Les 6
Leeruitkomsten
- De student kan de in R uitgevoerde data analyse uitwerken in een RMarkdown bestand.
- De student kan grafieken in een RMarkdown bestand voorzien van een bijschrift.
Voorbereiding
Opdracht 6
Maak een nieuw R project aan voor les 6.
Rapporten maken met RMarkdown (deel 1)
Wat is RMarkdown?
Tot nu toe hebben we R scripts gebruikt om onze R code vast te leggen en beschikbaar te maken voor anderen. Scripts zijn geschikt voor het rapporteren van code, maar niet voor het rapporteren van figuren en tekst. RMarkdown bestanden bieden de mogelijkheid om code, grafieken en tekst te combineren in één bestand. In deze en de volgende les ga je leren hoe je een RMarkdown bestand kunt maken.
Een RMarkdown bestand is een bestand met de file extensie .Rmd. In dit bestand kun je R code combineren met gewone tekst (bijvoorbeeld tekst die uitleg geeft over de analyses en de conclusies van de analyses). Het RMarkdown bestand kan worden omgezet naar een output bestand. Dit proces heet knitten. In het output bestand (een html pagina) wordt de R code weergegeven, evenals de tekst. Bovendien wordt in het output bestand de R code uitgevoerd en worden de resultaten van de R code (bijvoorbeeld grafieken) weergegeven. Het bestand dat ontstaat na het knitten van het RMarkdown bestand kan gedeeld worden met anderen om de resultaten van de data analyse te rapporteren.
In de onderstaande video laten we een voorbeeld zien van een RMarkdown bestand en de output van het knitten:
Een nieuw RMarkdown bestand aanmaken
In de onderstaande video wordt getoond hoe je met RStudio een nieuw RMarkdown bestand kunt aanmaken:
Je kunt in RStudio eenvoudig zelf een RMarkdown bestand aanmaken. Zorg ervoor dat je het bestand opslaat met de file extensie .Rmd.
Tekst en R code toevoegen aan een RMarkdown bestand
Als je een RMarkdown bestand hebt aangemaakt, kun je beginnen met het vullen van dit bestand. In de onderstaande video wordt weergegeven hoe je tekst en R code kunt toevoegen aan het bestand:
In een RMarkdown bestand kun je gewone tekst eenvoudig toevoegen door tekst in het RMarkdown document te typen. Om R code toe te voegen moet je gebruik maken van code chunks. Je kunt deze code chunks aanmaken door CTRL + ALT + i in te drukken of via het Code menu.
Resultaten communiceren
Grafieken voorzien van bijschriften
In een RMarkdown bestand kunnen we code chunks toevoegen met daarin R code voor het maken van een grafiek. Als we het RMarkdown bestand knitten, zal de R code uitgevoerd worden en de grafiek zal in het resulterende html bestand worden weergegeven. We kunnen de grafiek ook voorzien van een bijschrift. In dit bijschrift kunnen we dan aangeven om wat voor data het gaat, wat er in de grafiek is weergegeven en wat de foutbalken voorstellen.
We kunnen een bijschrift toevoegen aan de grafiek door een fig.cap toe te voegen aan de code chunk. In de onderstaande video wordt gedemonstreerd hoe je dat doet:
In de vorige lessen hebben we de betekenis van foutbalken in staafdiagrammen uitgelegd in de ondertitel van de grafiek. Omdat we in RMarkdown de optie hebben om een bijschrift toe te voegen, zetten we deze informatie over de foutbalken vanaf nu in het bijschrift en laten we de ondertitel weg.
Opdracht 6
Maak een nieuw RMarkdown bestand aan en sla dit bestand op in de map van het huidige R project (dus, als het goed is, in de map van les 6). Verwerk in het RMarkdown bestand de volgende onderdelen:
- Lees het bestand
iris.txtin in R. - Maak een staafdiagram waarin je voor de verschillende soorten irissen (
Species) de gemiddelde kroonbladlengte (Petal.Length) weergeeft. Geef in de staafdiagram de standaarddeviaties weer als foutbalken. - Zorg ervoor dat in de staafdiagram de staven van groot naar klein zijn gerangschikt.
- Zorg ervoor dat de grafiek in het html bestand (dus na het knitten) voorzien is van een bijschrift. Dit bijschrift moet verklaren wat de foutbalken betekenen.
Klik hier voor het antwoord
---
title: "Analyse van de iris dataset"
author: "Bas van Gestel"
date: "2024-05-28"
output: html_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
Als eerste lezen we de data in in R. In dit geval is het een TSV bestand, dus we lezen de data in met de read_tsv functie.
```{r}
library(tidyverse)
irisdata <- read_tsv("iris.txt")
```
We kunnen nu de gevraagde staafdiagram maken:
```{r fig.cap="Figuur 1. In het bovenstaande staafdiagram wordt voor de verschillende irissoorten de gemiddelde kroonbladlengte weergegeven. De foutbalken geven de standaarddeviaties weer."}
irisdata |> group_by(Species) |>
summarize(gemiddelde_kblengte = mean(Petal.Length),
stdev_kblengte = sd(Petal.Length)) |>
ggplot(aes(x = reorder(Species, -gemiddelde_kblengte), y = gemiddelde_kblengte)) +
geom_col() +
geom_errorbar(aes(
ymin = gemiddelde_kblengte - stdev_kblengte,
ymax = gemiddelde_kblengte + stdev_kblengte),
width = 0.2) +
theme_minimal() +
labs(
title = "De gemiddelde kroonbladlengte voor de verschillende irissoorten.",
x = "Irissoort",
y = "Kroonbladlengte (cm)"
)
```
Het lijkt er dus op dat de soort Setosa kleinere kroonbladeren heeft dan de soorten Virginica en Versicolor.Data management
Met RMarkdown kun je je data analyse op een professionele manier rapporteren aan anderen. Een goede data analyse vereist echter niet alleen een mooi rapport, maar ook goed data management. Jullie hebben dit al geleerd in het vak TLSC-DAVE1V-24. Elk data analyseproject krijgt zijn eigen map. In de map zijn de volgende onderdelen aanwezig:
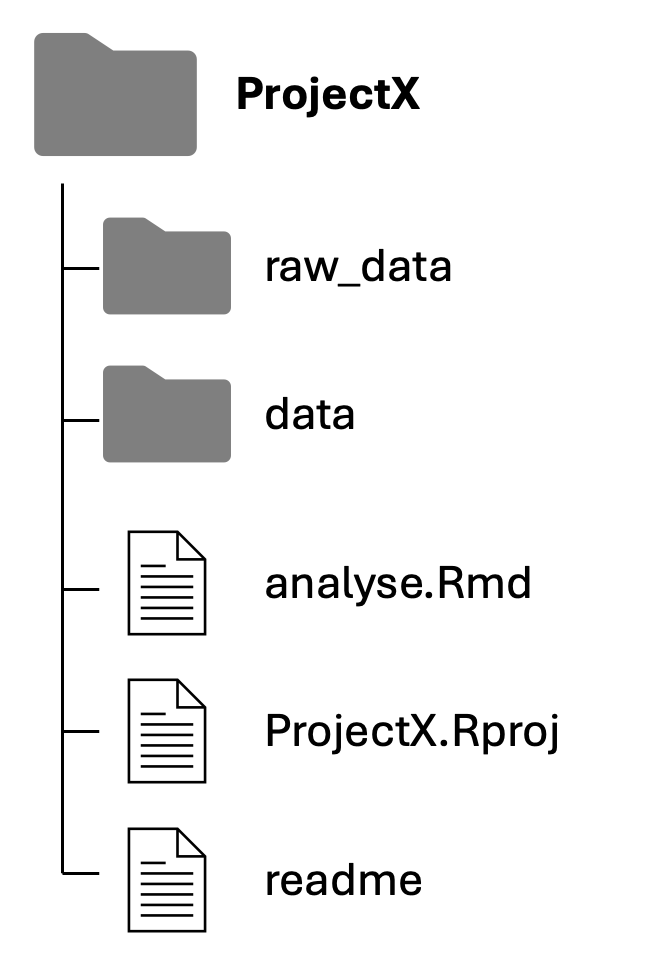
- Een mapje raw_data waarin de originele databestanden aanwezig zijn. Dit zijn de bestanden zoals je ze van anderen hebt gekregen of zoals je ze hebt gedownload. Vaak is deze data niet tidy.
- Een mapje data met daarin de bewerkte dataset. Dit is de tidy dataset die je hebt gebruikt voor je analyse. Als de originele data niet tidy is, kun je de data in je RMarkdown omzetten naar tidy data en vervolgens de tidy dataset opslaan in de data map.
- Een R project file voor het R project dat je hebt aangemaakt in de projectmap.
- Een analyse RMarkdown met daarin het rapport (code en output) voor de data analyse.
- Een readme bestand met daarin informatie over de files in de projectmap.
Beschouw vanaf nu de werkcollegeopdrachten als projecten waarvoor je de data management organiseert volgens de bovenstaande folderstructuur. Zorg er ook voor dat de data management voor het groepsproject op orde is.
Werkcollege
Casus Les 6
Werk de casus van les 5 uit in een RMarkdown document. Zorg ervoor dat het document voldoet aan het volgende:
- Alle R code is opgenomen in het RMarkdown document als code chunks.
- De conclusies en toelichtingen op de analyse zijn uitgewerkt in de tekst.
- De grafieken zijn voorzien van bijschriften.
- De data management voor de analyse voldoet aan de hierboven beschreven eisen.