Project ‘Zoek de verschillen met RNA-seq!’
Docenten: Michael Liem
Leeruitkomsten
Het project heeft de volgende (algemene) leeruitkomsten:
- De student kan een gegeven RNA-seq dataset analyseren met R en zo een biologische vraag beantwoorden.
- De student kan de functies en parameters in de gebruikte R code toelichten en eventuele keuzes verantwoorden.
- De student kan de data analyse reproduceerbaar uitwerken in een Rmarkdown bestand.
- De student kan de code voor de analyse documenteren en beschikbaar maken met git en github.
Onder het kopje toetsing zijn deze algemene leeruitkomsten uitgewerkt in specifieke leeruitkomsten die worden getoetst.
Introductie
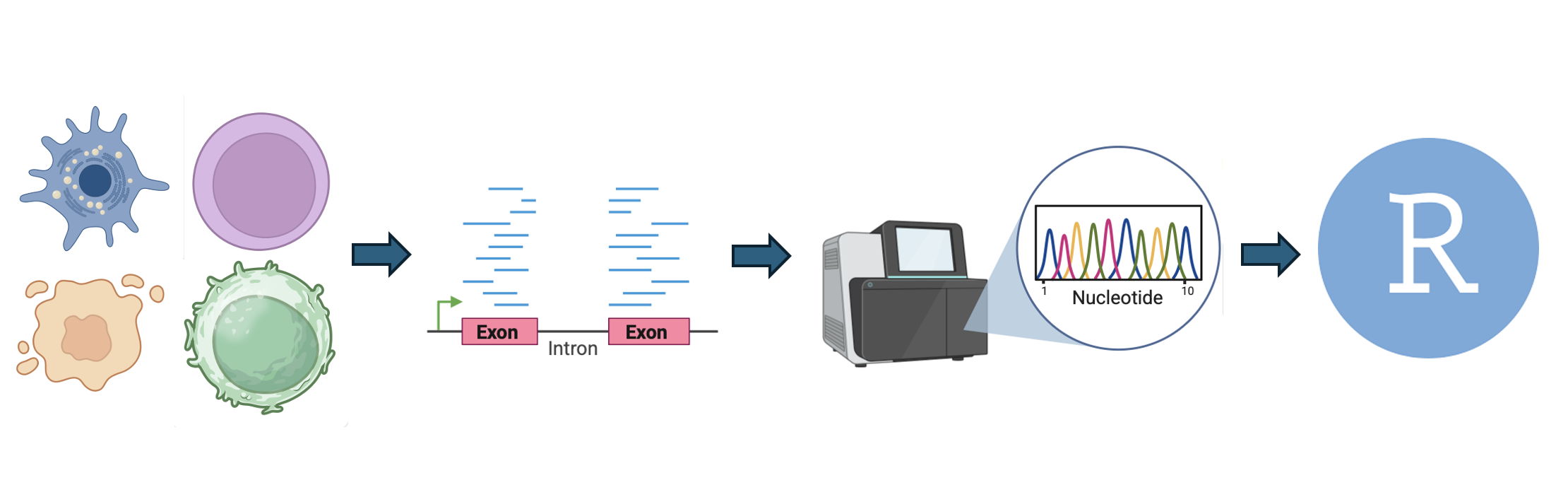
Alle cellen in een organisme hebben hetzelfde DNA, maar toch verschillen de cellen in vorm en functie. Dit komt doordat genen in cellen verschillend tot expressie komen. Zo kan een gen tot expressie komen in een hersencel, maar niet tot expressie komen in een niercel. Om te bepalen welke genen tot expressie komen, moeten we bepalen of er RNA aanwezig is voor de genen. RNA-sequencing is een techniek die veel gebruikt wordt om de hoeveelheid RNA in verschillende cellen te meten. In dit project ga je aan de slag met gepubliceerde RNA-sequencing datasets voor verschillende weefsels. Je gaat de data analyseren om te onderzoeken wat de verschillen zijn tussen de weefsels. Uiteindelijk levert dit niet alleen een antwoord op, maar ook een reproduceerbare workflow die gebruikt kan worden voor de analyse van andere RNA-sequencing datasets.
Cursusinformatie
Tutormomenten
Tijdens het project is er elke week één of meerdere tutormomenten. Tijdens deze tutormomenten kun je vragen stellen aan je tutor en feedback ontvangen. Verder is er tijdens deze tutormomenten tijd om vaardigheden af te toetsen voor de vaardighedenkaart (zie hieronder bij Toetsing).
‘Labmomenten’
Voor dit project ga je niet het lab op. Het is een data-analyse project, dus de data is er al. In dit geval is de data afkomstig uit een grote dataset, namelijk de ‘Atlas of RNA sequencing profiles of normal human tissues’.
Tijdens de onbegeleide ‘labmomenten’ ga je aan de slag met de data. Het doel is om een biologische vraag met RNA-seq data te kunnen beantwoorden. Hierbij is het reproduceerbaar vastleggen van de analysestappen in een Rmarkdown document een voorwaarde.
Server
Tijdens het project maak je gebruik van een server. Je hoeft R en RStudio daarom voor de cursus niet te installeren op je laptop. Als je dat al wel hebt gedaan, dan blijft het advies om op de server te werken: de rna-seq bestanden zijn namelijk groot en de analyse van deze bestanden lukt daarom niet op een normale laptop.
De server is te bereiken via de volgende link:
Je kunt op de server inloggen met je HU inloggegevens.
Mocht je niet in kunnen loggen op de server, of mochten er andere problemen zijn met de server, neem dan contact op met Bas van Gestel (bas.vangestel@hu.nl).
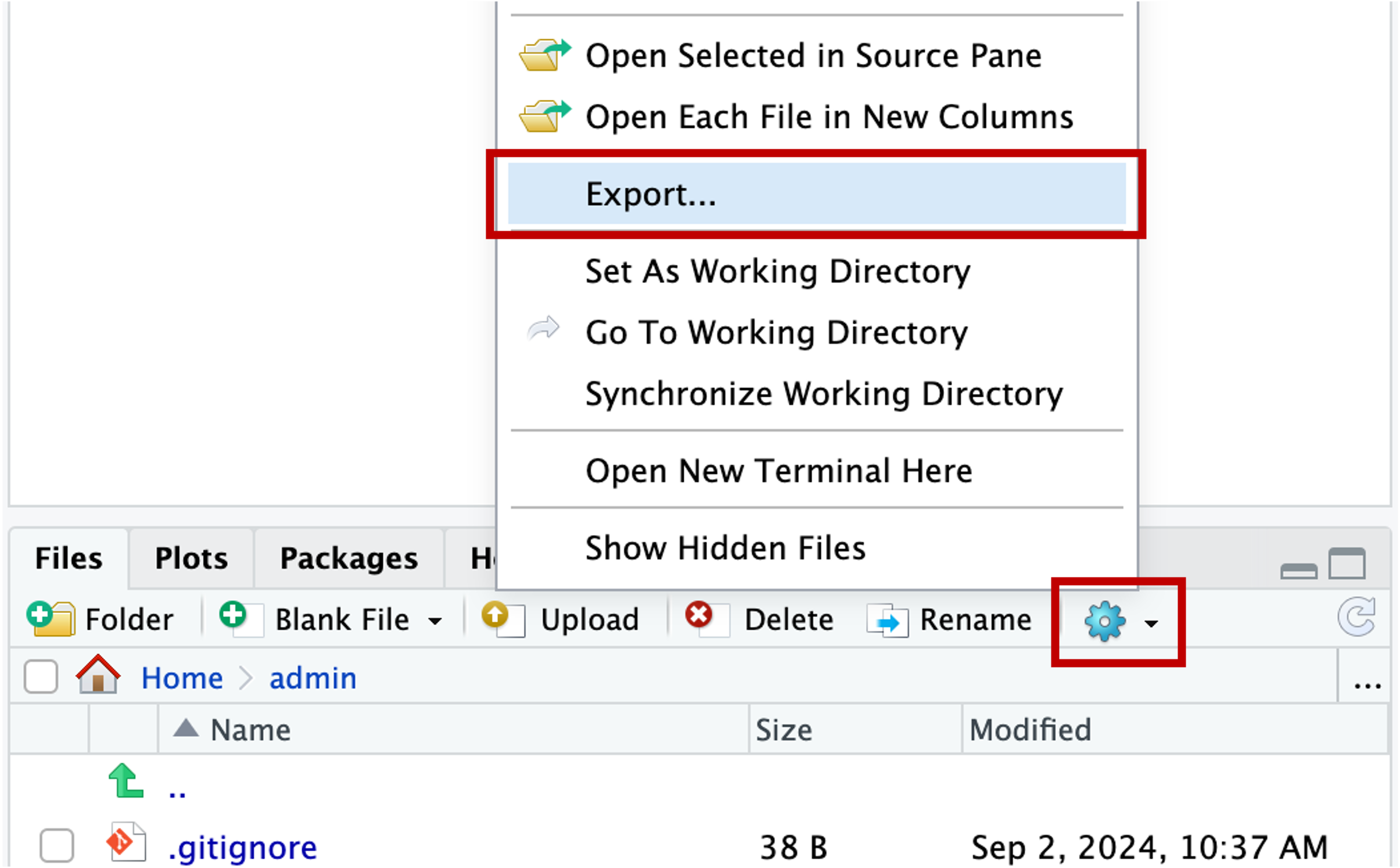
LET OP: er worden geen backups gemaakt van je werk op de server. Hiervoor ben je dus zelf verantwoordelijk! Je kunt files beheren met git/GitHub (zie de informatie in deze workshop) of files exporteren/downloaden via de ‘Export’ optie in het Files window:
Toetsing
De toetsing voor dit project bestaat uit drie onderdelen. Hieronder vind je een uitleg voor elk onderdeel.
Vaardighedenkaart (weging 10% / individuele beoordeling)
Tijdens de tutormomenten van het project moet je op zelf gekozen momenten laten zien dat je bepaalde vaardigheden beheerst. Deze vaardigheden worden beoordeeld met een ‘onder niveau’, ‘op niveau’ of ‘boven niveau’ beoordeling op de vaardighedenkaart . Alle onderdelen op de vaardighedenkaart moeten uiteindelijk ‘op niveau’ of ‘boven niveau’ zijn afgerond.
Met de vaardighedenkaart worden de volgende leeruitkomsten getoetst:
- de student kan een git repository aanmaken en koppelen/clonen aan een RStudio project;
- de student kan een branch aanmaken en mergen met de main branch;
- de student heeft een professionele werkhouding en is op tijd en aanwezig tijdens de tutormomenten;
- de student kan de feedback van de tutor verwerken en de verbeteringen zichtbaar maken;
- en de student kan concrete taken vastleggen en communiceren met issues.
Groepsproducten (weging 40% / groepsbeoordeling)
Als groep leveren jullie een reproduceerbare data analyse op voor de gegeven RNA-seq datasets.
Bij dit onderdeel worden de volgende leeruitkomsten getoetst:
- de studenten kunnen de achtergrond en het doel van het onderzoek beschrijven;
- de studenten kunnen git/GitHub gebruiken voor het bijhouden van wijzigingen gedurende het project (commits en het gebruik van branches);
- de studenten kunnen comments gebruiken om de gebruikte code toe te lichten en leesbaar te maken;
- de studenten kunnen instructies voor andere gebruikers documenteren in de vorm van een README bestand;
- de studenten kunnen de R code documenteren in een knitbaar Rmarkdown document;
- de studenten kunnen de resultaten (tekst en figuren) rapporteren in het Rmarkdown bestand;
- de studenten kunnen de conclusies en discussiepunten van de analyses beschrijven;
- en de studenten kunnen suggesties geven voor vervolgonderzoek en/of verbeteringen van de analyse.
Eindgesprek (weging 50% / individuele beoordeling)
Tijdens het eindgesprek worden er vragen gesteld over de groepsproducten. In het gesprek laat je zien dat je de gebruikte R code begrijpt en de keuzes voor de code kunt verantwoorden. Verder laat je in dit gesprek zien dat je de analyses kunt uitleggen en dat je de conclusies kunt onderbouwen.
Bij dit onderdeel worden de volgende leeruitkomsten getoetst:
- de student kan de achtergrond en het doel van het onderzoek uitleggen;
- de student kan de experimentele details van een RNA-seq dataset vertalen naar code voor de RNA-seq data analyse;
- de student kan in grote lijnen de verschillende stappen van de RNA-sequencing data analyse workflow uitleggen;
- de student kan de gebruikte code uitleggen en de gemaakte keuzes verantwoorden;
- de student kan de reproduceerbaarheid van de data analyse verantwoorden;
- de student kan de verkregen resultaten uitleggen;
- de student kan de conclusies en discussiepunten van de analyses uitleggen;
- en de student kan de suggesties voor vervolgonderzoek en/of verbeteringen van de analyse uitleggen.
Projectopdracht
In dit project ga je kijken naar gepubliceerde RNA-seq data voor verschillende weefsels in de mens. De complete dataset kun je vinden in de GEO database. Hieronder vind je een tabel met de verschillende weefsels die bestudeerd worden in dit project en de bestandnamen voor de ruwe databestanden (fastq bestanden).
| Weefseltype | Bestandnamen (fastq bestanden) |
|---|---|
| Lever | SRR7961208.fastq.gz / SRR7961209.fastq.gz / SRR7961210.fastq.gz |
| Nier | SRR7961196.fastq.gz / SRR7961197.fastq.gz / SRR7961198.fastq.gz |
| Hersenen | SRR7961214.fastq.gz / SRR7961215.fastq.gz / SRR7961216.fastq.gz |
Als groep ga je twee van de bovenstaande weefsels vergelijken om te bepalen wat de verschillen zijn in genexpressie tussen de twee weefsels. In de tabel hieronder staat aangegeven welke weefsels elke groep gaat vergelijken:
| Studentgroep | Weefsels |
|---|---|
| Groep 1 | Lever en Hersenen |
| Groep 2 | Lever en Nier |
| Groep 3 | Nier en Hersenen |
Het doel van het project is om de data analyse reproduceerbaar uit te werken in een Rmarkdown bestand. Dit bestand moet de code en de resultaten van de analyse bevatten. Het bestand moet gedeeld worden via GitHub met je tutor. De GitHub repository moet ook een README bestand bevatten, waarin is beschreven hoe een andere onderzoeker de code in het Rmarkdown bestand zelf uit kan voeren en wat daarvoor nodig is (bijvoorbeeld informatie over de te installeren packages en de benodigde data). Een andere onderzoeker moet het Rmarkdown bestand zonder problemen kunnen knitten tot een rapport (op de server). Zorg ervoor dat je de reproduceerbaarheid van je Rmarkdown bestand test en dat je eventuele problemen/foutmeldingen die bij een andere gebruiker optreden, oplost.