Les 3
Leeruitkomsten
- De student kan Excel bestanden inlezen in R.
- De student kan herkennen of een dataset tidy is.
- De student kan een dataset tidy maken.
- De student kan rijen selecteren op basis van een of meerdere variabelen met de
filterfunctie. - De student kan per experimentele conditie het gemiddelde, de standaarddeviatie en andere beschrijvende statistieken bepalen met de
group_byensummarizefuncties. - De student kan staafdiagrammen maken met het
ggplot2package. - De student kan foutbalken aan grafiek toevoegen.
- De student kan pipes (
|>) toepassen in de R code om de code leesbaarder te maken.
Voorbereiding
Opdracht 3
Maak een nieuw R project aan voor les 3.
Data inlezen
In de vorige lessen heb je geleerd hoe je data in kunt lezen vanuit RDS bestanden en vanuit TSV bestanden. In deze les ga je leren hoe je data in kunt lezen vanuit Excel bestanden.
Data inlezen vanuit een Excel bestand
In de vorige les heb je geleerd hoe je een TSV bestand kunt herkennen door het te openen in RStudio. Voor Excel bestanden is dit niet nodig. Excel bestanden zijn namelijk gemakkelijk te herkennen aan de file extensie: de namen van Excel bestanden eindigen namelijk altijd op .xls of .xlsx.
Als je een Excel bestand wilt inlezen in R, kun je hiervoor de read_excel functie gebruiken. Deze functie is onderdeel van het readxl package. Als voorbeeld proberen we het bestand datasets.xlsx in te lezen:
De data wordt door de read_excel functie ingelezen als een tibble:
## # A tibble: 150 × 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ℹ 140 more rowsExcelbestanden met meerdere sheets
Excelbestanden kunnen meerdere sheets hebben. De read_excel functie leest altijd maar één sheet in. Als je niet aangeeft welke sheet ingelezen moet worden, leest read_excel de eerste sheet in van het Excelbestand.
Voordat je een Excelbestand inleest in R, is het daarom verstandig om te bekijken of het bestand meerdere sheets heeft en wat de namen van die sheets zijn. Je kunt hiervoor natuurlijk het bestand openen met Excel, maar je kunt dit ook bekijken met de excel_sheets functie in R:
## [1] "iris" "mtcars" "chickwts" "quakes" "iris_2" "quakes_1"Als we de tweede sheet willen inlezen kunnen we dit doen door de naam van de sheet te gebruiken:
We kunnen in plaats van de naam ook het nummer van de sheet gebruiken:
Opdracht 3
Lees de derde sheet van het bestand datasets.xlsx in in R. Beantwoordt voor deze dataset de volgende vragen:
- Hoeveel rijen en hoeveel kolommen heeft deze dataset?
- Wat is het hoogste en wat is het laagste gewicht (
weight) van de kippen in deze dataset? - Welke typen kippenvoer (
feed) zijn er aanwezig in de dataset? Gebruik hiervoor dedistinctfunctie (zoek zelf op hoe je deze functie kunt gebruiken).
Klik hier voor het antwoord
Als we de derde sheet willen inlezen kunnen we dit doen door de naam van de sheet te gebruiken:
We kunnen in plaats van de naam ook het nummer van de sheet gebruiken:
Vervolgens kunnen we de vragen beantwoorden voor deze dataset:
## [1] 71## [1] 2## [1] 108## [1] 423## # A tibble: 6 × 1
## feed
## <chr>
## 1 horsebean
## 2 linseed
## 3 soybean
## 4 sunflower
## 5 meatmeal
## 6 caseinData inspecteren
De functies uit het tidyverse package gaan uit van tidy data. We gaan nu bekijken wat tidy data is en hoe je je data tidy kunt maken.
Wat is tidy data?
Tidy data is een manier om data op een nette en gestructureerde manier te organiseren. Data is tidy als het voldoet aan de volgende voorwaarden:
- Elke variabele heeft zijn eigen kolom.
- Elke observatie heeft zijn eigen rij.
- Elke cel bevat maar één waarde.
Een voorbeeld van een tidy dataset is de volgende tabel:
| country | year | population | birth rate |
|---|---|---|---|
| mali | 2001 | 10.000.000 | 6.88 |
| mali | 2010 | 15.000.000 | 6.06 |
| sweden | 2001 | 9.000.000 | 1.57 |
| sweden | 2010 | 10.000.000 | 1.85 |
Een voorbeeld van een dataset die niet tidy is, is de volgende tabel:
| student | EDCC | molbio | immunologie | BID |
|---|---|---|---|---|
| Pietje | 7.5 | 6 | 8.2 | 8 |
| Marietje | 8 | 7.9 | 5 | 9 |
Deze dataset is niet tidy omdat de kolommen geen verschillende variabelen zijn. Er zijn eigenlijk maar twee variabelen en dat zijn student en cursus; de kolommen EDCC, molbio, immunologie en BID zijn de verschillende cursusnamen die onder de cursus variabele vallen. Een tidy versie van deze dataset is de volgende tabel:
| student | cursus | cijfer |
|---|---|---|
| Pietje | EDCC | 7.5 |
| Pietje | molbio | 6 |
| Pietje | immunologie | 8.2 |
| Pietje | BID | 8 |
| Marietje | EDCC | 8 |
| Marietje | molbio | 7.9 |
| Marietje | immunologie | 5 |
| Marietje | BID | 9 |
Opdracht 3
Het Excelbestand tidydata.xlsx bevat drie sheets met elk een eigen dataset. Laad elke sheet in in R en beoordeel of de data tidy is of niet.
Klik hier voor het antwoord
Dataset 1
## # A tibble: 6 × 4
## country year cases population
## <chr> <dbl> <dbl> <dbl>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Deze dataset is tidy: elke variabele heeft zijn eigen kolom, elke observatie zijn eigen rij en elke cel bevat maar één waarde.
Dataset 2
## # A tibble: 12 × 4
## country year type count
## <chr> <dbl> <chr> <dbl>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583Deze dataset is niet tidy, omdat niet elke observatie zijn eigen rij heeft. De observaties zijn hier namelijk per land en per jaar, maar voor elk jaar zijn er twee rijen aanwezig. Bovendien bevat de laatste kolom twee variabelen. Dit zou dus gesplitst moeten worden in twee aparte kolommen, ‘cases’ en ‘population’.
Dataset 3
## # A tibble: 6 × 3
## country year rate
## <chr> <dbl> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583Deze dataset is niet tidy, omdat de cellen van de laatste kolom meer dan één waarde bevatten.
Dataset 4
## # A tibble: 3 × 3
## country `1999` `2000`
## <chr> <dbl> <dbl>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766Deze dataset is niet tidy, omdat elke rij twee observaties bevat (voor zowel 1999 als 2000). Deze observaties zouden op verschillende rijen moeten staan. Bovendien bevatten de twee kolommen (1999 en 2000) dezelfde variabelen. Dit zou dus 1 kolom moeten worden, waarbij een aparte kolom ontstaat voor het jaartal.
Data omzetten naar tidy data
Als je dataset niet tidy is, kun je van de dataset een tidy dataset maken. Hierbij is het van belang dat je eerst kijkt op welke manier de data niet tidy is. Hieronder laten we voor twee scenario’s zien hoe je de data tidy kunt maken.
Scenario 1: één kolom bevat meerdere variabelen
In de vorige opdracht zagen we dit scenario bij de tweede dataset:
## # A tibble: 12 × 4
## country year type count
## <chr> <dbl> <chr> <dbl>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583De laatste kolom bevat eigenlijk twee variabelen (‘cases’ en ‘population’). Hierdoor is elke observatie verdeeld over twee rijen. Om van deze dataset een tidy dataset te maken, moeten we de laatste kolom dus opsplitsen in twee kolommen. We gebruiken hiervoor de pivot_wider functie:
## # A tibble: 6 × 4
## country year cases population
## <chr> <dbl> <dbl> <dbl>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583We zien nu waar de naam van de pivot_wider functie vandaan komt: de functie heeft het aantal kolommen vergroot, waardoor de tabel ‘breder’ is geworden.
Scenario 2: één variabele is verdeeld over meerdere kolommen
In de opdracht hierboven kwamen we dit scenario tegen bij de vierde dataset:
## # A tibble: 3 × 3
## country `1999` `2000`
## <chr> <dbl> <dbl>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766De kolommen ‘1999’ en ‘2000’ bevatten eigenlijk dezelfde variabele. Hierdoor bevat elke rij twee observaties, één voor het jaar 1999 en één voor het jaar 2000. Om dit op te lossen moeten we de laatste twee kolommen dus samenvoegen. Hiervoor kunnen we de pivot_longer functie gebruiken:
table4_tidy <- pivot_longer(data = table4, cols = c('1999', '2000'),
names_to = "year", values_to = "cases")
table4_tidy## # A tibble: 6 × 3
## country year cases
## <chr> <chr> <dbl>
## 1 Afghanistan 1999 745
## 2 Afghanistan 2000 2666
## 3 Brazil 1999 37737
## 4 Brazil 2000 80488
## 5 China 1999 212258
## 6 China 2000 213766Net als bij de pivot_wider functie doet de pivot_longer functie zijn naam eer aan: de functie heeft het aantal rijen groter gemaakt, waardoor de tabel ‘langer’ is geworden.
Opdracht 3
Het Excelbestand gene_expression_c10.xlsx bevat twee datasets, elk in een aparte sheet. Voer voor elke dataset de volgende stappen uit:
- Lees de dataset in in R.
- Bepaal of de dataset tidy is of niet.
- Maak, indien nodig, de dataset tidy.
Klik hier voor het antwoord
Dataset 1
## # A tibble: 24,574 × 6
## Gene `0h` `3h` `12h` `24h` `48h`
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Enpep 9.80 5.00 3.21 3.45 2.91
## 2 H19 12.7 12.9 11.0 6.79 6.14
## 3 Mki67 10.2 11.5 11.0 8.58 3.97
## 4 Cth 10.1 8.30 7.96 5.65 4.30
## 5 Lta 11.0 4.74 4.44 7.12 5.30
## 6 Ccnb2 9.08 10.5 10.4 8.35 3.53
## 7 Crisp3 8.48 5.81 3.39 2.79 2.94
## 8 affy_1455530_at 9.92 7.61 5.91 4.19 4.40
## 9 Birc5 9.13 10.5 9.95 7.77 3.62
## 10 Ighg 8.69 4.05 3.28 3.22 3.19
## # ℹ 24,564 more rowsDe dataset is niet tidy. Er is sprake van het tweede scenario: de genexpressie variabele is verdeeld over meerdere kolommen, terwijl het één variabele is. Hierdoor bevat een rij meerdere observaties. We kunnen dit oplossen met de pivot_longer functie:
genexpressie1_tidy <- pivot_longer(data = genexpressie1,
cols = c('0h', '3h','12h', '24h', '48h'),
names_to = "time(hrs)",
values_to = "expression")Dataset 2
## # A tibble: 16 × 4
## Gene cluster assay value
## <chr> <dbl> <chr> <dbl>
## 1 Enpep 1 gene_expression 9.80
## 2 Enpep 1 TBP_binding 18.8
## 3 H19 2 gene_expression 12.7
## 4 H19 2 TBP_binding 21.7
## 5 Mki67 3 gene_expression 10.2
## 6 Mki67 3 TBP_binding 23.2
## 7 Cth 4 gene_expression 10.1
## 8 Cth 4 TBP_binding 16.1
## 9 Lta 1 gene_expression 11.0
## 10 Lta 1 TBP_binding 20.0
## 11 Ccnb2 2 gene_expression 9.08
## 12 Ccnb2 2 TBP_binding 20.1
## 13 Crisp3 3 gene_expression 9.92
## 14 Crisp3 3 TBP_binding 15.9
## 15 Birc5 4 gene_expression 9.13
## 16 Birc5 4 TBP_binding 21.1Ook deze dataset is niet tidy. Er is sprake van het eerste scenario, aangezien er meerdere variabelen (genexpressie en TBP binding) in één kolom staan. We kunnen dit oplossen door gebruik te maken van de pivot_wider functie:
Tidy data exporteren als TSV bestand
Als je de data hebt omgevormd tot een tidy dataset, is het verstandig om deze nieuwe dataset op te slaan als TSV bestand. Dit is een vereiste voor goed datamanagement, waarin je bewerkte databestand opslaat voor later gebruik.
Om de tidy data te exporteren als TSV bestand gebruiken we de write_tsv functie (de omgekeerde functie van de read_tsv functie):
Resultaten bepalen
Per conditie het gemiddelde en de standaarddeviatie bepalen
Het vergelijken van experimentele condities is een belangrijk onderdeel van de data analyse. Bijvoorbeeld als we de controlegroep willen vergelijken met de behandelde groep. Vaak betekent dit dat we per experimentele conditie het gemiddelde en de standaarddeviatie bepalen. Deze gegevens kunnen we dan vervolgens weer uitzetten in een staafdiagram.
Als voorbeeld kijken we naar de dataset penguins.xlsx met daarin meetwaarden voor verschillende soorten pinguins. We lezen eerst de data in in R:
We willen bepalen of er een verschil is in de flipperlengte tussen de verschillende pinguinsoorten. We gebruiken de group_by en de summarize functie om eenvoudig het gemiddelde en de standaarddeviatie per soort te bepalen:
flipper_summary <- penguins |> group_by(species) |>
summarize(flipper_length_mean = mean(flipper_length_mm, na.rm=TRUE),
flipper_length_sd = sd(flipper_length_mm, na.rm=TRUE))
flipper_summary## # A tibble: 3 × 3
## species flipper_length_mean flipper_length_sd
## <chr> <dbl> <dbl>
## 1 Adelie 190. 6.54
## 2 Chinstrap 196. 7.13
## 3 Gentoo 217. 6.48Een paar opmerkingen voor de bovenstaande code:
- Via de
group_byfunctie geven we aan wat de groepen (= experimentele condities) zijn waarvoor we de gemiddeldes en standaarddeviaties willen uitrekenen. In dit geval willen we dat per soort doen, dus geven we in degroup_byfunctie despeciesvariabele op. - Met de
summarizefunctie kunnen we per groep nieuwe variabelen berekenen. In dit geval berekenen we de gemiddeldes en de standaarddeviaties, maar we zouden ook het minimum, maximum, mediaan etc. op dezelfde manier kunnen bepalen. - In de bovenstaande code wordt gebruik gemaakt van het
|>symbool. We zullen vanaf nu pipes zoveel mogelijk toepassen in de R code. In de onderstaande video worden pipes verder toegelicht:
Om de R code leesbaarder te maken kun je gebruik maken van pipes (|>). Met pipes kun je de data of de output van een eerdere functie doorsturen naar de volgende functie.
Opdracht 3
Lees het bestand olive.xlsx in in R. Deze data bevat de percentages voor verschillende vetzuren in Italiaanse olijfolie. Beantwoord voor deze dataset de volgende vragen:
- Is de dataset tidy?
- Bepaal het gemiddelde percentage stearinezuur (
stearic) en de standaarddeviatie voor dit vetzuur per regio (region).
Klik hier voor het antwoord
Eerst lezen we het bestand in in R:
Vervolgens kunnen we de vragen beantwoorden voor deze dataset:
## # A tibble: 572 × 10
## region area palmitic palmitoleic stearic oleic linoleic linolenic arachidic eicosenoic
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Southern Italy North-Apul… 10.8 0.75 2.26 78.2 6.72 0.36 0.6 0.29
## 2 Southern Italy North-Apul… 10.9 0.73 2.24 77.1 7.81 0.31 0.61 0.29
## 3 Southern Italy North-Apul… 9.11 0.54 2.46 81.1 5.49 0.31 0.63 0.29
## 4 Southern Italy North-Apul… 9.66 0.57 2.4 79.5 6.19 0.5 0.78 0.35
## 5 Southern Italy North-Apul… 10.5 0.67 2.59 77.7 6.72 0.5 0.8 0.46
## 6 Southern Italy North-Apul… 9.11 0.49 2.68 79.2 6.78 0.51 0.7 0.44
## 7 Southern Italy North-Apul… 9.22 0.66 2.64 79.9 6.18 0.49 0.56 0.29
## 8 Southern Italy North-Apul… 11 0.61 2.35 77.3 7.34 0.39 0.64 0.35
## 9 Southern Italy North-Apul… 10.8 0.6 2.39 77.4 7.09 0.46 0.83 0.33
## 10 Southern Italy North-Apul… 10.4 0.55 2.13 79.4 6.33 0.26 0.52 0.3
## # ℹ 562 more rows# De data is tidy, want elke variabele heeft zijn eigen kolom en
# elke observatie zijn eigen rij.
# Bepaal de gemiddelde/sd voor stearinezuur
olive_data |> group_by(region) |>
summarize(stearinezuur_gemiddelde = mean(stearic),
stearinezuur_stdev = sd(stearic))## # A tibble: 3 × 3
## region stearinezuur_gemiddelde stearinezuur_stdev
## <chr> <dbl> <dbl>
## 1 Northern Italy 2.31 0.390
## 2 Sardinia 2.26 0.176
## 3 Southern Italy 2.29 0.399Rijen selecteren op basis van een variabele
De pinguindataset bevat metingen uit verschillende jaren (2007, 2008 en 2009). Stel dat we opnieuw de flipperlengtes tussen de verschillende soorten willen vergelijken, maar dit keer enkel met de gegevens uit het jaar 2007. We kunnen hiervoor de filter functie gebruiken:
flipper_summary <- penguins |> filter(year == 2007) |>
group_by(species) |>
summarize(flipper_length_mean = mean(flipper_length_mm, na.rm=TRUE),
flipper_length_sd = sd(flipper_length_mm, na.rm=TRUE))
flipper_summary## # A tibble: 3 × 3
## species flipper_length_mean flipper_length_sd
## <chr> <dbl> <dbl>
## 1 Adelie 187. 6.46
## 2 Chinstrap 192. 6.05
## 3 Gentoo 215. 5.47Op een vergelijkbare manier kunnen we de flipperlengtes voor de verschillende soorten vergelijken met data uit de jaren 2007 en 2009:
flipper_summary <- penguins |> filter(year %in% c(2007,2009)) |>
group_by(species) |>
summarize(flipper_length_mean = mean(flipper_length_mm, na.rm=TRUE),
flipper_length_sd = sd(flipper_length_mm, na.rm=TRUE))
flipper_summary## # A tibble: 3 × 3
## species flipper_length_mean flipper_length_sd
## <chr> <dbl> <dbl>
## 1 Adelie 189. 6.88
## 2 Chinstrap 195. 7.02
## 3 Gentoo 217. 6.48Opdracht 3
We gaan verder met de dataset olive.xlsx die we in de vorige opdracht hebben ingelezen. Bepaal het gemiddelde gehalte linoleenzuur (linolenic) en de bijbehorende standaarddeviatie voor de verschillende gebieden (area) in de regio’s Noord Italië (Northern Italy) en Zuid Italië (Southern Italy).
Hint: gebruik de filter functie om de juiste regio’s te selecteren en bepaal dan de gevraagde waardes.
Klik hier voor het antwoord
# Bepaal de gemiddelde/sd voor linoleenzuur
olive_data |>
filter(region %in% c("Northern Italy", "Southern Italy")) |>
group_by(area) |>
summarize(linoleenzuur_gemiddelde = mean(linolenic),
linoleenzuur_stdev = sd(linolenic))## # A tibble: 7 × 3
## area linoleenzuur_gemiddelde linoleenzuur_stdev
## <chr> <dbl> <dbl>
## 1 Calabria 0.456 0.0649
## 2 East-Liguria 0.264 0.161
## 3 North-Apulia 0.426 0.0960
## 4 Sicily 0.425 0.0480
## 5 South-Apulia 0.347 0.0642
## 6 Umbria 0.341 0.102
## 7 West-Liguria 0.046 0.0503Resultaten communiceren
In de vorige les heb je geleerd hoe je met het ggplot2 package boxplots, scatter plots en histogrammen kunt maken. In deze les leer je hoe je staafdiagrammen met foutbalken kunt maken met ggplot2.
Staafdiagrammen met foutbalken maken
We gaan verder met de pinguin dataset. We vragen ons af of er een verschil is in het gemiddelde lichaamsgewicht tussen de drie soorten pinguins. In R kunnen we hiervoor een staafdiagram maken die het gemiddelde lichaamsgewicht voor elke pinguin weergeeft en waarin de standdaardeviaties zijn weergegeven als foutbalken:
# Maak een tibble met daarin het gemiddelde gewicht en de bijbehorende
# standaarddeviatie voor de verschillende pinguinsoorten
penguin_weight <- penguins |>
group_by(species) |>
summarize(weight_mean = mean(body_mass_g, na.rm = TRUE),
weight_sd = sd(body_mass_g, na.rm = TRUE))
# Geef de gewichten per pinguinsoort weer in een staafdiagram
penguin_weight |>
ggplot(aes(x = species, y = weight_mean)) +
geom_col() +
geom_errorbar(aes(ymin = weight_mean - weight_sd,
ymax = weight_mean + weight_sd),
width=.2) +
theme_minimal() +
labs(
title = "Vergelijking in lichaamsgewicht voor de verschillende soorten pinguins",
subtitle = "Foutbalken geven standaarddeviaties weer.",
x = "Soort pinguin",
y = "Gemiddelde lichaamsgewicht (gram)"
)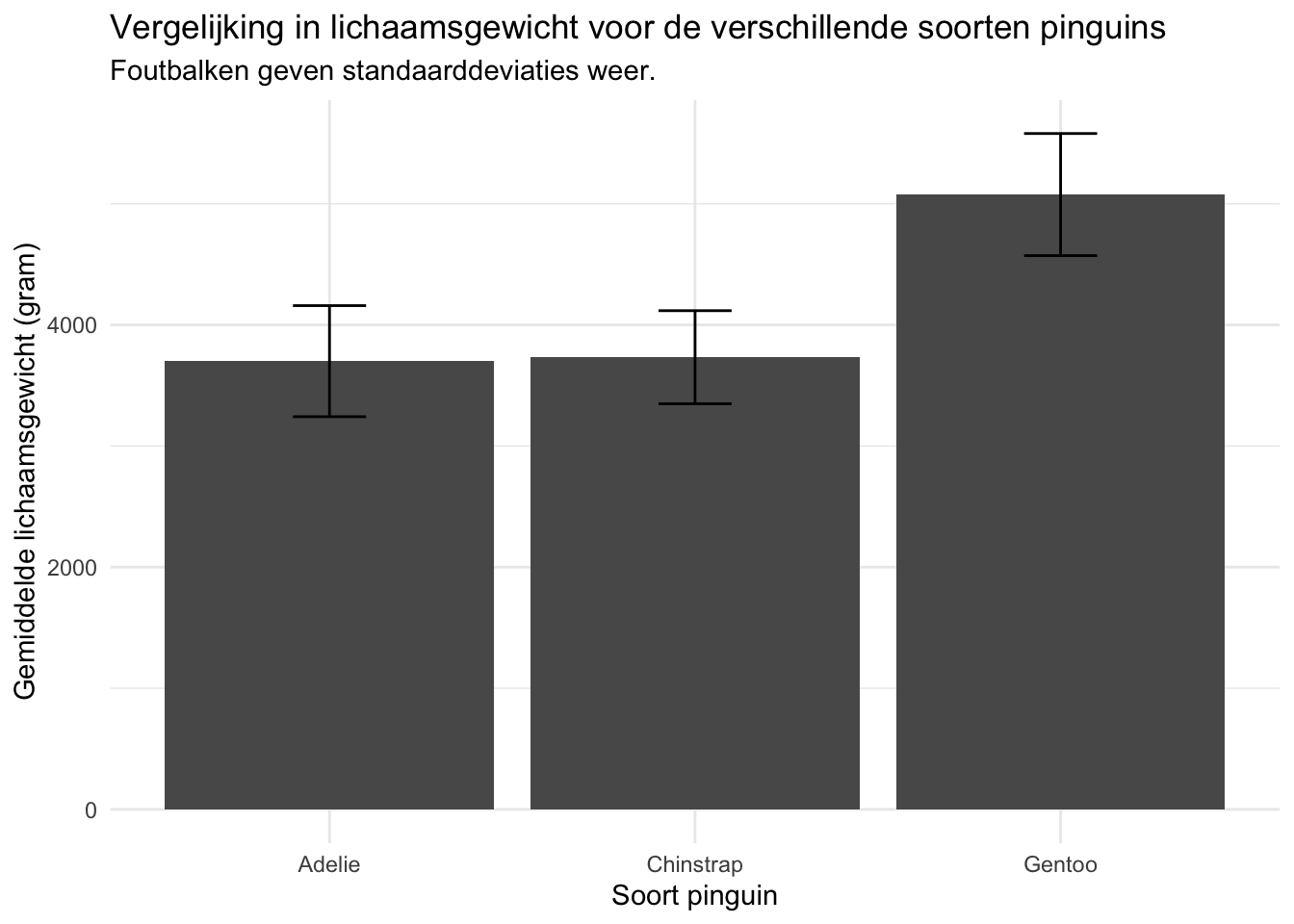
Een aantal opmerkingen over de bovenstaande code:
- Door pipes (
|>) te gebruiken kunnen we de verschillende stappen achter elkaar uitvoeren zonder dat de code onleesbaar wordt. - Om een staafdiagram te maken gebruiken we de
geom_colfunctie uit hetggplot2packages. - Om foutbalken weer te geven gebruiken we de
geom_errorbarfunctie. We geven in deze functie aan wat de minimum- en maximumwaardes zijn van de foutbalken. Verder is in de bovenstaande code de breedte van de foutbalken aangegeven. - In de ondertitel van de grafiek geven we aan wat de foutbalken weergeven. Op deze manier is alle informatie over het figuur in de titel en ondertitel aanwezig. In de latere lessen leer je hoe je deze informatie kunt rapporteren in een bijschrift bij het figuur.
Opdracht 3
We gaan verder met de dataset olive.xlsx die we in een vorige opdracht hebben ingelezen. We willen weten of er een verschil is in de palmitinezuurgehaltes in de olijfolie tussen de verschillende regio’s. Voer de volgende opdrachten uit om deze vraag te beantwoorden:
- Geef in een staafdiagram het gemiddelde gehalte palmitinezuur (
palmitic acid) weer voor de verschillende regio’s (region). - Geef de standaarddeviaties weer als foutbalken.
- Geef de grafiek duidelijke aslabels en een titel.
- Trek een conclusie op basis van de grafiek.
Klik hier voor het antwoord
# Bepaal de gemiddelde/sd voor palmitinezuur per regio
palmitine_data <- olive_data |>
group_by(region) |>
summarize(palmitinezuur_gemiddelde = mean(palmitic),
palmitinezuur_stdev = sd(palmitic))
# Geef de hoeveelheden palmitinezuur weer per regio
palmitine_data |>
ggplot(aes(x = region, y = palmitinezuur_gemiddelde)) +
geom_col() +
geom_errorbar(aes(
ymin = palmitinezuur_gemiddelde - palmitinezuur_stdev,
ymax = palmitinezuur_gemiddelde + palmitinezuur_stdev),
width = 0.2) +
theme_minimal() +
labs(
title = "De gemiddelde palmitinezuurgehaltes in de olijfolie uit verschillende Italiaanse regio's.",
subtitle = "De foutbalken geven de standaarddeviaties weer.",
x = "Regio in Italië",
y = "Palmitinezuurpercentage (%)"
)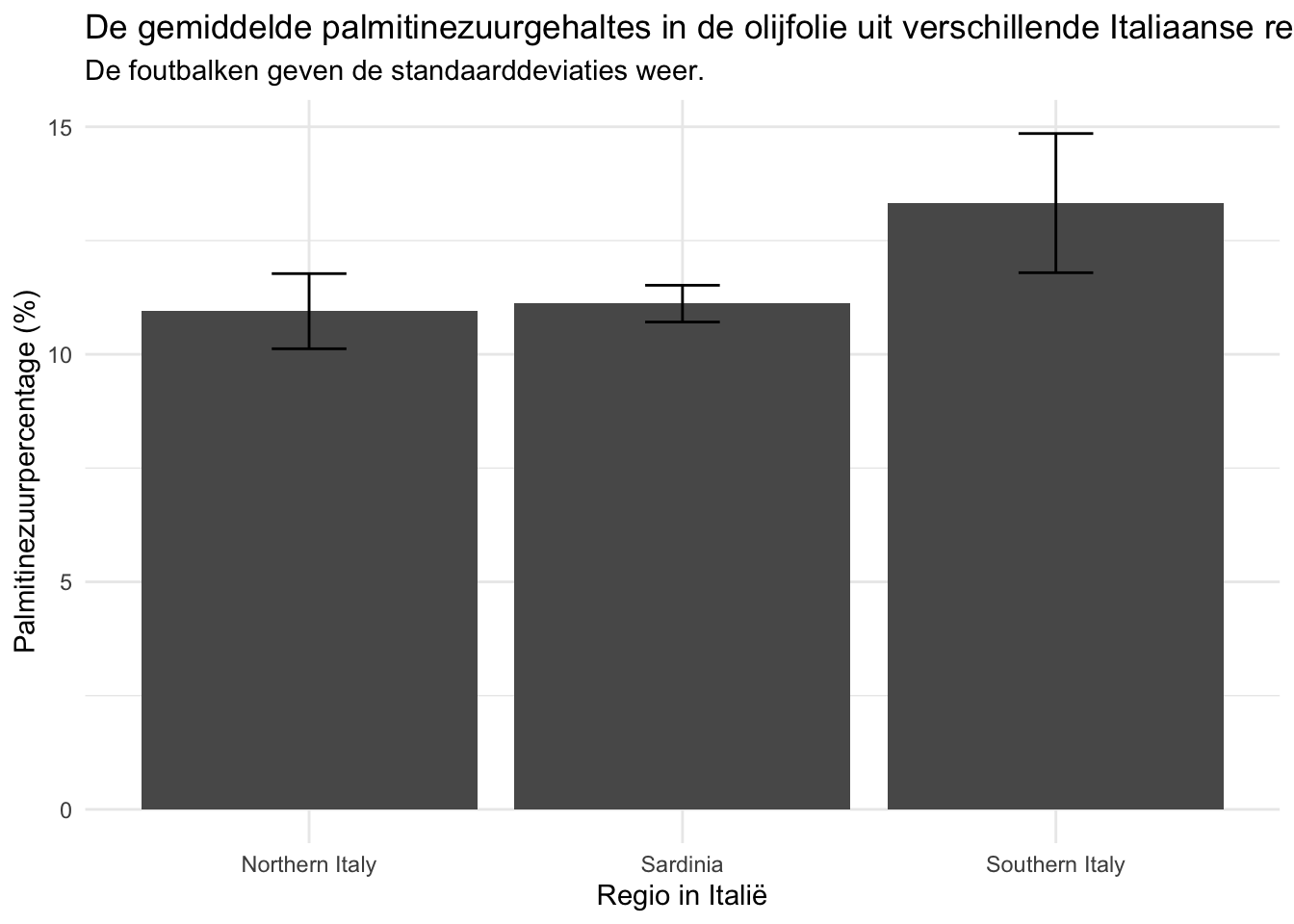
Conclusie: de olijfolie in Zuid Italië lijkt meer palmitinezuur te bevatten dan de olijfolie in de andere twee regio’s.
Fouten oplossen: de data heeft geen kolomnamen
De read_excel functie (en ook de read_tsv functie uit de vorige les) gaat ervan uit dat er kolomnamen in het databestand aanwezig zijn. De functie neemt aan dat de eerste rij van het Excelbestand kolomnamen zijn. Dit is niet altijd het geval. In de onderstaande video wordt toegelicht wat je moet doen als de data geen kolomnamen bevat:
Controleer altijd of de dataset die je in wilt lezen in R kolomnamen heeft. Als er geen kolomnamen zijn, kun je R zelf kolomnamen laten verzinnen of aan R kolomnamen meegeven met het col_names argument:
# Laad de data in R en laat R zelf kolomnamen verzinnen
irisdata <- read_excel("datasets.xlsx", sheet = "iris_2",
col_names = FALSE)
# Laad de data in R en geef R kolomnamen mee via een vector
irisdata <- read_excel("datasets.xlsx", sheet = "iris_2",
col_names = c("sepal.length", "sepal.width",
"petal.length", "petal.width",
"species"))Werkcollege
Casus Les 3
In deze casus gaan we aan de slag met de data in het bestand casus_les03.xlsx. Deze dataset bevat voor verschillende personen de volgende gegevens:
- Het patientnummer (
patientid). - Het geslacht (
gender). - De leeftijd (
age). - Het gemiddelde glucosegehalte van het bloed in mg/dL (
avg_glucose_level). - Het BMI (
bmi). - Een variabele die aangeeft of de patiënt een hoge bloeddruk heeft (
hypertension), waarbij0aangeeft dat er sprake is van een normale bloeddruk en1dat er sprake is van een hoge bloeddruk. - Een variabele die aangeeft of de patiënt een beroerte heeft gehad (
stroke), waarbij0aangeeft dat de patiënt geen beroerte heeft gehad en1aangeeft dat de patiënt wel een beroerte heeft gehad.
In deze casus willen we de volgende onderzoeksvragen beantwoorden:
- Is er een verband tussen het gemiddelde glucosegehalte van het bloed en het BMI?
- Is er een verschil in BMI tussen patiënten met een hoge bloeddruk en patiënten met een een normale bloeddruk?
- Is er een verschil in het gemiddelde glucosegehalte van het bloed tussen mannen en vrouwen?
Voer de onderstaande stappen van het data analyse stappenplan uit om deze onderzoeksvragen te beantwoorden. Verwerk alle gebruikte R code in een script en geef in dit script de gevonden resultaten/conclusies weer als comments.
Voorbereiding
Open een nieuw script voor je analyses en zorg ervoor dat dit script comments bevat die de stappen in het script beschrijven/toelichten.
Data inlezen
Laad de packages die je wilt gebruiken en lees de data in in R.
Data inspecteren
- Is er sprake van tidy data? Zo niet, maak de data dan eerst tidy.
- Bepaal hoeveel patiënten er in de dataset aanwezig zijn.
Resultaten bepalen en communiceren
Bepaal of er een verband is tussen het BMI en het gemiddelde glucosegehalte in het bloed d.m.v. een scatter plot. Geef de grafiek duidelijke aslabels en een grafiektitel. Geef in de grafiek met een kleurtje aan welke patiënten een beroerte hebben gehad en welke niet.
Bepaal of er een verschil is in BMI tussen patiënten met een normale bloeddruk en patiënten met een hoge bloeddruk. Maak hiervoor een boxplot én een staafdiagram. Geef beide grafieken duidelijke aslabels en grafiektitels.
Bepaal of er een verschil in het gemiddelde glucosegehalte van het bloed tussen mannen en vrouwen d.m.v. een staafdiagram. Zorg ervoor dat in de staafdiagram alleen de gegevens van mannen en vrouwen worden weergegeven (en niet die van
Other). Geef de grafiek duidelijke aslabels en een grafiektitel.Trek op basis van de grafieken conclusies om antwoord te geven op de onderzoeksvragen.