Appendix - Data Analyse in JASP
Lesinhoud en leerdoelen
Aan het einde van deze les kan je:
- data importeren en filteren in JASP
- beschrijvende statistieken uit JASP halen
- boxplots, errorbarplots, scatterplots en histogrammen maken in JASP
Voorbereiding
Soms is Excel best een boel werk. Kan dat niet makkelijker? Soms wel, soms niet. In ieder geval is Excel niet de enige software voor dataverwerking. We gaan in deze cursus ook werken met JASP. JASP is een open source statistisch programma gebaseerd op de R-taal die jullie in blok C/D leren gebruiken.
Excel wordt vaak gebruikt voor data-analyse. Excel is handig voor de eerste stappen bij het opschonen en ordenen van gegevens. Excel is ook erg handig als rekenmachine. Grotere data-analyse-projecten in Excel is echter vaak erg bewerkelijk en, nog belangrijker, data-analyse in Excel is niet reproduceerbaar. Je zou jezelf moeten filmen om alle stappen die je uitvoert bij te houden. Dat is natuurlijk niet haalbaar. Ook kan Excel geen grotere datasets aan, die we in de life sciences steeds vaker tegenkomen.
Daarom gebruiken de meeste mensen in het werkveld Excel vooral voor data invoeren, snel een paar grafiekjes maken, simpele analyses en beschrijvende statistiek.
Zodra projecten wat groter worden, gebruiken de meeste mensen software als JASP (deze cursus), SPSS (lijkt op JASP maar is niet gratis) of programmeertalen zoals R (cursus IBIP, blok C/D).
JASP kan op je computer worden geïnstalleerd vanuit het HU-softwarecentrum of anders vanaf de pagina JASP download.
kijk de video bovenaan deze site hier (klik)
Let op in de video hoe je:
- een dataset opent
- een tabel of grafiek kopieert
- notities toe kan voegen aan een analyse
data bewerken (niet) in JASP
JASP neemt een duidelijk standpunt in wat betreft data: je data is wat ’ie is, daar mag je niet zomaar aan gaan lopen rommelen. Je kunt daarom geen cijfers veranderen binnen het programma. Maar, als je toch een getal aan wilt passen of data toevoegen, kun je wel via JASP doorklikken naar het onderliggende .csv-bestand.
Kijk de video hier (klik) om te leren hoe.
Beschrijvende statistiek in JASP
We beginnen even met een voorbeeld-dataset bekijken.
- open JASP en klik linksbovenin op het hamburgermenuknopje
- kies voor open –> data library –> 1. Descriptives
- klik op de linker van de twee tabel-plaatjes, die met de J van JASP er in. Dan open je de data EN de analyses. Klik je op de rechter, dan open je alleen de data. Klik op de linker:
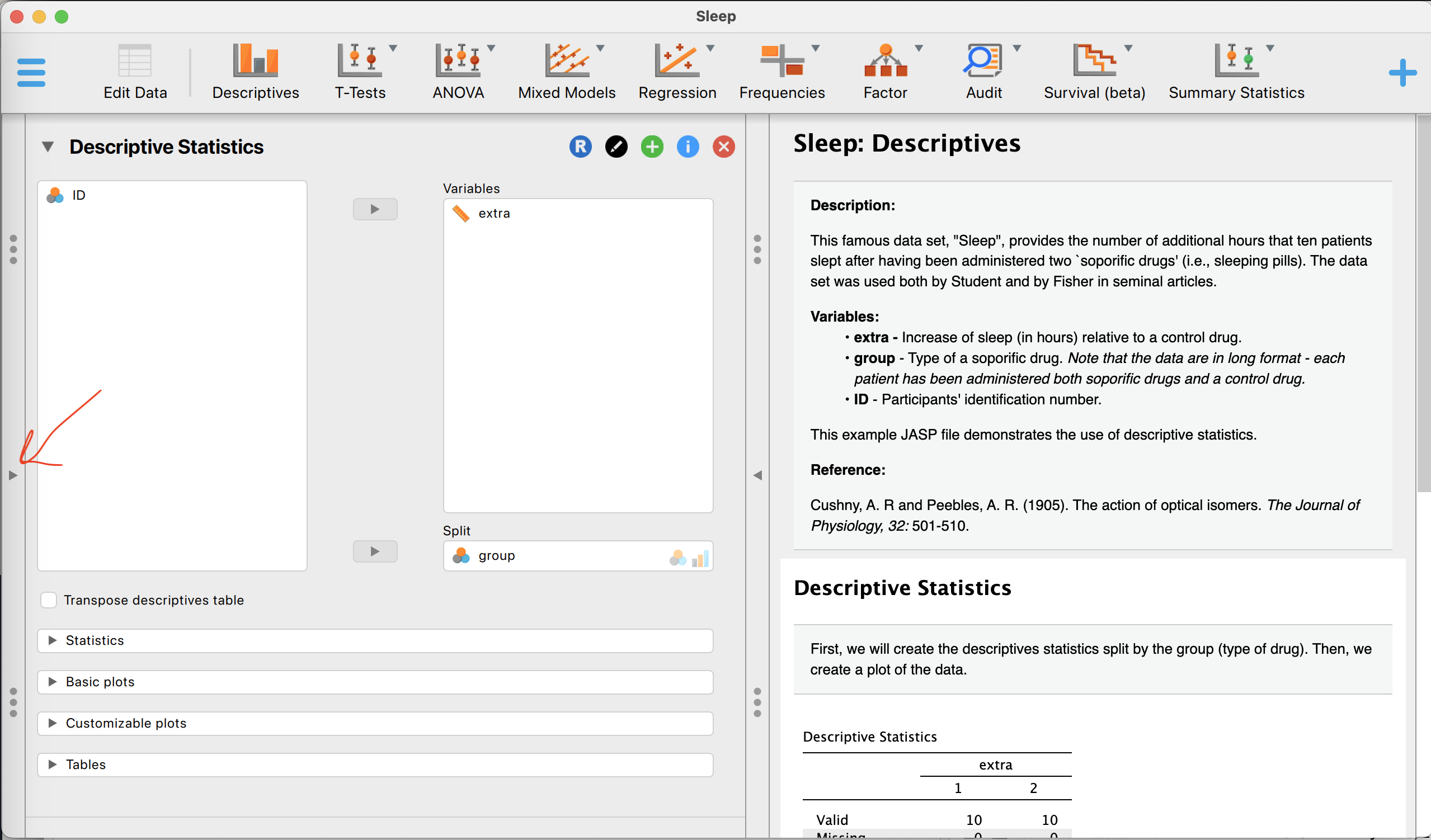
- je komt nu op het analyse-scherm. Links in beeld zie je de keuzes die je kan maken over analyses. Rechts in beeld zie je een uitleg, beschrijvende statistieken (descriptive statistics) en een grafiekje. Hier gaan we zo naar kijken.
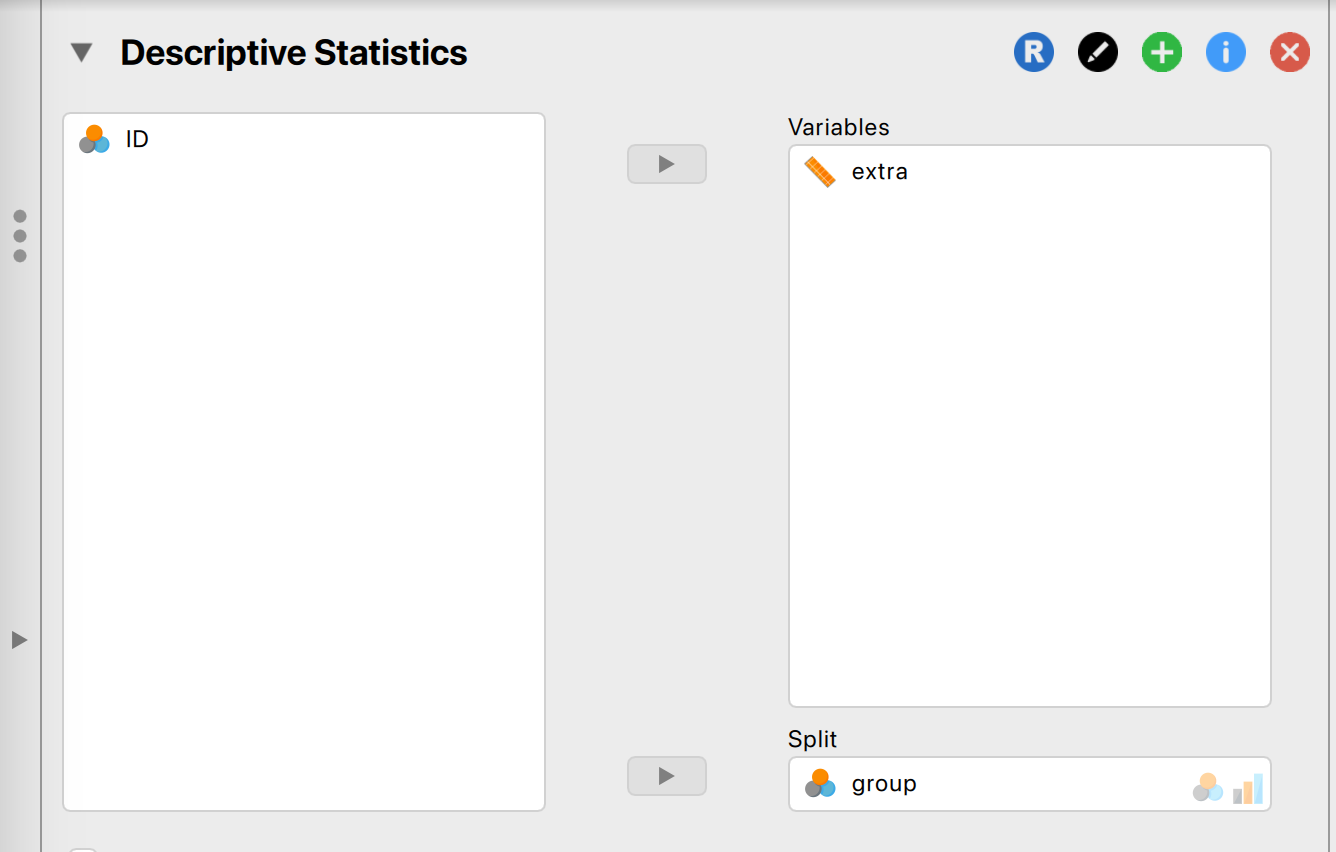
- Lees de uitleg van deze dataset bij “description” rechts in beeld. Zoals je ziet is dit een enorm oude (vintage!) dataset, hij wordt veel gebruikt in voorbeelden. Er zitten drie variabelen in.
- Links in beeld zie je dezelfde drie variabelen-namen weer. ID wordt in de analyses nu niet gebruikt, en PER group (split) wordt gekeken naar de AFHANKELIJKE VARIABELE (variables) extra.
- links in de rand van het scherm zit een pijlje. Je kunt hierop klikken om naar de data te gaan.
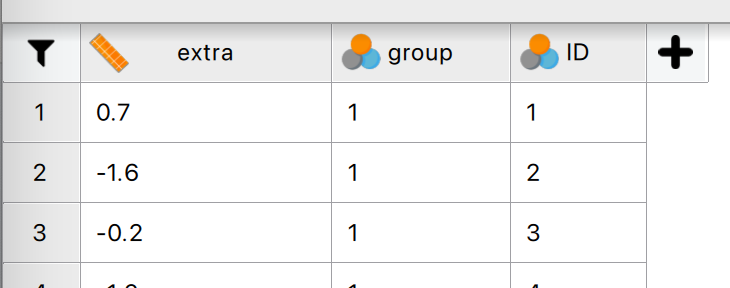
- Nu zie je drie kolommen voor de drie variabelen. Dit is duidelijk een tidy databestand. Patientnummer (1 tot 10) staat helemaal rechts.
- Elke kolomnaam begint met een pictogram dat het type gegevens aangeeft (nominaal, ordinaal of kwantitatief). Er is 1 kwantitatieve, continue variabele en twee kwalitatieve, nominale.
les_06_opdracht
Er is een probleem met dit databestand. “group” zegt niet zoveel. Welke pillen zijn gebruikt? In de data description staat ook niets. Oeps. hier is de bladzijde van het paper waar deze data uit komt. Kijk naar Table 1.
- is dit een gepaarde of ongepaarde proefopzet?
- Is deze tabel tidy?
- per pil zijn er drie kolommen. No of observations (hoeveel nachten is deze conditie getest bij deze patient), average hours of sleep en increase over controls. Die laatste kolom is de kolom die extra heet in de de JASP dataset. Hoe zijn deze getallen berekend?
Klik hier voor het antwoord
- gepaard. elke patient kreeg alledrie de pillen, maar op verschillende dagen.
- nee, bepaald niet. In their defence, toen dit paper geschreven werd in 1905 was machine readable data nog niet zo belangrijk.
- Deze getallen zijn berekend door de gemiddelde hoeveelheid slaap van deze patient zonder pil (kolom 3) af te trekken van de gemiddelde hoeveelheid slaap met pil (bijv kolom 5, om zo kolom 6 te berekenen).
Je kan zien dat patienten 3 verschillende slaaptabletten kregen, en een controle-conditie met geen tablet. De middelste twee pillen in de tabel zijn opgenomen in de dataset in JASP. Dat zijn hyoscyamine en laevo-hyoscine.
- ga terug naar JASP, en dubbelklik op de kolomnaam group. We hebben net ontdekt dat dat helemaal niet klopt, het waren geen verschillende groepen mensen. Het waren dezelfde patienten!
- Nu zie je ook de verschillende mogelijke waardes die “group” kan hebben: 1 en 2.
- Verander de naam van de variabele en de labels en klik op het rode kruisje rechtsboven in beeld:
“extra” is ook niet zo mooi. Verander deze variabelenaam in “extra_sleep_hours”.
klik weer op het pijltje in de zijbalk (nu rechts in beeld) om terug te gaan naar de analyses. JASP is de variabelen kwijt, want ze heten niet meer hetzelfde. Voeg de afhankelijke variabele toe aan het bovenste vak “variables”. Voeg de onafhankelijke variabele toe aan het vak “split”.
Klik hier voor het antwoord
In het tabelletje met beschrijvende statistiek (descriptive statistics) rechts, onder de uitleg, kun je zien dat in beide groepen 10 patienten zaten met bruikbare data (valid) en 0 missende datapunten. De gemiddelde extra hoeveelheid slaap bij gebruik van hyoscyamine was 0,750 uur, en bij laevo-hyoscine 2,330 uur, wel met flinke standaarddeviaties.
links in beeld kun je klikken op de regel “statistics”, dan klapt er een scherm uit waar je kunt kiezen wat er in deze tabel staat. Probeer er een paar uit.
Klik op het vinkje voor “median” en merk op dat het gemiddelde en de mediaan van deze data niet hetzelde zijn. Dat betekent dat de data niet netjes een normaalverdeling volgt.
Je kan ook het 95% betrouwbaarheidsinterval laten berekenen. Dat is relaxed! We kiezen voor het T-model, want er zijn minder dan 50 metingen:
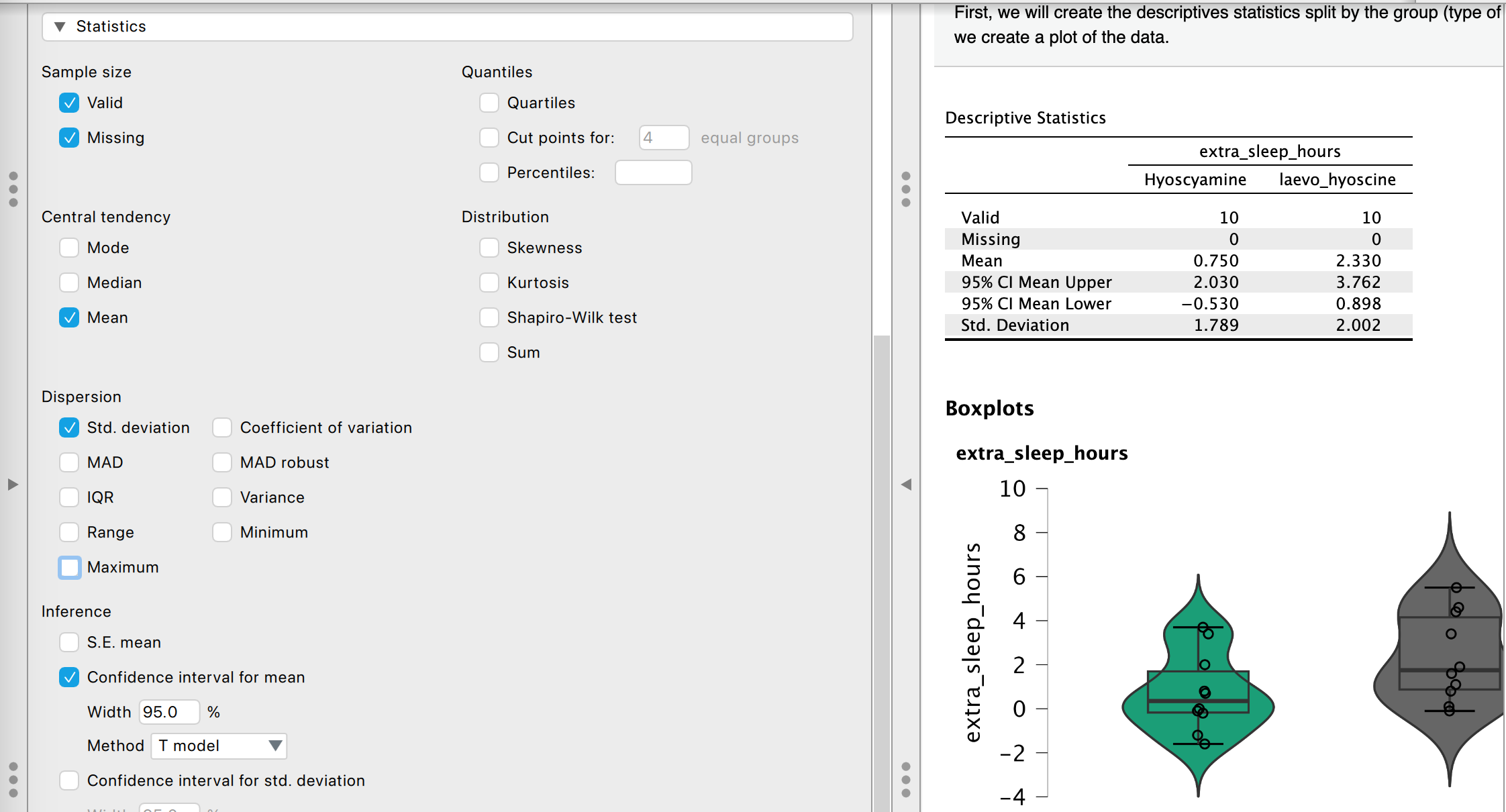
Even narekenen of ze kloppen hoor: hyoscyamine had gemiddeld 0,750 uur extra slaap met een standaarddeviatie van 1,789 en n=10. De bijbehorende t-waarde zoeken we op in de tabel op het formuleblad: 2,262. En \(0.750 \pm 2.262 * \frac{1.789}{\sqrt{10}}\) geeft een 95% BI van -0.52968 tot 2.02968. Klopt! Dat deed JASP sneller dan ik.
boven het tabelletje staat “descriptive statistics” met daarnaast een driehoekje. Als er geen driehoekje te zie is, ga dan met je muiswijzer bovenop de tekst staan, dan komt hij wel. Door op het driehoekje te klikken krijg je de keuze om de tabel te kopieren. Kopieer de tabel (gewoon, niet latex), en plak hem in een leeg Wordbestand. Dat ziet er meteen netjes uit voor in een verslag.
Nu gaan we kijken naar de grafiek. Die is nog een beetje een bende. Klik op het driehoekje naast de grafiektitel “extra_sleep_hours” en kies “edit image”.
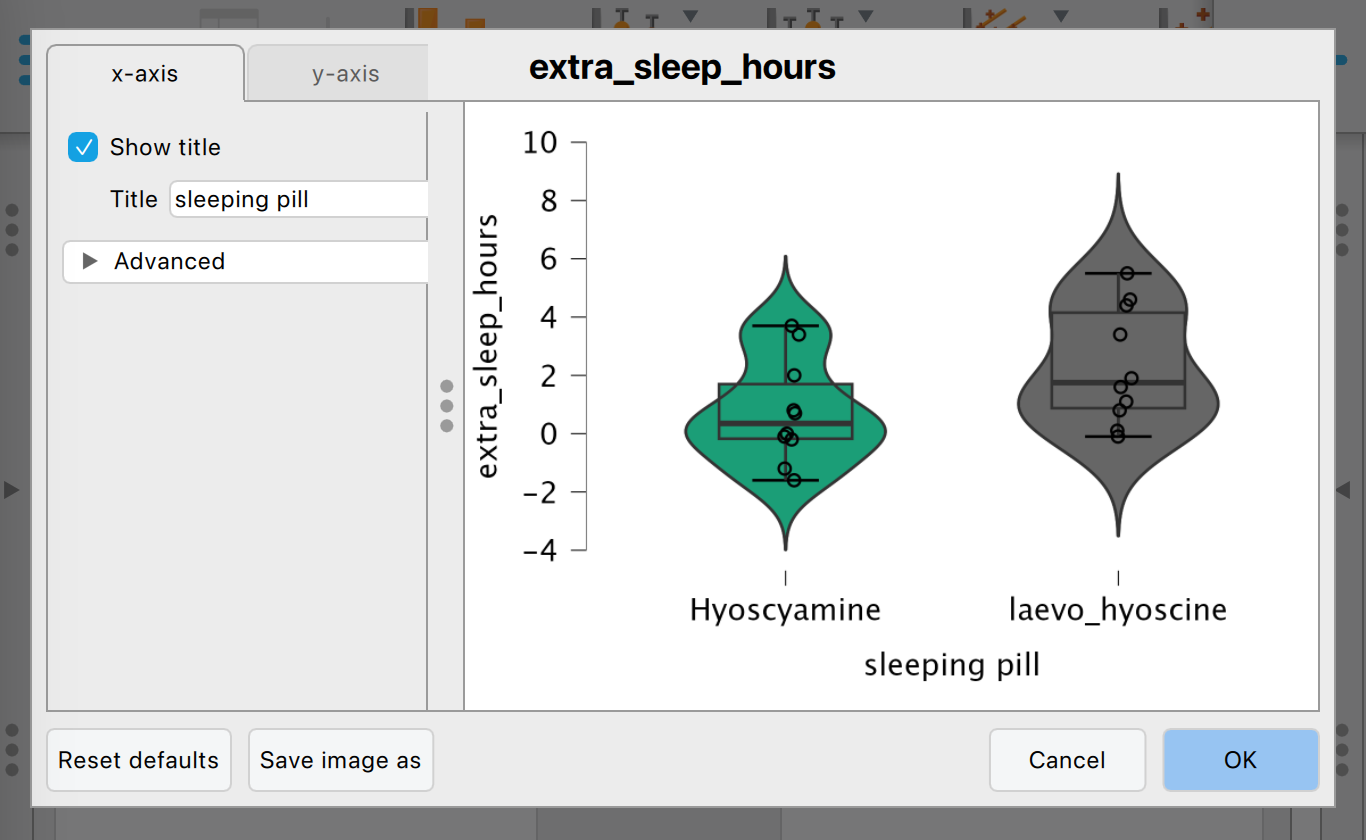 - verander in het tabblad y-axis het asbijschrift in “extra sleep (hours)” en sluit dit scherm weer.
- Nu hebben we nog een violin plot en een boxplot door elkaar heen. Klik links in beeld op de regel “customizable plots” en verwijder het vinkje bij “violin plot”. Nu heb je boxplotjes van de data! Ook die kun je weer kopieren via het driehoekje, of opslaan als een los bestand.
- De boven- en onderkant van de stokjes op de boxplot zijn hier anders dan in Excel. Excel had ze op 1,5 * IQR vanaf de box, JASP zet ze op het 5e en 95e percentiel van de data. Wil je dat controleren, klik dan in het scherm “statistics” het vinkje aan bij “percentiles” en vul 5 of 95 in. De randen van de box zitten weer op het 25e en 75e percentiel. En de streep in het midden zit op de mediaan.
- verander in het tabblad y-axis het asbijschrift in “extra sleep (hours)” en sluit dit scherm weer.
- Nu hebben we nog een violin plot en een boxplot door elkaar heen. Klik links in beeld op de regel “customizable plots” en verwijder het vinkje bij “violin plot”. Nu heb je boxplotjes van de data! Ook die kun je weer kopieren via het driehoekje, of opslaan als een los bestand.
- De boven- en onderkant van de stokjes op de boxplot zijn hier anders dan in Excel. Excel had ze op 1,5 * IQR vanaf de box, JASP zet ze op het 5e en 95e percentiel van de data. Wil je dat controleren, klik dan in het scherm “statistics” het vinkje aan bij “percentiles” en vul 5 of 95 in. De randen van de box zitten weer op het 25e en 75e percentiel. En de streep in het midden zit op de mediaan.
Gegevensfiltering
Ga terug naar het data-scherm.
Aan de linkerkant is het mogelijk om bepaalde categorieën te selecteren (filteren) door categorieën uit te vinken die je niet mee wilt nemen in de analyse. Klik op het filterknopje:
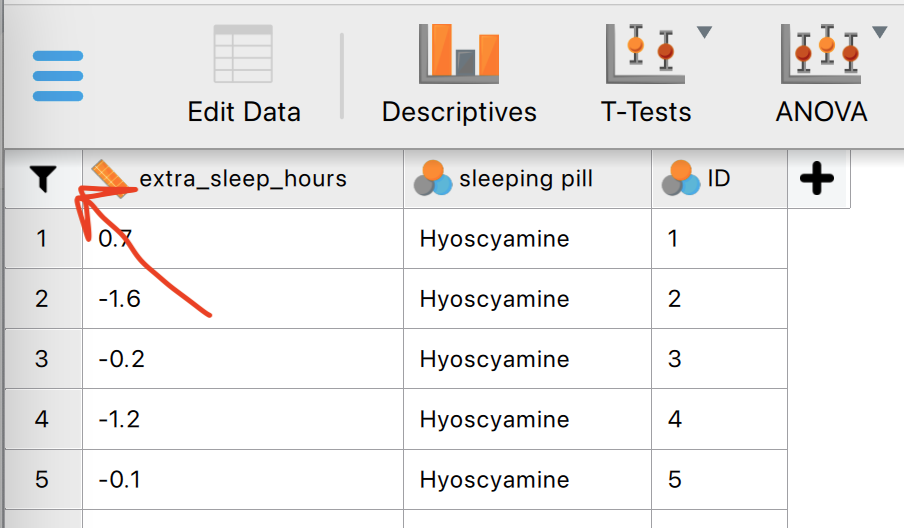
- Stel dat je alleen de data van hyoscyamine wilt zien, dan filteren we dus op de variabele “sleeping pill”. Sleep “sleeping pill” naar het formule-vakje in het midden. Sleep het “=” - teken er achter. Klik op de 3 puntjes achter de “=” en vul hyoscyamine in.
- Klik je per ongeluk een variabele twee keer in het formulescherm, klik er dan op met rechter muisknop om hem te verwijderen.
- Klik dan onderin het filterschermpje op “apply pass-through filter”. Als het goed is staat er nu “filter applied”.
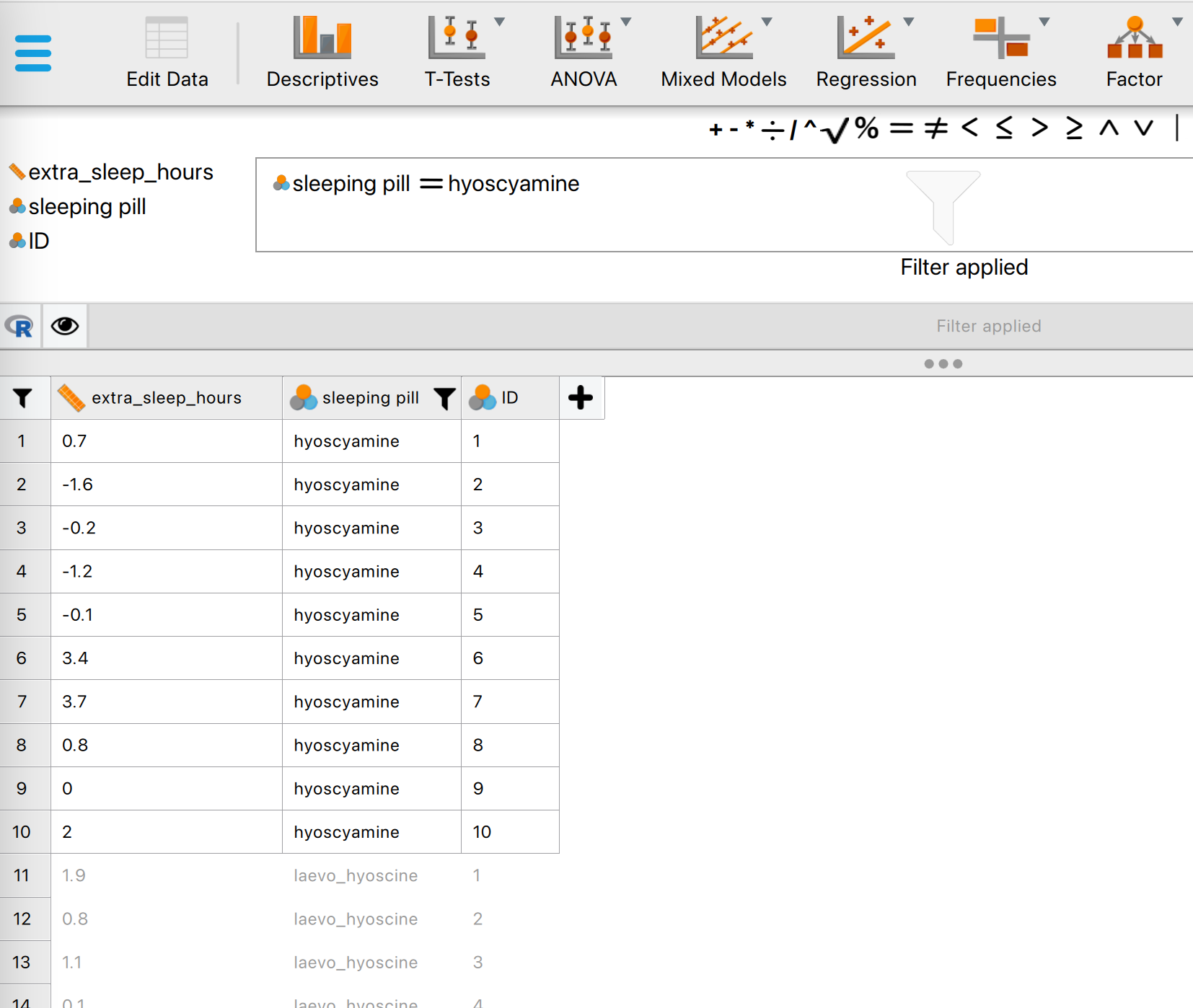
- Ga weer terug naar het analyse-scherm en kijk wat dit met de tabel en grafiek heeft gedaan. Je ziet nu alleen nog de beschrijvende statistiek van hyoscyamine.
Gegevens importeren
JASP accepteert verschillende soorten gegevensbestanden:
- JASP-bestanden
- txt-bestanden
- csv-bestanden (door komma’s gescheiden waarden)
- tsv-bestanden (door tabs gescheiden waarden)
- ods-bestanden (open documentspreadsheet)
(Dus geen xlsx-bestanden! Die zijn namelijk niet open source. Een xlsx-bestand is stiekem een soort programma.)
Ods-bestanden zijn afkomstig van libreoffice. Libreoffice is een gratis alternatief voor Microsoft Office om open wetenschap te promoten. We gebruiken deze bestanden in de cursus niet, maar mocht je in de toekomst tegenkomen dan weet je bij deze wat het is.
les_06_opdracht
download dit bestand(klik) en zet het in de map die je voor DAVE hebt gemaakt, in een/het mapje data.
Klik op het hambugermenuknopjes en dan op Open in de linkerbovenhoek van het JASP-venster.
Selecteer Computer –> browse –> en navigeer naar de locatie waar je je CSV-bestand hebt opgeslagen.
Selecteer het bestand jasp_ex1_data.csv en klik op Open.
Sla het bestand op als JASP bestand
Hoeveel variabelen heeft deze dataset, en wat voor soort?
Hoeveel mogelijkheden zijn er voor variabele haarkleur?
Wat is de gemiddelde lichaamslengte van mensen met paars haar?
Maak een boxplot van de lichaamslengte van mensen per haarkleur, maar laat de mensen met paars haar weg.
In welke groep zit een outlier?
Ziet het er uit alsof haarkleur uitmaakt voor iemands lichaamslengte?
sla je bestand op als JASP-bestand.
Klik hier voor het antwoord
- 6 kolommen:
- 1 identifier (id), onafhankelijke variabele die alleen maar aangeeft welke proefpersoon dit was.
- 5 afhankelijke variabelen, waarvan 1 nominaal (haarkleur), 1 discreet (leeftijd) en 3 continue. Leeftijd had natuurlijk continue kunnen zijn, maar is nu weergegeven in hele getallen dus je zou hem discreet kunnen noemen.
- 5 haarkleuren
- 169,558 cm
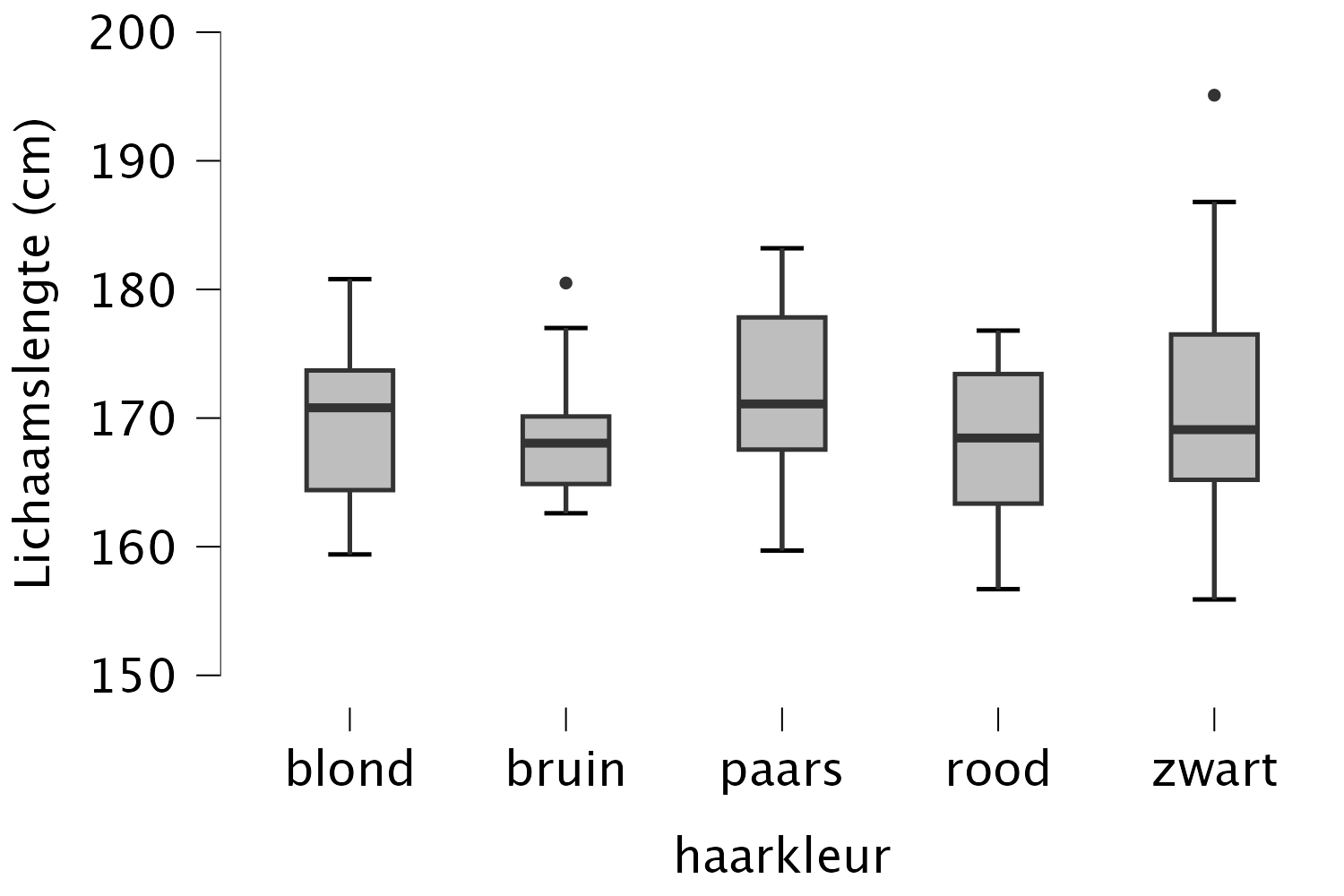
- De groep zwartharigen en de groep bruinharigen heeft een outlier, te herkennen aan het stipje buiten de boxplot.
- Het ziet er niet uit alsof haarkleur uitmaakt voor lichaamslengte
Scatterplot in JASP
Gebruik de data van de vorige opdracht. Open het JASPbestand. We gaan een scatterplot maken.
- begin met het filter weer uitzetten. Mensen met paars haar horen er ook bij. Klik op het filterknopje in het datascherm. Dubbelklik op de prullenbak. Sluit het filter-scherm met het rode kruisje.
- klik linksbovenin op “descriptives. Je krijgt nu een nieuw blokje”descriptive statistics” in het analyse-scherm.
- zet voetlengte en lichaamslengte in het vakje met variabelen.
- klik op de regel “customizable plots”, vink “scatter plots” aan
- Dit is geen regressie, dus we willen geen lijn. Klik “add regression line” uit.
- pas de asbijschriften
les_06_opdracht
Ziet het er uit alsof er een verband is tussen voetlengte en lichaamslengte?
Klik hier voor het antwoord
ja, op zich wel. Punten met relatief hogere waarden op de x-as hebben ook meestal relatief hoge waarden op de y-as.
les_06_opdracht
Betekent dat dat het hebben van een langer lichaam leidt tot het hebben van grotere voeten?
Klik hier voor het antwoord
Nee. Een verband betekent niet dat het ene het gevolg is van het andere. Ze kunnen beide bijvoorbeeld het gevolg zijn van een derde factor, zoals in dit geval de hoeveelheid groeihormonen. Korter gezegd: correlatie is geen causatie. Check ook dit plaatje voor een verheldering.
{kind=link}
les_06_opdracht
Wat denk je dat die density-plots betekenen?
Klik hier voor het antwoord
Hoeveel van de datapunten op die hoogte van de as zitten. Je kunt zien dat beide variabelen grofweg een normaalverdeling volgen: symmetrisch klokvormig, met de piek in het midden.
histogram
Laten we een histogram maken voor beide variabelen om te controleren.
- open de basic plots regel. vink “distribution plots” aan. JASP maakt meteen een histogram voor je.
Op de x-as zie je de verschillende voetlengtes / lichaamslengtes. Er is een staaf per “bin” (breedte van de staaf), die aangeeft hoeveel datapunten daar geteld zijn. Dus er zijn bijvoorbeeld ongeveer 11 a 12 voetlengtes tussen de 22 en 24 cm. Zorg dat je dat terug kan vinden in de grafiek.
les_06_opdracht
Open een nieuw descriptive statistics scherm (klik links bovenin).
- Maak een histogram voor haarlengte.
- zet bin width type op manual
- kies 20 bins.
Is dit normaal verdeelde data?
Klik hier voor het antwoord
Nee. Je ziet niet een symmetrische klokvorm met de bult in het midden, maar een verdeling met twee, deels overlappende bulten. Dat heet een bimodale verdeling.
Nieuwe variabelen aanmaken
Binnen JASP kunnen we een nieuwe variabele berekenen op basis van bestaande variabelen. Hier berekenen we de bmi, die je berekent met lichaamslengte en gewicht volgens de formule:
BMI = gewicht (kg) / (lengte (m) x lengte (m))
- We hebben dus eerst lengte in meter nodig, hij staat nu in centimeter. Ga naar het datascherm en klik op het + teken naast de laatste kolom om een nieuwe kolom toe te voegen.
- Vul de naam van de kolom in. In dit geval “lengte_m” , en kies scale. Klik op “Kolom maken”
- Je hebt nu een nieuwe kolom, maar er staat nog niets in. Dubbelklik op de kolomheader.
- Bereken de lengte in meter door de variabele lengte_cm in het formulevak te slepen en te delen door 100. Klik op “compute column” / “Kolom berekenen”
- Klik op het zwarte kruis (rechtsonder in het formulevak) om het formulevenster te sluiten
Maak nu een nieuwe kolom aan met het BMI per proefpersoon.
- maak een nieuwe kolom met titel “BMI”
- open het formulescherm, en klik eerst op / en *. Je krijgt nu de juist symbolen al in het scherm, en kunt de variabele op de goede plek slepen (wacht met loslaten tijdens het slepen tot het groene vakje op de goede plek verschijnt.) tip: rechter muisknop om verkeerd geplaatste variabelen te verwijderen.
- rechts in het scherm staan ook nog veelgebruikte bewerkingen die je kunt gebruiken, zoals max(y) (de maximumwaarde van een variabele) of mean(y) (het gemiddelde van een variabele). Deze hebben we nu niet nodig.
les_06_opdracht
Wat is de laagste BMI in de groep?
Klik hier voor het antwoord
maak een nieuwe descriptives tabel aan. Het minimum is 20,381.les_06_opdracht
WIE (welk proefpersoonnummer, id) heeft de laagste BMI in de groep?
Klik hier voor het antwoord
Filter de kolom BMI op BMI = min(BMI) (kies min(y) rechts uit de lijst in het filterscherm.)
Proefpersoon 66 blijft over.staafgrafiek
JASP doet nog geen staafgrafieken. Hij kan wel errorbar-grafieken maken.
- klik rechtbovenin op het grote blauwe plusje en vink “visual modelling aan”
- in de balk boven, kies visual modelling –> flexplot
- vul haarkleur in als independend variable, en een van de continue variabelen (zoals lengte_cm) als dependent variable.
- klik op de options regel, en kies bij “intervals” voor “standard deviations”/
- Nu laat de grafiek in het rood de gemiddelden en standaarddeviaties zien. Wil je de puntjes uit, zet dan de point transparency op 0.
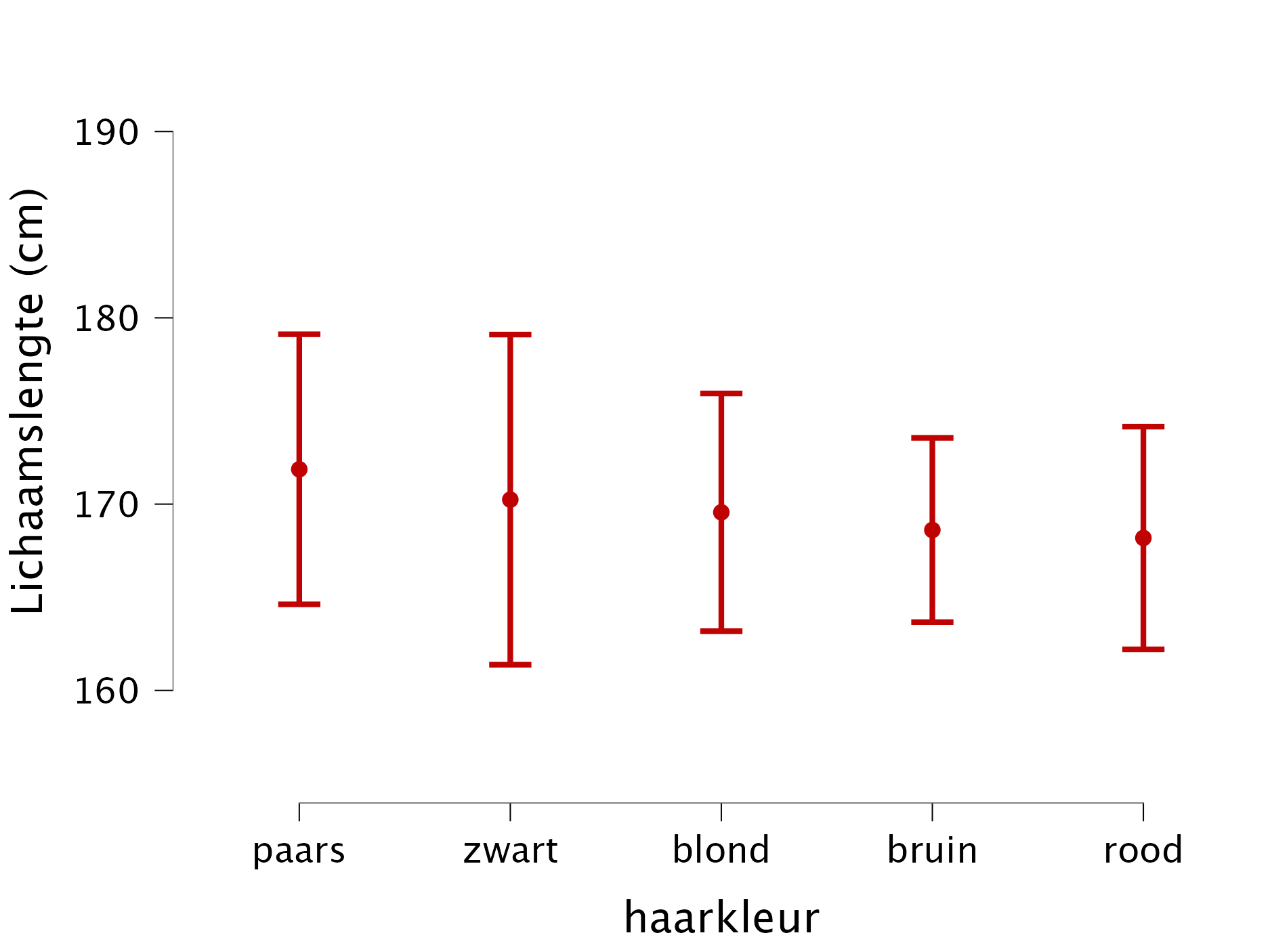
Werkcollege
deel 1
De dataset die we vandaag gebruiken heeft 6 variabelen waarvan 1 identifier:
- id: Een unieke ID voor elke proefpersoon (1 tot 100).
- Condition: Een nominale variabele met twee mogelijke waarden: “Baseline”, “Post-Treatment”.
- Experimenter: Een nominale variabele met drie mogelijke waarden: “Experimenter_A”, “Experimenter_B”, “Experimenter_C”.
- GlucoseLevel: Een continue variabele in mg/dL
- HeartRate: Een continue variabele in slagen per minuut.
- BloodPressure: Een continue variabele mmHg kwikdruk.
- Open JASP en laad de dataset werkcollege_les6.csv (klik)
- De hartslagmeter bleek verkeerd geijkt in het experiment en mat 2 tellen te hoog (wat voor soort meetfout is dat?). Maak een nieuwe kolom aan met de juiste hartslagmetingen.
- Maak een scatterplot van GlucoseLevel versus Bloodpressure. Bekijk en bespreek het verband tussen deze twee variabelen.
- Maak een histogram van glucoselevels. Zijn ze normaal verdeeld?
- Hoeveel proefpersonen hadden in de baseline-conditie een hartslag van onder de 70 slagen per minuut?
- Voor de baselineconditie: Bereken per experimenter het gemiddelde de standaarddeviatie van bloeddruk. Bereken ook de 95% betrouwbaarheidsintervallen. Maak boxplots van bloedruk in de baselineconditie per Experimenter. Denk je dat Experimenter uitmaakte in dit experiment?
- Bereken het gemiddelde en het 95% betrouwbaarheidsinterval voor GlucoseLevel per Condition groep. Had de “treatment” denk je effect op glucoselevels?
deel 2
Open in JASP het bestand voor deze opdracht: werkcollege_les6_deel2
Dit bestand bevat meerdere datasets, met namen zoals “away”, “bullseye” etc. Alle datasets hebben een x-variabele en een y-variabele, laten we zeggen dat ze uit verschillende labs komen.
- Bekijk de gemiddelden en standaarddeviaties van deze datasets. Wat valt je op?
- Denk je dat de verschillende labs dus vergelijkbare data hebben?
- Filter de data zodat alleen dataset “away” over houdt.
- maak een scatterplot voor x vs y voor dit lab. bekijk de scatterplot
- Doe nu hetzelfde voor dataset “dino”
- wat is je conclusie?
- bekijk nog een paar datasets om je conclusie te controleren.
Bron data: Locke, S. & McGowan, L. D. A. (2018). datasauRus: Datasets from the Datasaurus Dozen. R package version 0.1.4. https://CRAN.R-project.org/package=datasauRus