Les 4
Leeruitkomsten
- De student kan testen of een verdachte waarde een uitschieter is met de Dixon’s Q test.
- De student kan een nieuwe variabele (kolom) toevoegen aan een tibble met de
mutatefunctie. - De student kan een lineair regressiemodel opstellen in R.
- De student kan een regressielijn aan een scatter plot toevoegen.
Voorbereiding
In deze les gaan we aan de slag met de verwerking van kalibratielijngegevens. De dataverwerking voor deze gegevens is al eerder behandeld in de cursus TLSC-DAVE1V-24. Nu gaan we laten zien hoe je deze gegevens kunt analyseren in R.
Data inlezen
We laten de verschillende stappen zien a.d.h.v. een voorbeeld. De data voor dit voorbeeld is te vinden in het bestand eiwitbepaling.xlsx. We beginnen met het inlezen van de data:
## [1] "kalibratie" "monsters"Het Excelbestand bestaat uit twee sheets, één met de gegevens voor de kalibratielijn en één met de gegevens voor de monsters. We slaan beide sheets op in aparte tibbles:
# Lees de kalibratielijndata in
kalibratielijn <- read_excel("eiwitbepaling.xlsx", sheet = "kalibratie")
# Lees de metingen voor de monsters in
monsters <- read_excel("eiwitbepaling.xlsx", sheet = "monsters")Opdracht 4
Voor de opdrachten in het voorbereidingsgedeelte van deze les gaan we aan de slag met het bestand zetmeelbepaling.xlsx. Lees de data van dit bestand in in R.
Klik hier voor het antwoord
# Bepaal welke Excel sheets aanwezig zijn in het bestand
excel_sheets("zetmeelbepaling.xlsx")
# Lees de kalibratielijndata in
kalibratie_zetmeel <- read_excel("zetmeelbepaling.xlsx", sheet = "kalibratie")
# Lees de metingen voor de monsters in
monsters_zetmeel <- read_excel("zetmeelbepaling.xlsx", sheet = "monsters")Data inspecteren
Voordat we de data gaan verwerken, is het belangrijk om eerst te controleren of er geen uitschieters/outliers in de data aanwezig zijn. Als het om herhaalde metingen gaat kunnen we de Dixon’s Q test gebruiken om te testen of een meetpunt een outlier is of niet (zie voor meer informatie over de Dixon’s Q test en het verwijderen van outliers het lesmateriaal van TLSC-DAVE1V-24).
Hiervoor is het van belang om eerst zelf goed naar de data te kijken. We kunnen hiervoor de ingelezen tibbles bekijken met de View functie:
De herhaalde metingen voor de monsters lijken geen uitschieters te bevatten. Voor de kalibratielijn is extinctie_3 bij de concentratie 10 \(\mu\)g/\(\mu\)L mogelijk een uitschieter. We gaan dit nu testen met de Dixon’s Q test. Hiervoor is het van belang dat we de data eerst tidy maken. Dit is ook voor andere analyses van belang, dus we gaan beide tibbles tidy maken. We kunnen dat in dit geval doen met de pivot_longer functie:
# Maak de kalibratielijndata tidy
kalibratielijn_tidy <- kalibratielijn |>
pivot_longer(cols = c(extinctie_1, extinctie_2, extinctie_3),
names_to = "herhaling", values_to = "extinctie")
# Maak de data met monstermetingen tidy
monsters_tidy <- monsters |>
pivot_longer(cols = c(extinctie_1, extinctie_2, extinctie_3),
names_to = "herhaling", values_to = "extinctie")We kunnen nu onderzoeken of er sprake is van een uitschieter met de Dixon’s Q test. We gebruiken hiervoor de dixon.test functie uit het outliers package:
# Laad de outliers library voor de dixon.test functie
library(outliers)
# Selecteer de rijen die horen bij de concentratie 10 mg/mL
data_uitschieter <- kalibratielijn_tidy |> filter(concentratie_mgpermL == 10)
# Voer de Dixon's Q test uit
dixon.test(data_uitschieter$extinctie)##
## Dixon test for outliers
##
## data: data_uitschieter$extinctie
## Q = 0.93827, p-value = 0.1048
## alternative hypothesis: highest value 0.553 is an outlierIn dit geval is de p-waarde groter dan 0.05 en er is dus geen sprake van een uitschieter. We laten het meetpunt dan ook in de dataset zitten.
Opdracht 4
We gaan verder met de data van het bestand zetmeelbepaling.xlsx uit de vorige opdracht. Maak de data tidy en controleer of de data uitschieters bevat.
Klik hier voor het antwoord
De vierde meting voor het eerste monster lijkt een uitschieter.
# Maak de kalibratielijndata tidy
kalibratie_zetmeel_tidy <- kalibratie_zetmeel |>
pivot_longer(cols = c(extinctie_1, extinctie_2, extinctie_3),
names_to = "herhaling", values_to = "extinctie")
# Maak de data met monstermetingen tidy
monsters_zetmeel_tidy <- monsters_zetmeel |>
pivot_longer(cols = c(extinctie_1, extinctie_2, extinctie_3,
extinctie_4, extinctie_5),
names_to = "herhaling", values_to = "extinctie")
# Bepaal of de verdachte waarde een uitschieter is
library(outliers)
data_uitschieter <- monsters_zetmeel_tidy |> filter(monsternummer == 1)
dixon.test(data_uitschieter$extinctie)##
## Dixon test for outliers
##
## data: data_uitschieter$extinctie
## Q = 0.9, p-value < 2.2e-16
## alternative hypothesis: highest value 0.701 is an outlierDe p-waarde is aanzienlijk kleiner dan 0.05, dus de waarde is een uitschieter. We verwijderen de waarde uit de data.
Data bewerken
Voor we de kalibratielijnformule gaan bepalen en de concentraties in de monsters gaan uitrekenen, willen we eerst de extinctiewaarden corrigeren voor de blanco. We willen dus de blancowaarde van alle extinctiewaarden aftrekken. We kunnen dit eenvoudig doen met de mutate functie. Met deze functie kunnen we de berekening uitvoeren en de uitkomst opslaan in een nieuwe kolom van de data.
# Creëer een variabele voor de gemiddelde blancometing
blanco_data <- kalibratielijn_tidy |> filter(concentratie_mgpermL == 0)
blanco_gemiddelde <- mean(blanco_data$extinctie)
# Creëer een kolom met blanco-gecorrigeerde waarden voor de kalibratielijndata
kalibratielijn_tidy <- kalibratielijn_tidy |>
mutate(extinctie_gecorrigeerd = extinctie - blanco_gemiddelde)
# Creëer een kolom met blanco-gecorrigeerde waarden voor de monstermetingen
monsters_tidy <- monsters_tidy |>
mutate(extinctie_gecorrigeerd = extinctie - blanco_gemiddelde)NB: in de bovenstaande code overschrijven we de variabele kalibratielijn_tidy; de tibble zonder extra kolom wordt vervangen door een tibble met extra kolom. Hetzelfde geldt voor de variabele monsters_tidy. Het overschrijven van variabelen is vaak geen goed idee. Hier kan het wel, omdat we iets toevoegen aan de data, zonder de oorspronkelijk data te wijzigen (er komt een kolom bij, maar de andere kolommen blijven hetzelfde).
Opdracht 4
We gaan verder met de data van het bestand zetmeelbepaling.xslx uit de vorige opdracht. Voer een blancocorrectie uit op deze data.
Klik hier voor het antwoord
# Bepaal de gemiddelde waarde van de blanco
blanco_data_zetmeel <- kalibratie_zetmeel_tidy |> filter(concentratie_mgperL == 0)
blanco_gemiddelde_zetmeel <- mean(blanco_data_zetmeel$extinctie)
# Creëer een kolom met blanco-gecorrigeerde waarden voor de kalibratielijndata
kalibratie_zetmeel_tidy <- kalibratie_zetmeel_tidy |>
mutate(extinctie_gecorrigeerd = extinctie - blanco_gemiddelde_zetmeel)
# Creëer een kolom met blanco-gecorrigeerde waarden voor de monstermetingen
monsters_zetmeel_tidy <- monsters_zetmeel_tidy |>
mutate(extinctie_gecorrigeerd = extinctie - blanco_gemiddelde_zetmeel)Resultaten bepalen
Bepalen of alle kalibratieconcentraties in het lineaire gebied vallen
Voordat we de formule van de kalibratielijn kunnen bepalen, moeten we eerst bepalen of alle gebruikte concentraties in het lineaire gebied van de kalibratielijn vallen. We visualiseren hiervoor de data in een grafiek:
# Maak een object met daarin de gemiddelden en standaarddeviaties voor de
# blanco-gecorrigeerde extinctiewaarden per standaardconcentratie
kalibratielijn_samenvatting <- kalibratielijn_tidy |>
group_by(concentratie_mgpermL) |>
summarize(extinctie_mean = mean(extinctie_gecorrigeerd),
extinctie_sd = sd(extinctie_gecorrigeerd))
# Geef de gemiddelde blanco-gecorrigeerde extinctiewaarden weer in een scatter plot
kalibratielijn_samenvatting |>
ggplot(aes(x = concentratie_mgpermL, y = extinctie_mean)) +
geom_point() +
theme_minimal()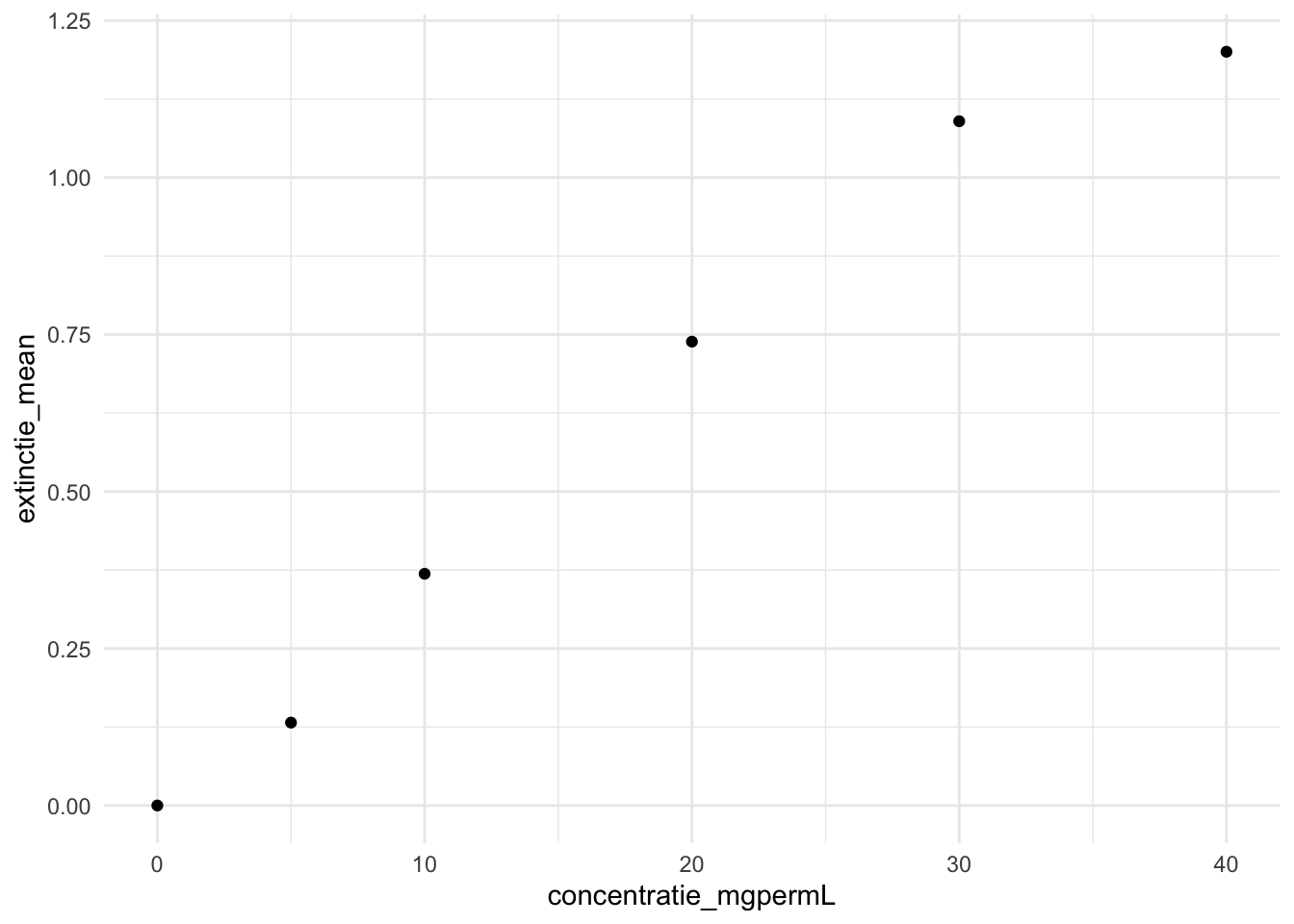
In de grafiek is duidelijk te zien dat de hoogste concentratie buiten het lineaire gebied valt. We gaan deze concentratie daarom verwijderen uit de dataset:
# Verwijder de hoogste concentratie uit de kalibratielijndata
kalibratielijn_samenvatting <- kalibratielijn_samenvatting |>
filter(concentratie_mgpermL != 40)In de bovenstaande code geeft het != in de filter functie aan dat de concentratie niet gelijk moet zijn aan 40. != betekent dus ‘niet gelijk aan’, terwijl == betekent ‘is gelijk aan’.
Opdracht 4
We gaan verder met de data uit de vorige opdracht. Bepaal of alle waarden van de kalibratielijn in het lineaire gebied vallen. Zo niet, verwijder de waarden die buiten het lineaire gebied vallen.
Klik hier voor het antwoord
# Maak een object met daarin de gemiddelden en standaarddeviaties voor de
# blanco-gecorrigeerde extinctiewaarden per standaardconcentratie
kalibratie_zetmeel_samenvatting <- kalibratie_zetmeel_tidy |>
group_by(concentratie_mgperL) |>
summarize(extinctie_mean = mean(extinctie_gecorrigeerd),
extinctie_sd = sd(extinctie_gecorrigeerd))
# Maak een grafiek om te bepalen of er waarden buiten het lineaire gebied vallen
kalibratie_zetmeel_samenvatting |>
ggplot(aes(x = concentratie_mgperL, y = extinctie_mean)) +
geom_point() +
theme_minimal()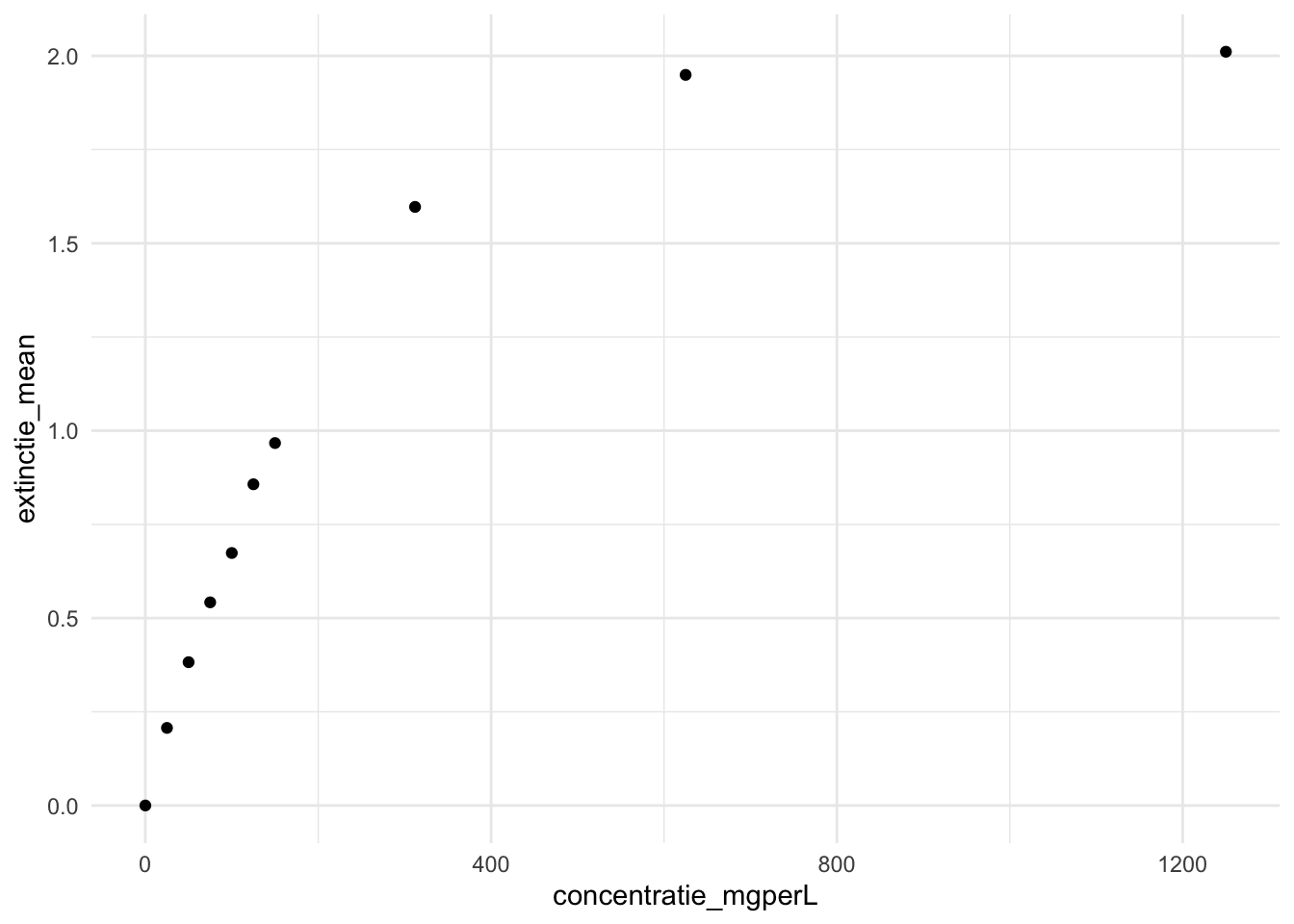
De hoogste drie concentraties lijken buiten het lineaire gebied te vallen. We verwijderen deze meetpunten uit de data.
De formule voor de kalibratielijn bepalen
We kunnen nu de formule voor de kalibratielijn bepalen. Omdat de kalibratielijn een lineair regressiemodel is, laten we R een linear model bepalen met de lm functie. Deze functie bepaalt de formule en determinatiecoëfficiënt voor de rechte lijn die het beste past bij de data. De rechte lijn is gebaseerd op de concentraties (concentratie_mgpermL, de x-waarde) en de extinctiewaarden (extinctie_mean, de y-waarde).
# Bepaal het lineaire regressiemodel
kalibratielijn_model <- lm(extinctie_mean ~ concentratie_mgpermL,
data = kalibratielijn_samenvatting)Voor het lineaire regressiemodel geldt de algemene formule \(extinctie = a \times concentratie + b\). We kunnen de coëfficiënten a en b uit het model halen:
# Bepaal de richtingscoëfficiënt van het model (de 'a' van de formule)
a <- kalibratielijn_model$coefficients[[2]]
# Bepaal de y-waarde van het snijpunt met de y-as (de 'b' van de formule)
b <- kalibratielijn_model$coefficients[[1]]De uiteindelijke formule is dus: extinctie = 0.037 x concentratie + -0.017
De determinatiecoëfficiënt bepalen
We kunnen voor dit lineaire regressiemodel ook de determinatiecoëfficient (\(R^2\)) bepalen. Hiervoor moeten we de summary functie toepassen op het lm object:
## [1] 0.9974156In dit geval is de determinatiecoëfficiënt groter dan 0.99, dus we kunnen de kalibratielijn gebruiken voor het kwantificeren van de monsters.
Concentraties uitrekenen voor monsters (indien mogelijk)
Met de gevonden kalibratielijnformule kunnen we nu de concentraties voor de monsters uitrekenen. Voor de berekening gebruiken we de volgende formule: \(concentratie = \frac{extinctie - b}{a}\). De uitkomst van de berekening kunnen we met de mutate functie opslaan in een nieuwe kolom:
Per monster kunnen we nu ook de gemiddelde concentratie en de bijbehorende standaarddeviatie berekenen:
monsters_samenvatting <- monsters_tidy |>
group_by(monsternummer) |>
summarize(extinctie_mean = mean(extinctie_gecorrigeerd),
concentratie_mean = mean(concentratie_mgpermL),
concentratie_sd = sd(concentratie_mgpermL))Om de concentraties te kunnen bepalen met de kalibratielijn moet de blanco-gecorrigeerde extinctie van een monster in het lineaire gebied van de ijklijn vallen. Met andere woorden, de extinctie van het monster moet tussen de laagste en hoogste blanco-gecorrigeerde extinctie van de ijklijn vallen. We kunnen dit controleren door de filter functie te gebruiken:
# Creëer variabelen met de minimale en maximale extinctie voor de kalibratielijn
min_kalibratielijn <- min(kalibratielijn_samenvatting$extinctie_mean)
max_kalibratielijn <- max(kalibratielijn_samenvatting$extinctie_mean)
# Filter monsters met een extinctie binnen het gebied van de kalibratielijn
monsters_samenvatting_gefilterd <- monsters_samenvatting |>
filter(extinctie_mean < max_kalibratielijn) |>
filter(extinctie_mean > min_kalibratielijn)
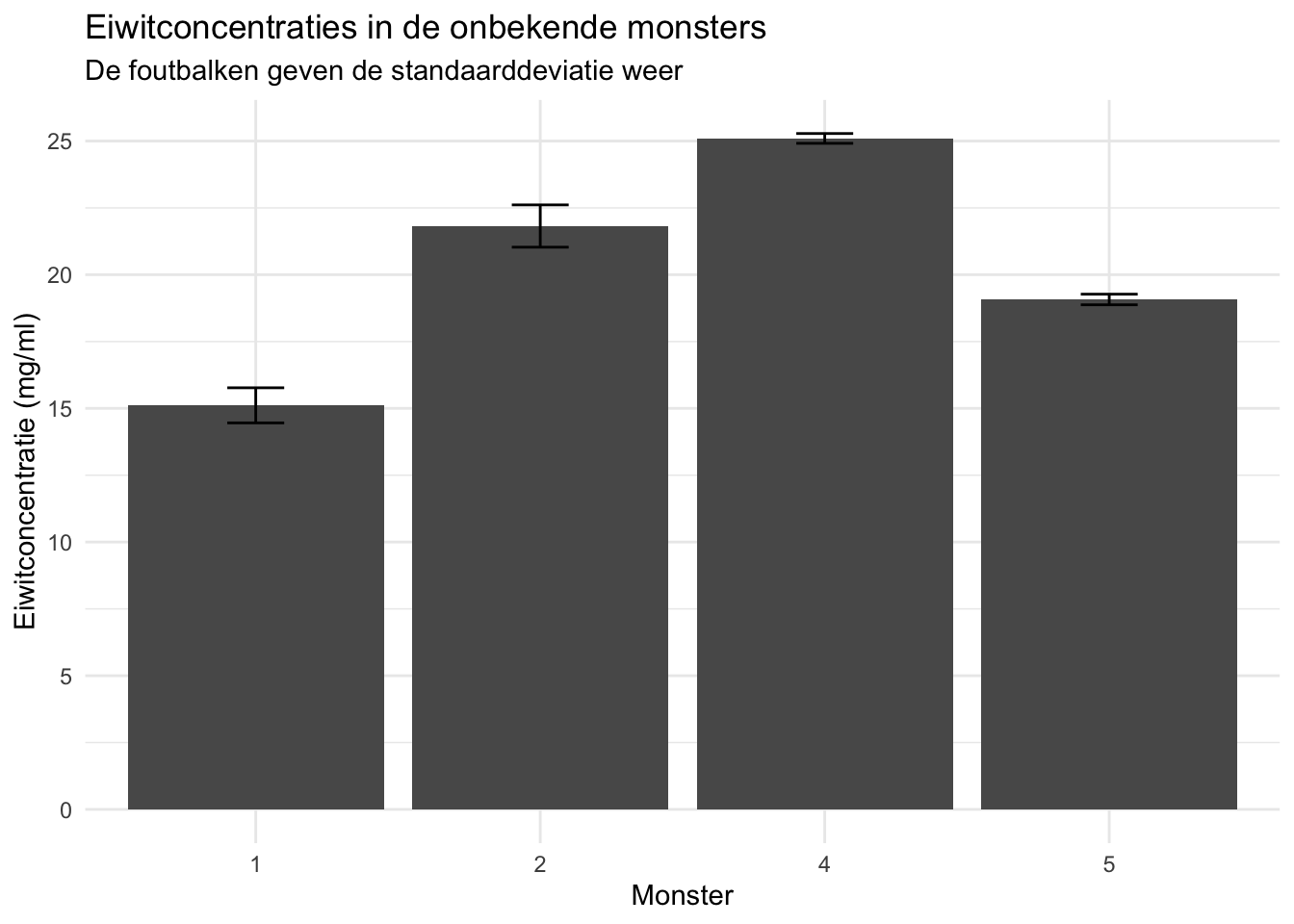
monsters_samenvatting_gefilterd## # A tibble: 4 × 4
## monsternummer extinctie_mean concentratie_mean concentratie_sd
## <dbl> <dbl> <dbl> <dbl>
## 1 1 0.544 15.1 0.657
## 2 2 0.793 21.8 0.791
## 3 4 0.915 25.1 0.183
## 4 5 0.691 19.1 0.199De waarden van het derde monster lagen buiten het gebied van de kalibratielijn en zijn uit de data verwijderd.
Opdracht 4
We gaan verder met de data uit de vorige opdracht. Bepaal de formule en de determinatiecoëfficiënt voor de kalibratielijndata. Bereken met de formule de concentraties van de monsters.
Klik hier voor het antwoord
# Bepaal het lineaire regressiemodel
kalibratie_zetmeel_model <- lm(extinctie_mean ~ concentratie_mgperL,
data = kalibratie_zetmeel_samenvatting)
# Bepaal de richtingscoëfficiënt van het model (de 'a' van de formule)
a_zetmeel <- kalibratie_zetmeel_model$coefficients[[2]]
# Bepaal de y-waarde van het snijpunt met de y-as (de 'b' van de formule)
b_zetmeel <- kalibratie_zetmeel_model$coefficients[[1]]
# Bepaal de determinatiecoëfficiënt
dc_zetmeel <- summary(kalibratie_zetmeel_model)$r.squared
dc_zetmeel## [1] 0.9944436# Bereken de concentraties van de monsters
monsters_zetmeel_tidy <- monsters_zetmeel_tidy |>
mutate(concentratie_mgperL = (extinctie_gecorrigeerd - b_zetmeel)/a_zetmeel)
# Bepaal de gemiddelde concentraties en de bijbehorende standaarddeviaties
# per monster
monsters_zetmeel_samenvatting <- monsters_zetmeel_tidy |>
group_by(monsternummer) |>
summarize(extinctie_mean = mean(extinctie_gecorrigeerd),
concentratie_mean = mean(concentratie_mgperL),
concentratie_sd = sd(concentratie_mgperL))
# Verwijder monsters die buiten het lineaire gebied van de ijklijn vallen
# (voor die monsters is de concentratie niet te bepalen)
min_kalibratielijn <- min(kalibratie_zetmeel_samenvatting$extinctie_mean)
max_kalibratielijn <- max(kalibratie_zetmeel_samenvatting$extinctie_mean)
monsters_zetmeel_samenvatting_gefilterd <- monsters_zetmeel_samenvatting |>
filter(extinctie_mean < max_kalibratielijn) |>
filter(extinctie_mean > min_kalibratielijn)
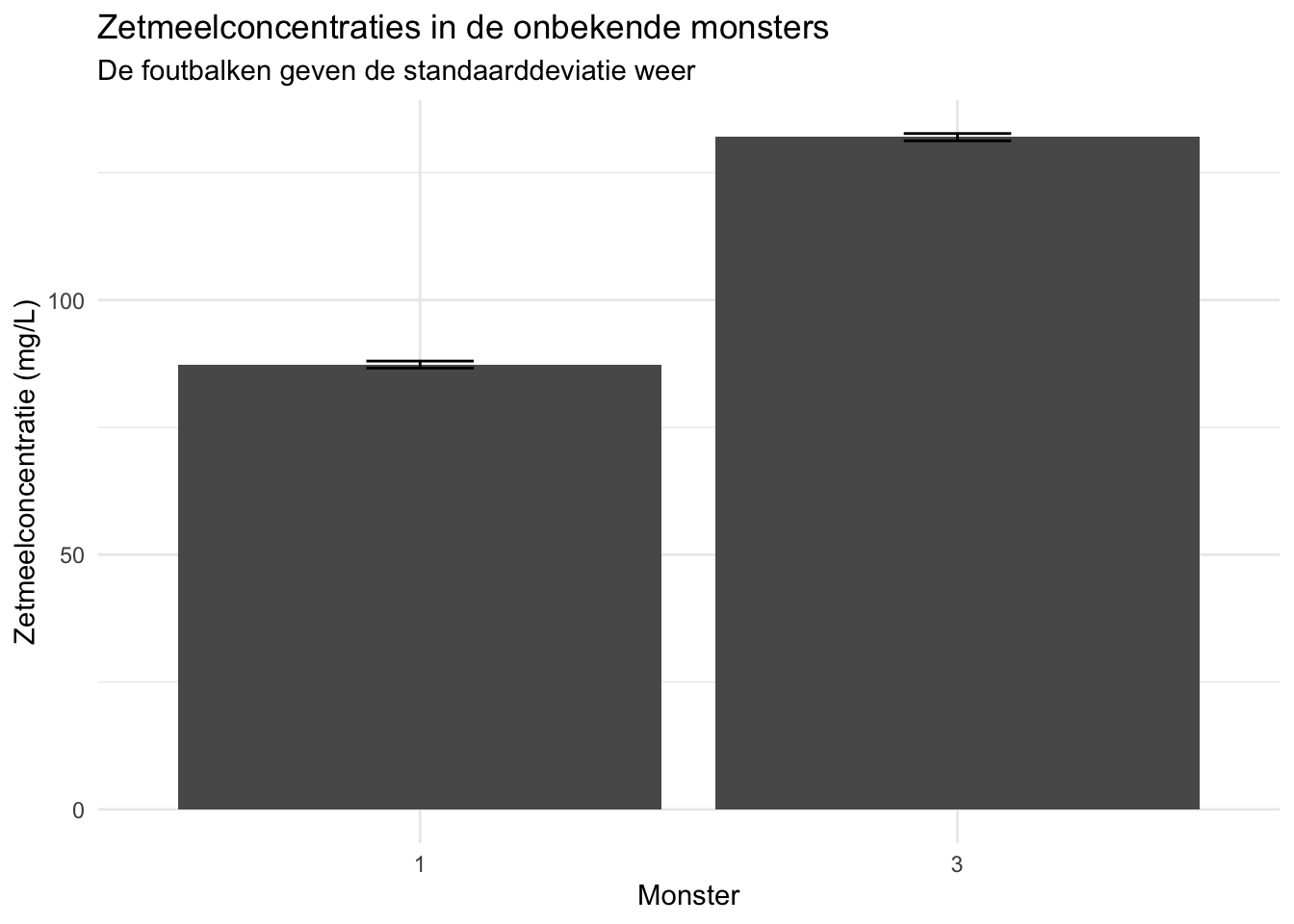
monsters_zetmeel_samenvatting_gefilterd## # A tibble: 2 × 4
## monsternummer extinctie_mean concentratie_mean concentratie_sd
## <dbl> <dbl> <dbl> <dbl>
## 1 1 0.597 87.3 0.691
## 2 3 0.884 132. 0.714Resultaten communiceren
Kalibratielijn visualiseren
Nu we alle resultaten bepaald hebben, kunnen we grafieken maken om de resultaten te visualiseren. Als eerste maken we een grafiek van de kalibratielijn. We maken hiervoor gebruik van een scatter plot waaraan we een trendline toevoegen met de geom_smooth functie:
# Rond de coëfficiënten van de kalibratielijnformule af voor communicatie
# in de grafiek. We ronden af op 3 significante cijfers, voor de leesbaarheid.
a_afgerond <- signif(a, digits = 3)
b_afgerond <- signif(b, digits = 3)
# Rond de determinatiecoëfficiënt af voor communicatie in de grafiek. We ronden
# af op 3 significante cijfers, voor de leesbaarheid.
dc_afgerond <- signif(dc, digits = 3)
# Visualiseer de kalibratielijn (inclusief formule en R2)
kalibratielijn_samenvatting |>
ggplot(aes(x = concentratie_mgpermL, y = extinctie_mean)) +
geom_point() +
geom_errorbar(aes(ymin = extinctie_mean - extinctie_sd,
ymax = extinctie_mean + extinctie_sd),
width=.2) +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
labs(title = "Kalibratielijn voor eiwitbepaling",
subtitle = paste("De determinatiecoefficient is", dc_afgerond,
"en de kalibratielijnformule is y = ",
a_afgerond, "x +", b_afgerond),
x = "Eiwitconcentratie (mg/ml)",
y = "Extinctie") +
theme_minimal()## `geom_smooth()` using formula = 'y ~ x'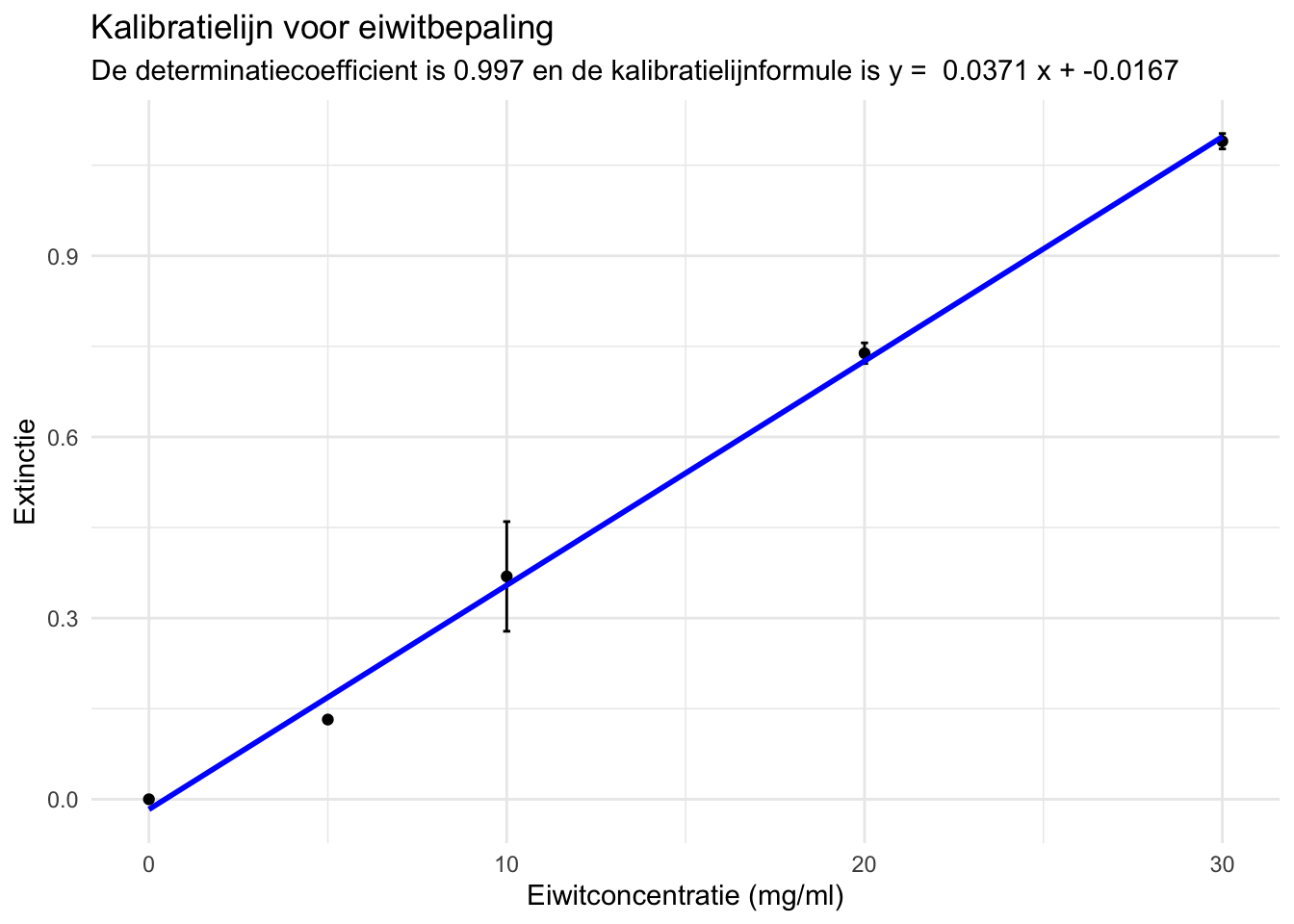
Een paar opmerkingen over de bovenstaande code:
- In de
geom_smoothfunctie geven we aan dat we een lineair regressielijn willen weergeven. Het model is hetzelfde als het model dat we eerder hebben gebruikt om de kalibratielijnformule op te stellen. - We willen de determinatiecoëfficiënt en de coëfficiënten van de kalibratielijnformule weergeven als tekst in de grafiek. Hiervoor ronden we deze getallen af. We gebruiken de
signiffunctie om af te ronden op drie significante cijfers. - De determinatiecoëfficiënt en de kalibratielijnformule geven we weer in de ondertitel. We gebruiken hiervoor de
pastefunctie om ‘normale’ stukken tekst te combineren met de tekst die is opgeslagen in R variabelen.
Staafdiagram voor de monsters
Voor de berekende concentraties van de monsters kunnen we een staafdiagram maken, zoals we dat in de vorige les hebben geleerd:
monsters_samenvatting_gefilterd |>
ggplot(aes(x = as.factor(monsternummer), y = concentratie_mean)) +
geom_col() +
geom_errorbar(aes(ymin = concentratie_mean - concentratie_sd,
ymax = concentratie_mean + concentratie_sd),
width = 0.2) +
theme_minimal() +
labs(
title = "Eiwitconcentraties in de onbekende monsters",
subtitle = "De foutbalken geven de standaarddeviatie weer",
x = "Monster",
y = "Eiwitconcentratie (mg/ml)"
)
Opdracht 4
Maak grafieken voor de kalibratielijn en de monsters voor de zetmeelbepaling (zie data uit de vorige opdrachten). Zorg ervoor dat de grafieken duidelijke aslabels en titels hebben.
Klik hier voor het antwoord
Grafiek voor de kalibratielijn
# Rond de coëfficiënten van de kalibratielijnformule af voor communicatie
# in de grafiek. We ronden af op 3 significante cijfers, conform de regels
# uit TLSC-DAVE1V-24
a_zetmeel_afgerond <- signif(a_zetmeel, digits = 3)
b_zetmeel_afgerond <- signif(b_zetmeel, digits = 3)
# Rond de determinatiecoëfficiënt af voor communicatie in de grafiek. Gebruik
# hiervoor de afrondregels uit TLSC-DAVE1V-24
dc_zetmeel_afgerond <- signif(dc_zetmeel, digits = 3)
# Visualiseer de kalibratielijn (inclusief formule en R2)
kalibratie_zetmeel_samenvatting |>
ggplot(aes(x = concentratie_mgperL, y = extinctie_mean)) +
geom_point() +
geom_errorbar(aes(ymin = extinctie_mean - extinctie_sd,
ymax = extinctie_mean + extinctie_sd),
width=.2) +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
labs(title = "Kalibratielijn voor zetmeelbepaling",
subtitle = paste("De determinatiecoefficient is", dc_zetmeel_afgerond,
"en de kalibratielijnformule is y = ",
a_zetmeel_afgerond, "x +", b_zetmeel_afgerond),
x = "Zetmeelconcentratie (mg/L)",
y = "Extinctie") +
theme_minimal()## `geom_smooth()` using formula = 'y ~ x'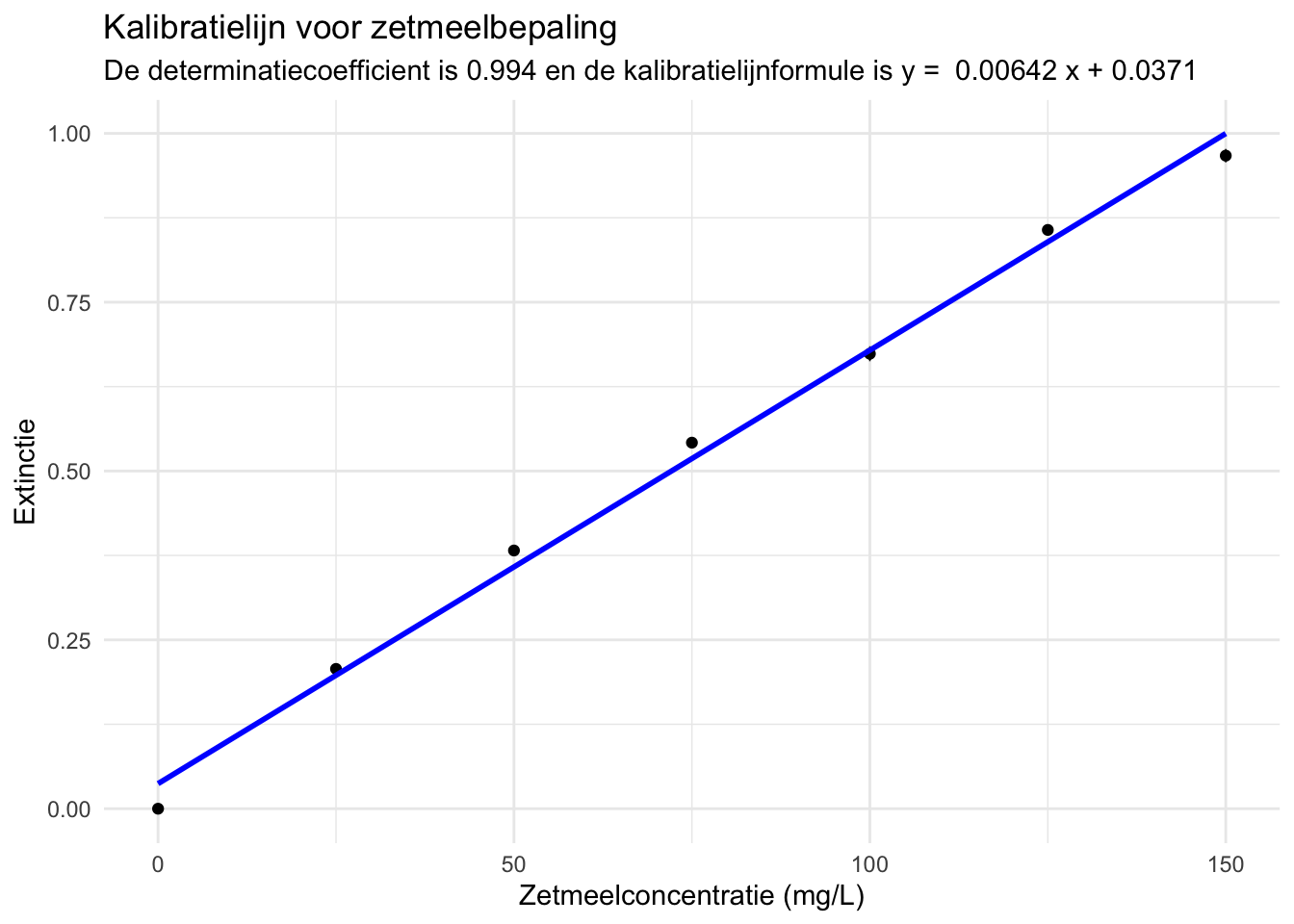
Grafiek voor de monsters
monsters_zetmeel_samenvatting_gefilterd |>
ggplot(aes(x = as.factor(monsternummer), y = concentratie_mean)) +
geom_col() +
geom_errorbar(aes(ymin = concentratie_mean - concentratie_sd,
ymax = concentratie_mean + concentratie_sd),
width = 0.2) +
theme_minimal() +
labs(
title = "Zetmeelconcentraties in de onbekende monsters",
subtitle = "De foutbalken geven de standaarddeviatie weer",
x = "Monster",
y = "Zetmeelconcentratie (mg/L)"
)
Werkcollege
Casus Les 4
In deze casus gaan we aan de slag met de data in het bestand casus_les04.xlsx. Het betreft de kalibratielijndata en monstermetingen voor een glucosebepaling. Met deze data willen we voor elk monster de glucoseconcentratie bepalen.
Bepaal de glucoseconcentraties in de monsters zoals je hebt geleerd in de voorbereiding van deze les. Verwerk alle gebruikte R code in een script en geef met comments aan welke stappen er zijn uitgevoerd. Vat alle resultaten samen in twee grafieken, één voor de kalibratielijn en één voor de monsters.