels toevoegen
De grafieken die we tot nu toe hebben gemaakt met ggplot2 hebben geen grafiektitel en ook geen duidelijke astitels (de astitels worden door R automatisch aangemaakt op basis van de gebruikte x- en y variabelen). We kunnen deze titels toevoegen door een extra onderdeel toe te voegen aan de code voor de grafiek. We gebruiken hiervoor de labs functie (labs staat voor ‘labels’). Als voorbeeld passen we de boxplot aan die we hiervoor gemaakt hebben:
ggplot(data = irisdata, aes(x = Species, y = Sepal.Length)) +
geom_boxplot() +
theme_minimal() +
labs(
title = "Kelkbladlengtes voor de verschillende irissoorten",
x = "Soort iris",
y = "Kelkbladlengte (cm)"
)
Opdracht 2
Geef de boxplot die je in de vorige opdracht hebt gemaakt een grafiektitel en aslabels.
Klik hier voor het antwoord
# Maak een boxplot met daarin de flipperlengte per pinguinsoort
ggplot(data = pinguin, aes(x = species, y = flipper_length_mm)) +
geom_boxplot() +
theme_minimal() +
labs(
title = "De spreiding in flipperlengte voor de verschillende pinguins",
x = "Soort pinguin",
y = "Flipperlengte (mm)"
)## Warning: Removed 2 rows containing non-finite outside the scale range (`stat_boxplot()`).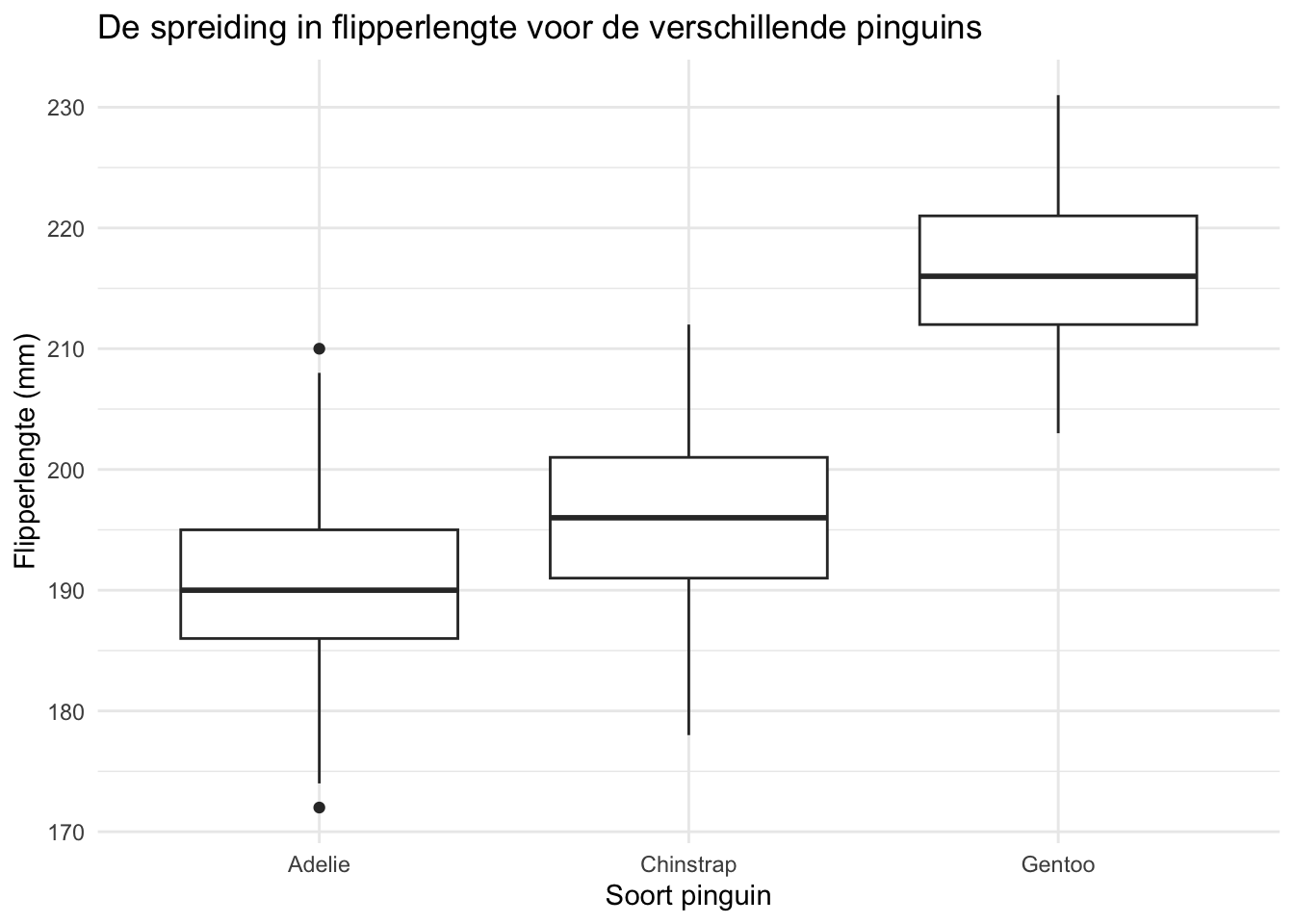
Fouten oplossen: R kan mijn file niet vinden
In de onderstaande video wordt uitgelegd wat je moet doen als het niet lukt om je data in te lezen in R:
Controleer altijd voordat je de data inleest of je werkt in een R project en of de dataset inderdaad aanwezig is in de projectfolder.
Fouten oplossen: R maakt geen goede grafiek
Het maken van grafieken met ggplot2 is relatief eenvoudig en gaat vaak goed. Toch zijn er een aantal veelvoorkomende problemen bij het maken van grafieken in R. In de onderstaande video wordt één van die problemen besproken:
Een veelvoorkomend probleem bij het maken van grafieken in R is dat R niet snapt dat een variabele een categorische variabele is. R ziet de variabele dan als een kwantitatieve variabele en niet als een kwalitatieve variabele. Om dit op te lossen (en om dus van de variabele een categorische variabele te maken), moet je de variabele in R omzetten naar een factor met de functie as.factor.
Werkcollege
Casus Les 2
In deze casus gaan we aan de slag met de data in het bestand casus_les02.txt. Deze dataset bevat voor verschillende personen de volgende gegevens:
- Leeftijd (
age). - Geslacht (
sex); voor deze variabele geldt dat de mannen worden weergegeven als1en de vrouwen als2. - Bloeddruk tijdens rust (
trestbps) in mmHg. - Cholesterolgehaltes in serum (
chol) in mg/dl. - Maximale hartslagfrequentie per minuut (
thalach).
In deze casus willen we de volgende onderzoeksvragen beantwoorden:
- Hoe is de leeftijd voor de verschillende proefpersonen verdeeld?
- Is er een verschil in bloeddruk tijdens rust tussen mannen en vrouwen?
- Is er een verband tussen de maximale hartslagfrequentie per minuut en de leeftijd?
Voer de onderstaande stappen van het data analyse stappenplan uit om deze onderzoeksvragen te beantwoorden. Verwerk alle gebruikte R code in een script en geef in dit script de gevonden resultaten/conclusies weer als comments.
Voorbereiding
Open een nieuw script voor je analyses en zorg ervoor dat dit script comments bevat die de stappen in het script beschrijven/toelichten.
Data inlezen
Laad de packages die je wilt gebruiken en lees de data in in R.
Data inspecteren
Hoeveel metingen (aantal rijen) bevat de dataset?
Resultaten communiceren
Bepaal hoe de leeftijd verdeeld is d.m.v. een histogram. Zorg voor duidelijke aslabels en voor een grafiektitel.
Bepaal of er een verschil is in de bloeddruk tijdens rust tussen de mannen en de vrouwen in deze dataset d.m.v. een boxplot. Zorg voor duidelijke aslabels en voor een grafiektitel.
Bepaal of er een verband is tussen de maximale hartslagfrequentie per minuut en de leeftijd d.m.v. een scatter plot. Geef de punten voor mannen en vrouwen een andere kleur. Zorg voor duidelijke aslabels en voor een grafiektitel.
Trek conclusies op basis van de grafieken en beantwoord de onderzoeksvragen.