3: Data management
Lesinhoud en leerdoelen
Deze les gaat over het beheersen van de chaos van al je databestanden en gerelateerde informatie. En over hoe je dat dan op zo’n manier doet, dat je werk ook over een paar maanden nog bruikbaar is voor jezelf of voor je collega’s.
Aan het einde van deze les kan je:
- data van een project reproduceerbaar opslaan;
- de metadata van een project verzamelen en documenteren;
- en verschillende soorten data herkennen en visualiseren.
Voorbereiding
Misschien herken je je in de volgende situatie. Samen met drie andere studenten werk je aan een project. Jullie hebben gegevens verzameld in Excel en zijn lekker aan het analyseren geslagen. In een Word document vermelden jullie de gevonden gemiddeldes en plakken een mooie staafdiagram. Je houdt lekker herfstvakantie en na de vakantie komt de feedback van je docent: goed op weg! Maar je zou wel die foutenbalken van de grafiek even net anders moeten doen.
Je opent je laptop om aan de slag te gaan. Maar helaas, op onedrive staan drie versies van het excel-bestand. Welke was ook al weer de laatste? En van welke data was dat grafiekje ook al weer? Waren die foutenbalken nou standaarddeviaties of wat anders? Je groepsgenoot had het grafiekje gemaakt, maar die is nog op vakantie. Het kost je een uur en twintig whatsappjes om uit te vogelen hoe hij die grafiek precies gemaakt had.
Nou is dit allemaal nog op te lossen met wat appjes, maar hoe moet dat als de groep na jullie naar jullie data wil kijken? Of je docent, over een half jaar? Of over twee jaar? Hebben ze dan alle informatie die ze nodig hebben of zouden ze je eigenlijk even moeten bellen voor uitleg?
De meeste data die je in je leven gaat verzamelen is niet voor de lol, om te oefenen, of omdat docenten dat zo graag lijken te willen. De meeste data gaat “voor het echt” zijn. Een patient zit er op te wachten, een onderzoek hangt er van af, je protocoloptimalisatie wordt erdoor getest. Vaak moet je meteen iets met die data, maar ook over een jaar nog een keer. En vrijwel altijd werk je niet alleen: andere mensen moeten ook iets kunnen met jouw data.
Gegevens (of het nou in de vriezer is of op een computer) zijn heel waardevol. Maar iemand anders niet kan zien wat de nummers in een tabel precies betekenden, of wat er in dat epje in de vriezer zit, zijn ze waardeloos geworden zodra jij je telefoon niet opneemt. Dan had je al dat werk net zo goed niet kunnen doen. Het is dus belangrijk om goed te leren hoe je opslag en verwerking van materialen en gegevens het beste kunt doen!
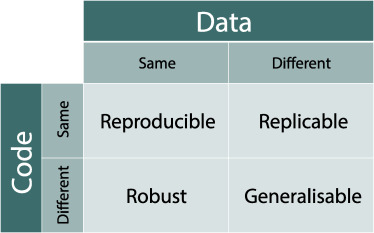
Repliceerbaarheid en reproduceerbaarheid
In life sciences is repliceerbaarheid en reproduceerbaarheid cruciaal. Dit betekent dat andere onderzoekers in staat moeten zijn om jouw experimenten te herhalen, en ook dat ze met jouw gegevens dezelfde uitkomsten moeten kunnen krijgen.
De termen repliceerbaarheid en reproduceerbaarheid worden heel vaak verwisseld, maar ze zijn niet hetzelfde. Wij houden deze definities aan, die van de American Statistical Association:
- Je experiment is repliceerbaar (oftewel herhaalbaar) als iemand anders het precies zo na zou kunnen doen om nieuwe data te verzamelen. Van belang hiervoor zijn de materiaal en methoden van je verslag, het goed volgen en rapporteren van je protocollen, en goed bijhouden van je labjournaal.
- Je werk is reproduceerbaar als je iemand anders je data zou kunnen sturen en een uitleg van wat je precies aan analyses hebt gedaan, en die iemand kan daarmee precies jouw resultaten en grafieken namaken.
Een voorbeeld
Laten we een voorbeeld bekijken. Jij onderzoekt of persoon A bloedarmoede heeft. Je voert een experiment uit, verzamelt data, en vindt een heel laag hemoglobinegehalte. Je concludeert dat persoon A waarschijnlijk bloedarmoede heeft.
Je mailt je databestand naar een collega. Die kan je analysestappen herhalen en vindt ook een laag hemoglobinegehalte. Je werk was dus reproduceerbaar.
Persoon A wil een second opinion. Een andere collega wil het testje wel herhalen en neemt een nieuw bloedsample. Zij voert hetzelfde experiment uit, volgens de stappen in jouw verslag, en verzamelt nieuwe data. Ze vindt ook een laag hemoglobinegehalte. Je werk was repliceerbaar.
Waarom zijn reproduceerbaarheid/repliceerbaarheid belangrijk?
Maatschappelijke aspecten
Reproduceerbaarheid en repliceerbaarheid zijn heel belangrijk voor het vertrouwen in de wetenschap. Zo verhoogt het herhalen van experimenten (repliceerbaarheid) het vertrouwen dat je kunt hebben in een bepaald resultaat. Het geeft anderen de mogelijkheid om je te controleren en ook om zelf daarmee verder te werken. Op deze manier kan wetenschap voortbouwen op eerdere resultaten en hypotheses verder testen, wat uiteindelijk kan leiden tot nieuwe ontdekkingen en inzichten.
Een belangrijk aspect van reproduceerbaarheid is dat het de mogelijkheid biedt om valsspelers te ontmantelen. Helaas zijn er gevallen geweest waarin onderzoekers valse gegevens hebben gepubliceerd, of resultaten hebben gemanipuleerd, of vals gespeeld met analyses om hun hypotheses te ondersteunen. Door analyses te reproduceren, kunnen andere wetenschappers controleren of de gerapporteerde resultaten wel echt kloppen.
Persoonlijk voordeel
Maar naast deze ideologische overwegingen is er is nog een belangrijk aspect: ‘future you’ (jij in de toekomst). ‘Future you’ moet heel vaak werken met jouw spullen, data, bestanden en informatie. En je hebt er heel direct last van als ‘future you’ werk opnieuw moet doen omdat ‘present you’ het niet reproduceerbaar opgeslagen heeft. En het is zonde van de tijd.
Reproduceerbaar werken
Een belangrijke voorwaarde voor reproduceerbaar werken is dat we onze data netjes opslaan op onze computer, zodat de data toegankelijk is voor anderen en voor ‘future you’. Dit betekent dat de opslag voldoet aan de regels voor data management. In de rest van de les gaan we kijken wat dat betekent en hoe je dit zelf het beste in de praktijk kunt brengen.
Data management
Hieronder bespreken we de verschillende onderdelen van goed data management.
Een map voor elk onderzoeksproject
Op je computer is data opgeslagen in mapjes. Maar wanneer maak je een nieuw mapje aan en wat moet er in zo’n mapje staan? We houden hiervoor het Guerrilla Analytics-framework aan, zoals beschreven door Enda Ridge in dit boekje. Dit betekent dat we voor data management denken in projecten, niet in taken. Elk onderzoeksprojectje wat je uitvoert (bijvoorbeeld een vaardighedenles en een data analyse casus) wordt een mapje op je computer.
Voor een cursus als DAVE geldt dat de cursus zelf een project is, maar dat binnen de cursussen er weer aparte projecten zijn (bijv. vaardighedenlessen). De mappen zouden dus als volgt kunnen zijn:
- experiment enzymactiviteit alphaglucosidase
- experiment lever homogeniseren
- casus werkcollege 1
- casus werkcollege 2
- casus werkcollege 3
- …
Elke map heeft dezelfde opbouw
Elke projectmap bevat standaard de volgende onderdelen:
Een map ruwe data: een map met alle ruwe data. Dit is de data zoals die op het lab is verkregen. De data kan afkomstig zijn van een apparaat of zijn ingevoerd door mensen. Bij voorkeur is voor alle data ook metadata aanwezig (zie hierna).
Een map data: deze map bevat alle data die gebruikt is in de analyses. Deze data is vaak een bewerkte versie van de ruwe data.
Een map analyse: al je Excel bestanden (of andere analysebestanden, zoals Jasp bestanden of R scripts).
In deze fase van de opleiding gebruiken we Excel zowel voor het vastleggen van data als voor het analyseren van data. In dat geval is de bovenstaande indeling minder van toepassing. Hieronder vind je meer informatie over data management met enkel Excel.
Metadata
Metadata is data over data. De antwoorden op de onderstaande vragen zijn onderdeel van de metadata:
- Wie heeft het experiment uitgevoerd?
- Welk protocol is gebruikt op het lab?
- Wanneer is het experiment uitgevoerd?
- Waar is het experiment uitgevoerd?
- Wat was de temperatuur in het lab toen het experiment werd uitgevoerd?
- …
Metadata is van belang om data van verschillende experimenten met elkaar te kunnen vergelijken. Als de temperatuur op het lab in experiment A heel anders is dan die in experiment B, dan kunnen de resultaten ook anders zijn (als dat wat je gemeten hebt tenminste afhangt van de temperatuur).
Oude versies staan in submappen
De afspraak is dat de data die in de mappen ‘ruwe data’ en ‘data’ staat altijd de laatste versie is. Heb je ook een oudere versie, dan maak je in de juiste map een submap ‘versie_1’ (of ‘versie_2’, of ‘versie_3’ etc.) en daar stop je de oude versie in. Op deze manier is het bestand direct in de datamap altijd de laatst bijgewerkte versie.
Opdracht 3
Kijk eens naar het volgende bestand:
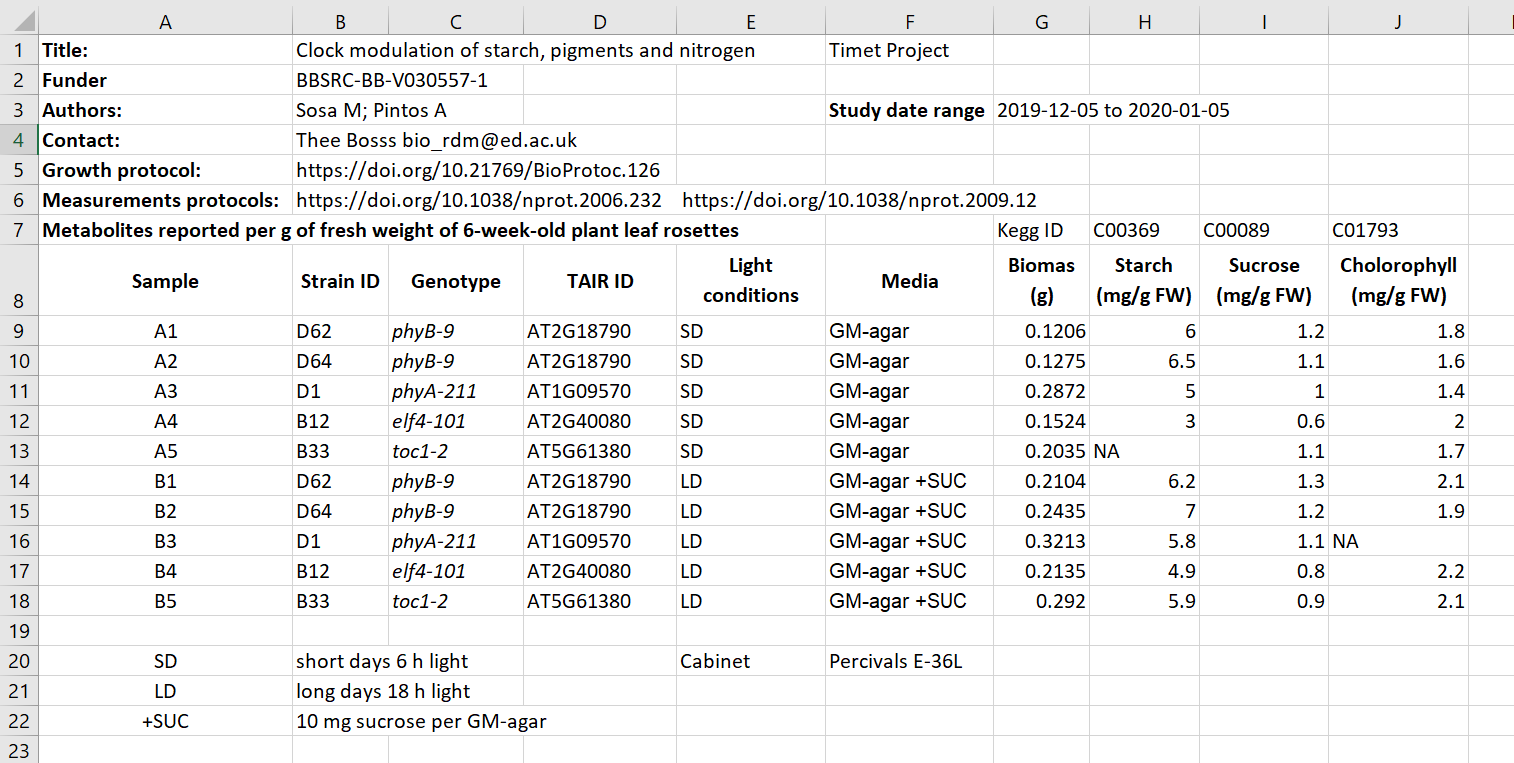
Figure 38: Figure credits: Tomasz Zielinski and Andrés Romanowski
Bron: FAIR in (biological) practice. Licensed under CC-BY 4.0 2022. Of specifiek Exercise 1: Identifying metadata types out of context.
- Kun je de metadata vinden?
- Waar zou je de metadata beter kunnen neerzetten?
- Zie je de missing data?
Klik hier voor het antwoord
- in rijen 1 t/m 7, en 20 t/m 22
- liever in een apart tabblad
- missing data in cel H13 en J16. “NA” betekent “not available”
Data management met Excel
In deze fase van de opleiding gebruiken we Excel voor data opslag en voor data analyse. We kunnen de principes van data management dan toepassen binnen één Excel bestand door gebruik te maken van drie verschillende tabbladen:
- metadata tabblad: een tabblad met daarin de metadata voor je experiment.
- ruwe_data tabblad: een tabblad met alle ruwe data (dus alle cijfertjes zoals jij ze op het lab genoteerd hebt of zoals ze uit een apparaat kwamen rollen).
- dataverwerking tabblad: alle data waar je al iets mee gedaan hebt en de bijbehorende grafieken/uitkomsten van berekeningen. Zodra je in je excelbestand iets gaat veranderen, berekenen of grafiekjes gaat maken, noem je het niet meer de ruwe data. Doe dat dus in een ander tabblad in excel, genaamd “dataverwerking”.
Om het eenvoudiger te maken om deze structuur aan te houden voor al je experimenten, hebben we een Excel template gemaakt die je kunt gebruiken. Je kunt de Excel template hier downloaden:
Opdracht 3
Gegeven de inhoud van het ruwe_data tabblad:
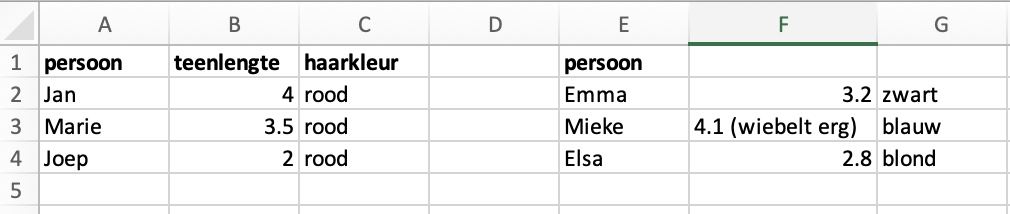
Waarom is dit geen nette excelsheet?
Klik hier voor het antwoord
Het is geen nette Excel sheet vanwege de volgende punten:
- twee kolommen hebben geen kolomheader. Is dat ook teenlengte? Of misschien wat anders?
- Kolomheaders worden herhaald (persoon).
- Het is onduidelijk wat de eenheid is voor teenlengte.
- Er staat een notitie in dezelfde cel als een datapunt. Dat zorgt ervoor dat je niet meer automatisch met dat datapunt kunt rekenen.
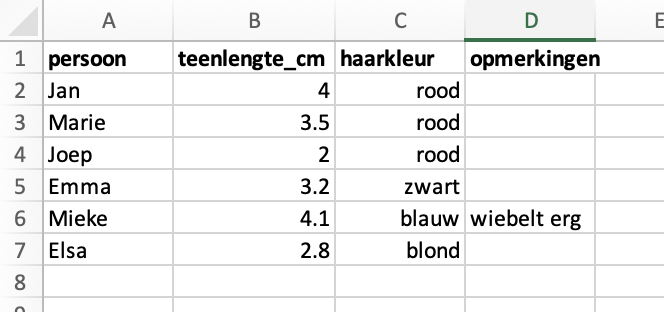
Dit zou beter zijn:
Tips voor goed data management
- Als je een verslag inlevert, lever dan ook je excelbestand met data en verwerking in.
- Je excelbestand heeft minstens de volgende tabjes: metadata, ruwe_data, en dataverwerking (zie ook het Excel template).
- Pas nooit je ruwe data aan, zodat je altijd terug kunt vinden wat je precies op het lab opgeschreven hebt.
- Zorg dat elke kolom in excel waar gegevens in staat, voorzien is van een kolomheader die aangeeft wat er in die kolom staat.
- Herhaal kolomheaders niet. Twee kolommen mogen niet dezelfde header hebben. Dus heb je gewicht gemeten van groep A en groep B, en wil je die echt naast elkaar zetten in Excel, dan hebben ze kolomnamen “gewicht_groepA” en “gewicht_groepB”. Zelfs al staat er een kolom “groep” naast. Dit voorkomt dat bij automatisch inlezen (AI), je data onbruikbaar wordt.
- Zorg dat je data kopieert en niet overtypt. Overtypen zorgt voor fouten.
Dataproblemen (en oplossingen) in Excel
Probleem 1: meerdere tabellen in 1 tabblad
Een voorbeeld van dit probleem zie je hieronder:
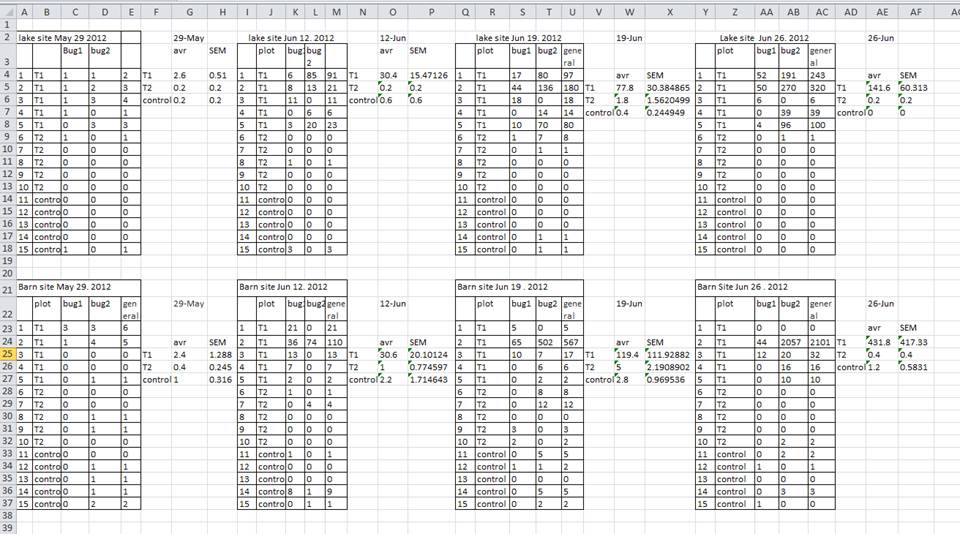
Oplossing: probeer 1 tabel per tab te gebruiken. Moet je dan 40 tabjes aanmaken, dan heb je waarschijnlijk eigenlijk meer kolommen nodig en niet meer tabjes.
Probleem 2: onduidelijkheid over nullen en “missing values”
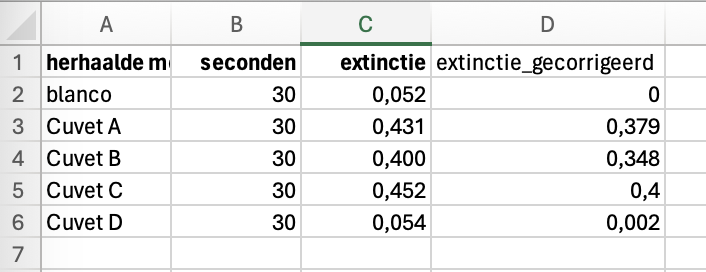
Welke van de volgende datapunten in de kolom “extinctie” zijn niet gemeten? Is die 0 echt nul, of is hij niet gemeten? En die lege cel, is die niet gemeten? Want ergens anders staat expliciet “niet gemeten”.
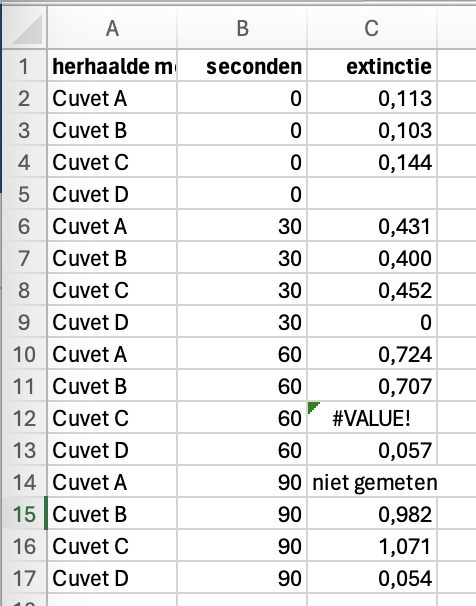
Oplossing: vul NA in als een datapunt mist (Not Available). De meeste programmeeertalen herkennen dit als missing value. Vul zeker geen getal in, ook niet nul (nul betekent al iets!).
Probleem 3: opmaak gebruiken om informatie over te brengen
In de volgende screenshot zie je dat de achtergrondkleur van de cel iets betekent. Dat kan een computer ook niet zomaar lezen. Bovendien kan het heel verwarrend zijn. Wat betekenen bijvoorbeeld de rode letters?
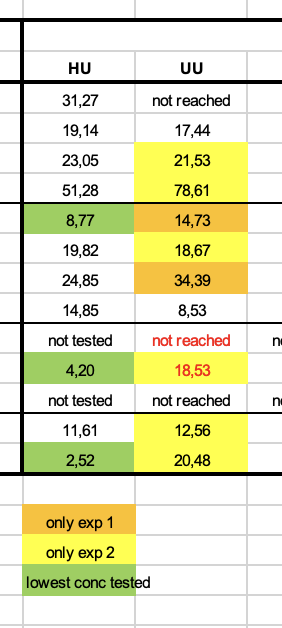
Oplossing: wil je meer informatie geven, voeg dan een kolom toe. Geen kleurtjes. Kleurtjes in excel mogen, maar alleen voor de sier en niet om informatie mee weer te geven.
Probleem 4: meer dan één waarde in een cel
Bijvoorbeeld een cel met 125 gram bevat zowel de waarde “125”, als de eenheid “gram”. Dat is een probleem, want excel kan er dan niet meer mee rekenen.
Oplossing: voeg de eenheid toe aan de kolomnaam. Bijvoorbeeld gewicht_gram in plaats van gewicht.
Probleem 5: excel comments
Oplossing: gebruik gewoon geen excel comments!
Probleem 6: getallen zijn ingelezen als tekst
Worden je getallen als tekst gezien, dan kun je er niet meer mee rekenen in excel. Excel zegt dan #VALUE!.
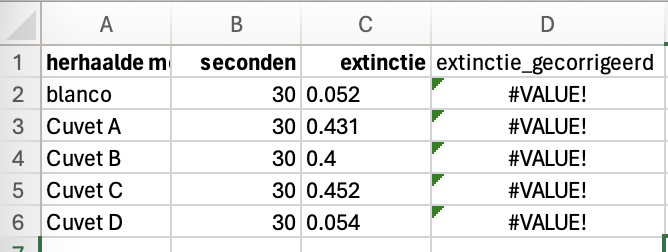
Oplossing: controleer of getallen echt als getallen worden gezien. Getallen worden in excel rechts uitgelijnd, terwijl tekst links wordt uitgelijnd. Mocht dat niet het geval zijn, dan komt dat vaak doordat de ‘decimal separator’ niet correct is. Je kunt het onderstaande stappenplan gebruiken om dit op te lossen:
- Selecteer de cellen die je wilt aanpassen
- klik in het data tab bovenin op “text to columns”
Je krijgt hetzelfde schermpje als bij data importeren. Je doet dus ook verder hetzelfde:
- klik twee keer op
nexten dan opadvanced
- Kies de “decimal separator” zoals hij nu (problematisch) in je bestand staat. Excel zal die dan om gaan zetten in wat excel wel als decimal separator ziet. Dat heb je aan het begin van de cursus ingesteld. Klik
oken daarnafinish.
Data sorteren
Soms heb je data in kolommen staan in een volgorde die je niet bevalt. Alles door elkaar bijvoorbeeld.
Wil je data in kolommen sorteren, dan kan Excel dat voor je doen.
Download hier de data om mee te doen.
In het eerste werkblad zie je de data van de screenshots hieronder. Doe mee met de volgende stappen:
Selecteer de tabel die je wilt sorteren. Let op: de hele tabel!! niet alleen de kolom waarop je wilt sorteren.
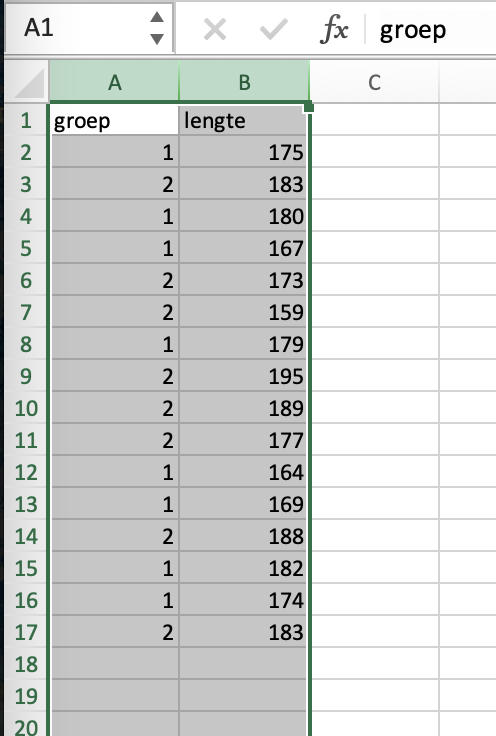
Klik op het tabblad Data op het knopje Sort
Selecteer bij Column de kolom op basis waarvan je wilt sorteren (in dit geval: groep):
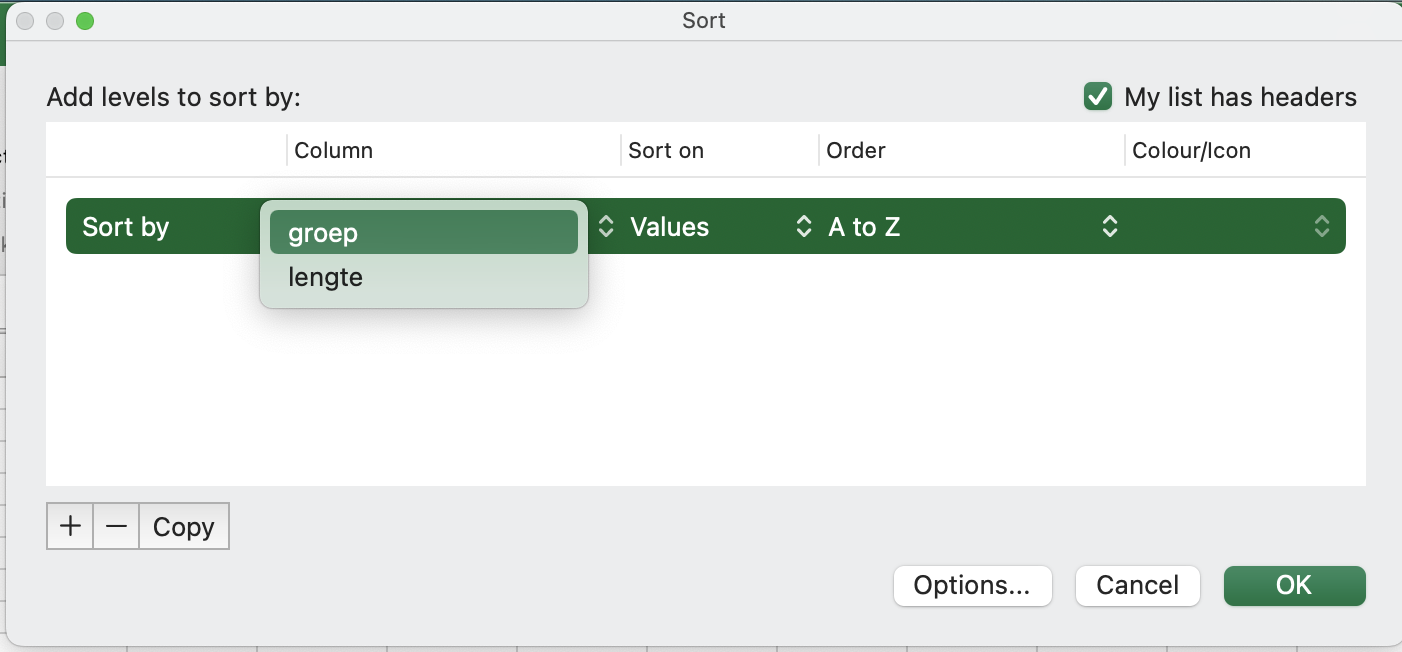
Bij Order kun je kiezen of je van klein naar groot of van groot naar klein wilt sorteren.
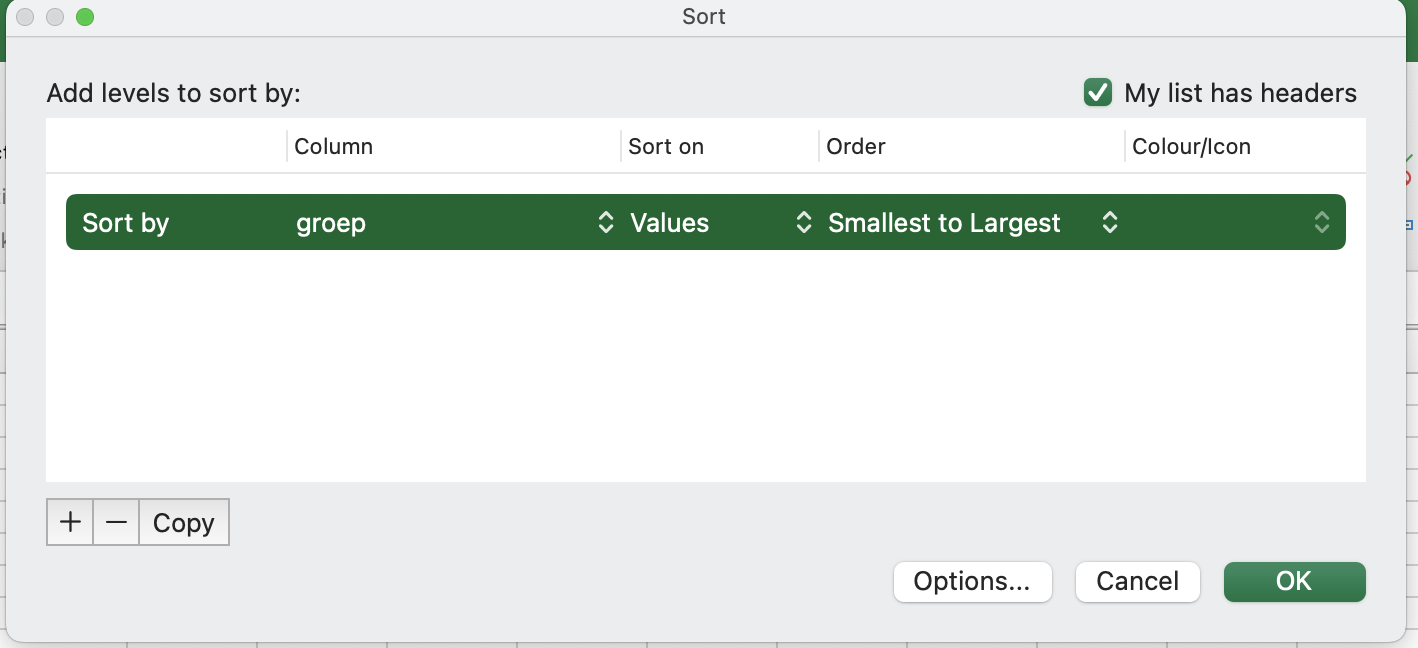
Klik OK en je data is gesorteerd!
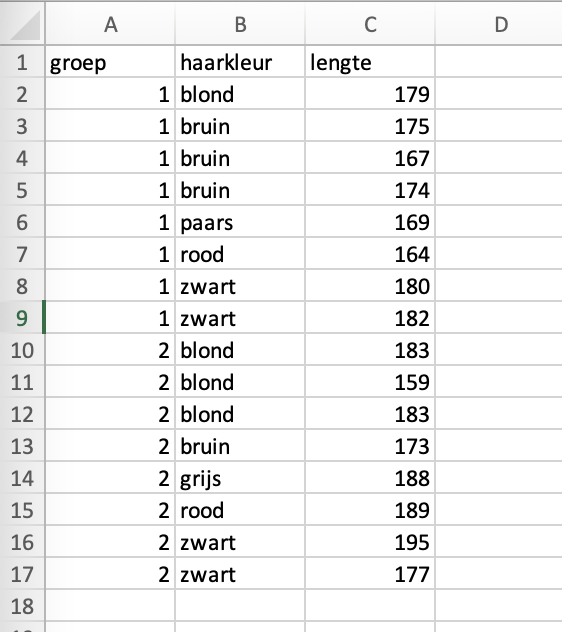
Opdracht 3
In het tweede werkblad vind je data waar ook gegevens over haarkleur in zitten. We willen graag deze data op groep-, en vervolgens op haarkleur sorteren.
Als je in het schermpje van net op het plusje linksonderin klikt, kun je nog een kolom toevoegen waarop je wilt sorteren.
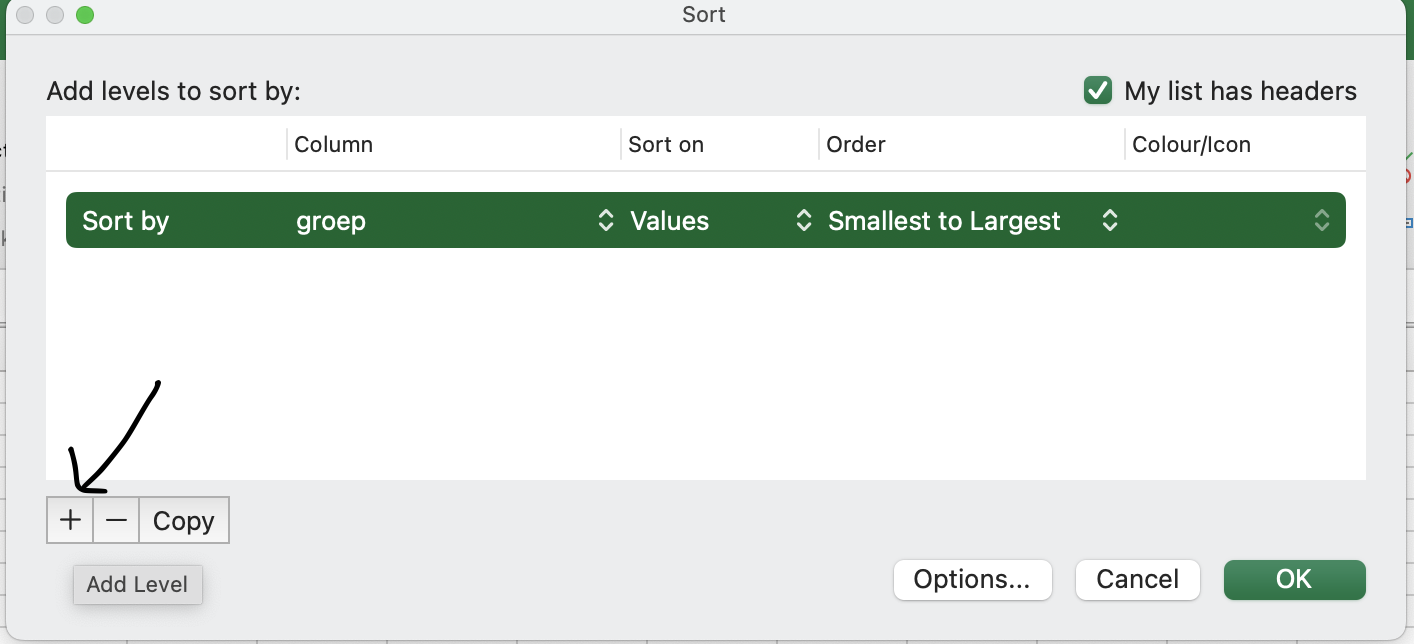
Probeer de data te sorteren op groep en op haarkleur.
Klik hier voor het antwoord
Als het gelukt is, zag het schermpje er zo uit:
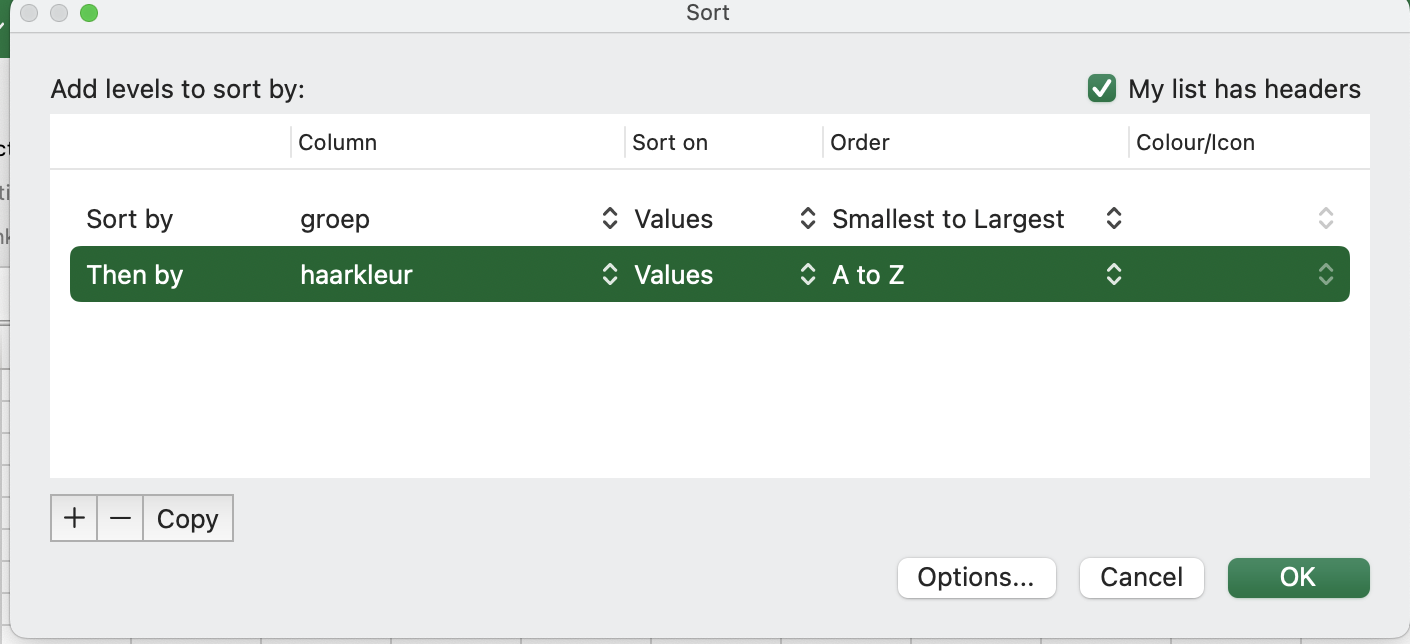
En de data nu zo:
Uitbijters voor niet herhaalde metingen
In de vorige les hebben we gezien dat we de Dixon’s Q test kunnen gebruiken om uitbijters voor herhaalde metingen op te sporen. Hieronder laten we zien wat je kunt doen bij mogelijke uitschieters voor niet herhaalde metingen.
Stap 1: identificeer mogelijke uitschieters
De makkelijkste manier om te zien of er mogelijk sprake is van een uitschieter is om even een grafiekje te maken. Dat kan een scatterplot zijn. In de vorige les hebben jullie al geleerd om een scatterplot te maken.
Je ziet dan vaak meteen of 1 van de stipjes op een rare plek zit. Er is wellicht iets vreemds aan de hand met die meting.
Stel: je koopt 30 verschillende flessen en bepaalt van alle 30 het suikerpercentage. Er is dus sprake van een steekproef met 30 metingen. Als je een scatterplot maakt van de data, kun je zien dat één van de meetpunten mogelijk een uitschieter is.
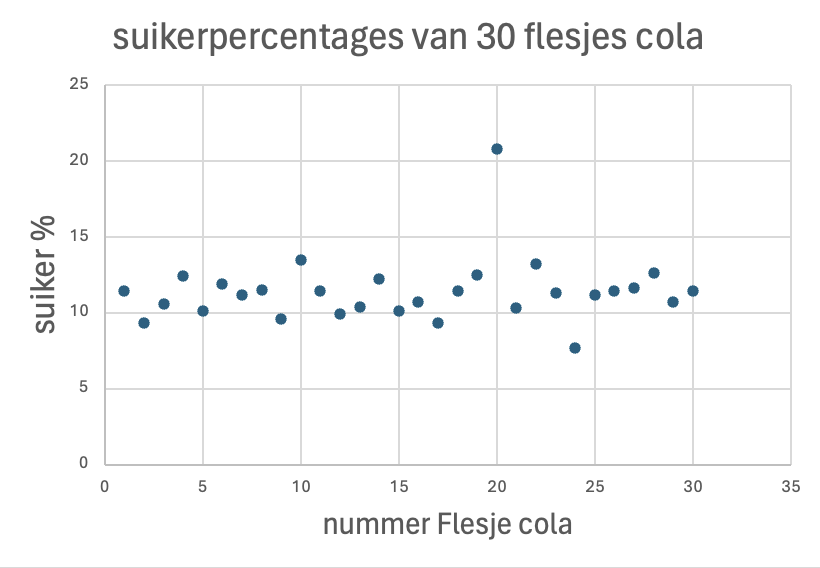
Figure 39: Die is wel raar.
Exercise 3
vreemde getallen 1
Download hier(klik) het excelbestand voor deze opdracht.
Maak een scatterplot van de waarden in de kolom “extinctie” en vind de vreemde meetwaarde.
Klik hier voor het antwoord
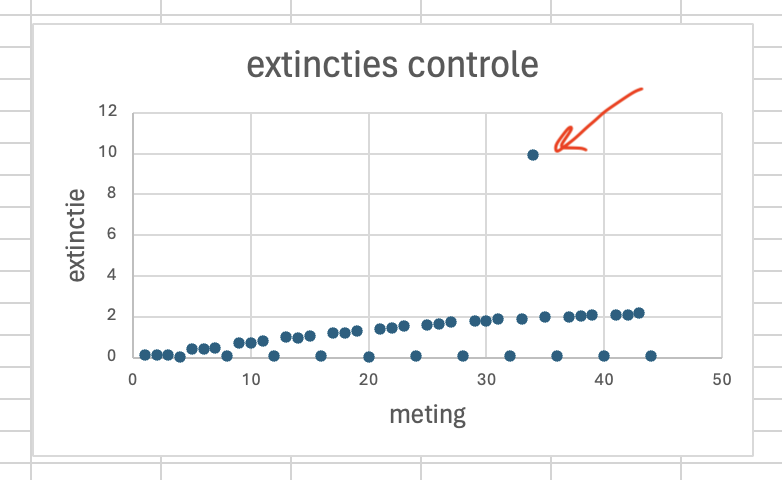
Figure 40: Die is wel raar.
Dit grafiekje is natuurlijk voor verdere dataverwerking niet heel nuttig. Alle condities staan door elkaar en “metingnummer” op de x-as is niet heel informatief. Maar je ziet wel snel en meteen dat er een vreemde meetwaarde in je data zit. Dit grafiekje is dus alleen maar even om een snelle check te doen: is er iets heel erg raars met mijn data? In dit geval: ja.
Stap 2: bepaal of het datapunt een uitschieter is
In het voorbeeld van de steekproef met de 30 colaflesjes is geen sprake van herhaalde metingen. Dat betekent dat de variatie die we hier zien niet alleen komt door onze meetapparatuur, maar ook doordat flesjes cola niet allemaal precies hetzelfde percentage suiker hebben. Dus wanneer is vreemd nu dan vreemd genoeg?
Er zijn hier dan drie mogelijke scenario’s:
Scenario 1: je meet enorm ver buiten de mogelijke range. Het kan natuurlijk zijn dat je een vreemde waarde tegenkomt die helemaal niet kan. Zoals een suikerpercentage van 326%, of een lichaamstemperatuur van 56 graden celcius. Als je dat heel zeker weet dan mag je hem er zo uitgooien, je weet namelijk dan ook zeker dat deze outlier het gevolg is van een meetfout. Dat doe je bij meetwaarden ver buiten wat in werkelijkheid zou kunnen.
Scenario 2: je meet binnen de mogelijke range. Meestal kom je waarden tegen die wel kunnen, maar afwijken van de andere waarden in je experiment. Dus alle konijnen in je steekproef hadden oren van rond de 10 cm, maar 1 konijn had oren van 21 cm. Dat is niet onmogelijk, maar wel vreemd. Wat moet je met dat mogelijke-outlier-konijn? Hieronder bespreken we het boxplot als methode om dat aan te pakken.
Scenario 3: je meet een klein beetje buiten de mogelijke range. Heb je een grensgeval? Kan je meetwaarde een klein beetje niet, dan gooi je hem er toch niet zomaar uit! Dan is het waarschijnlijker dan je door de variatie die je krijgt door je meetapparatuur net een klein beetje anders meet dan verwacht: soms er een beetje boven en soms er een beetje onder. Bijvoorbeeld als je extinctie meet van een blanko-conditie, dan verwacht je nul of net iets meer dan nul. Maar, soms meet je onder nul. Dat is gewoon het effect van variatie. Ook dan ga je dus eventueel met een boxplot kijken.
We kunnen dus boxplots gebruiken om te bepalen of een bepaald datapunt een uitschieter is of niet. Punten die buiten de “whiskers” (stokjes) van het boxplot vallen, zijn outliers. Daar is iets mee aan de hand, en je mag ze weg laten in je berekeningen.
Een boxplot (box- en whiskerplot) is een grafiek die de spreiding van kwantitatieve gegevens weergeeft op basis van kwartielen (zie onderstaande figuur). Kwartielen zijn de datapunten, verdeeld in 4 delen met gelijke hoeveelheden datapunten. De bovenste waarde van de laagste 25% van de datapunten is het 25e percentiel (van “25 procent”). De bovenste waarde van de laagste 50% van de datapunten is de mediaan (middelste waarde). De bovenste waarde van de laagste 75% van de datapunten is het 75e percentiel.
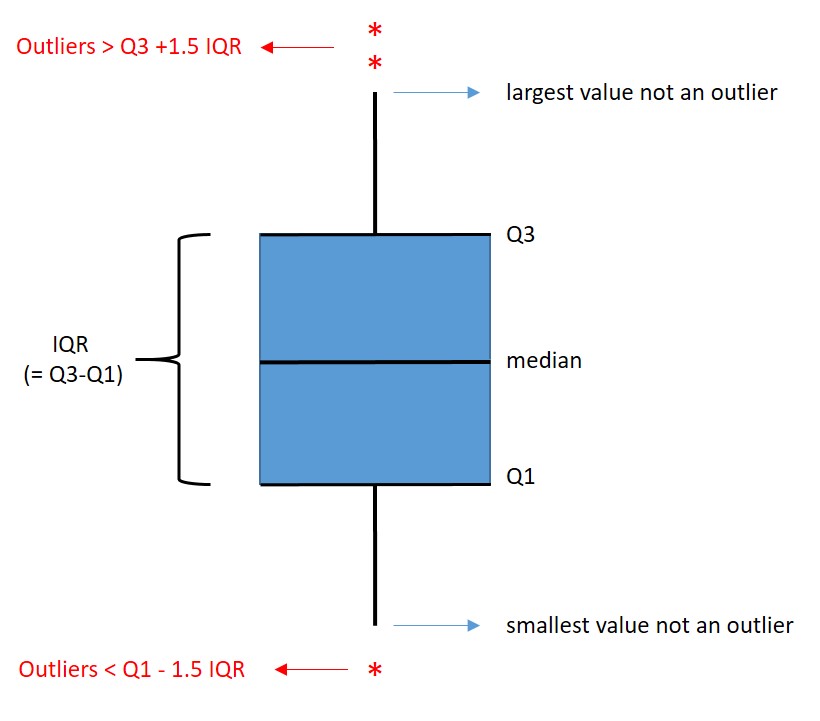
Figure 41: Interpretation of a boxplot. IQR = Inter Quartile Range.
Nu berekent Excel het verschil tussen het 75e percentiel en het 25e percentiel. Dit is de interquartile range (IQR). De bovenste whisker (verticale streep) strekt zich uit vanaf de box tot de grootste waarde die niet verder dan 1,5 * IQR vanaf de box zit. Dus 1,5 * IQR boven het 75e percentiel bovenaan, en 1,5 * IQR onder het 25e percentiel onderaan.
Alle waarden die meer dan 1,5 * IQR boven het 75e percentiel of 1,5 * IQR onder het 25e percentiel liggen, worden apart in de boxplot getekent als stippen. Dit zijn zijn datapunten die aanzienlijk verschillen van de verdeling van de rest van de gegevens (outliers) en die mag je in verdere berekeningen weglaten.
Maak een nieuw tabblad in je excelbestand (bijvoorbeeld genaamd “zonderoutliers”), waarin je al je data kopieert en waarin je vervolgens de outliers verwijderd.
Wanneer een waarde wordt weggelaten moeten gemiddelde en andere statistische parameters zoals het 95% betrouwbaarheidsinterval (zie volgende les) weer opnieuw worden berekend. Daarom werk je dus voor je berekeningen verder in je nieuwe tabblad zonder outliers.
Hier zie je de flesjes-cola-data als boxplot:
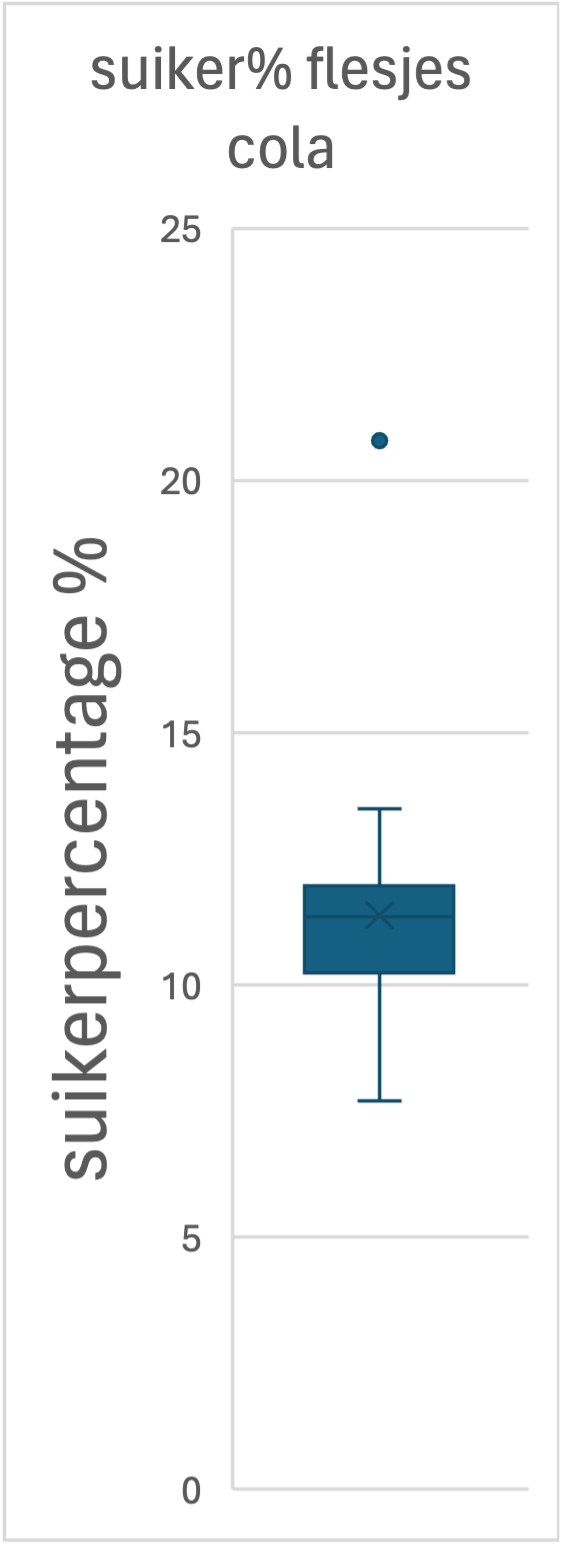
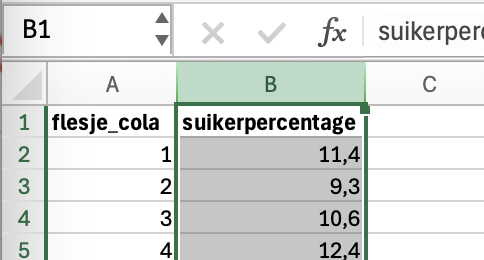
- Klik hier hier(klik) voor deze data.
- Klik op de B boven kolom B met suikerpercentages om deze te selecteren
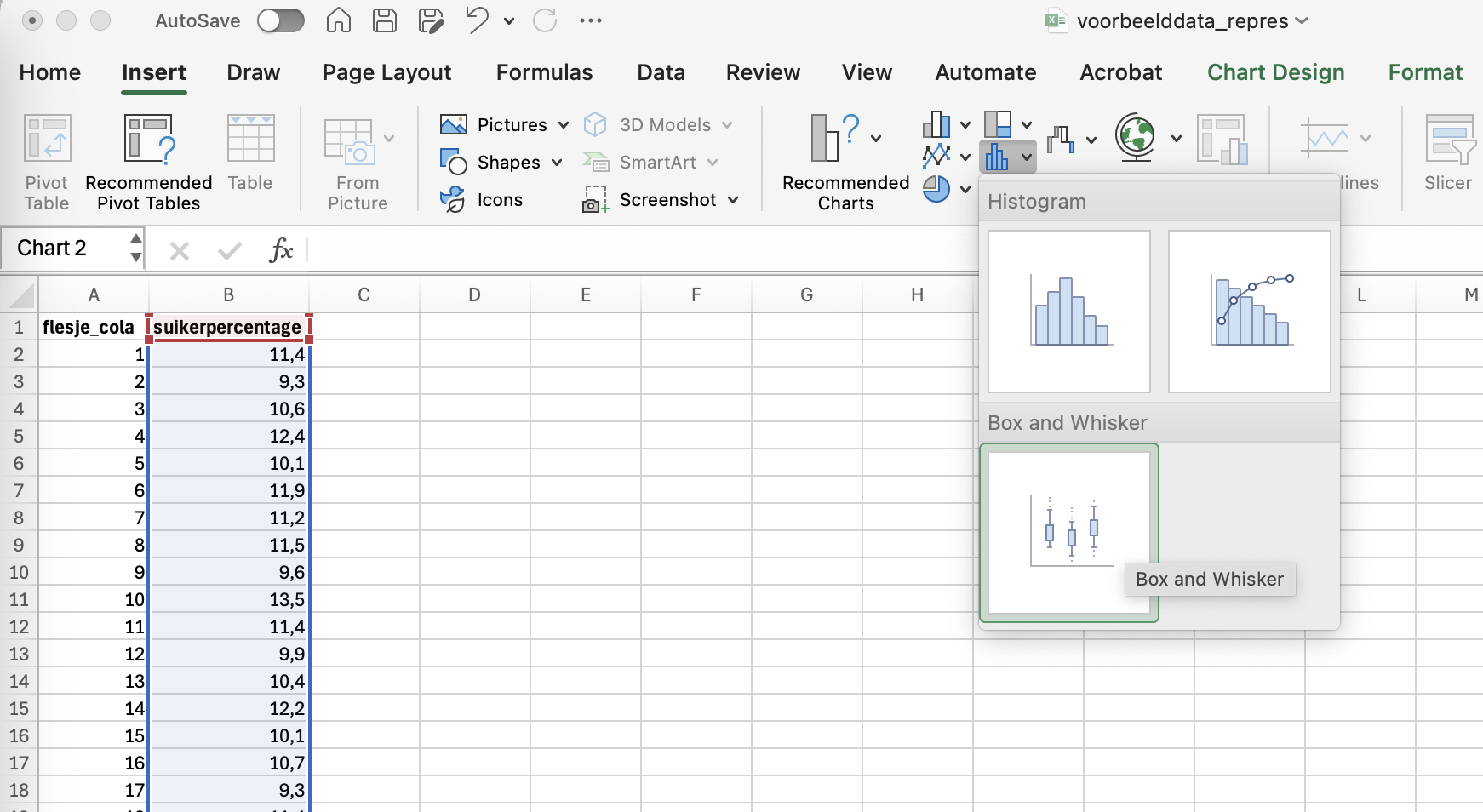
- Klik op insert –> kies via de balkjesgrafieken voor “box and whisker”
- Haal de nietszeggende x-as weg
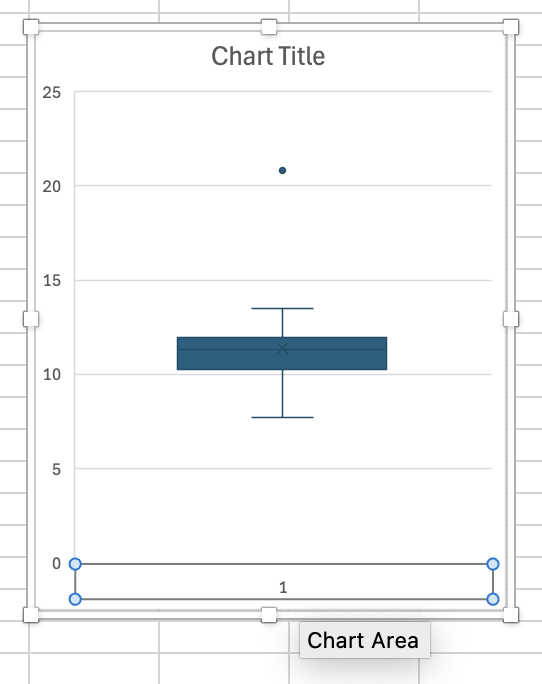
- Geef je grafiek een titel en maak de y-as leesbaar door er op te klikken en dan het lettertype groter te maken.
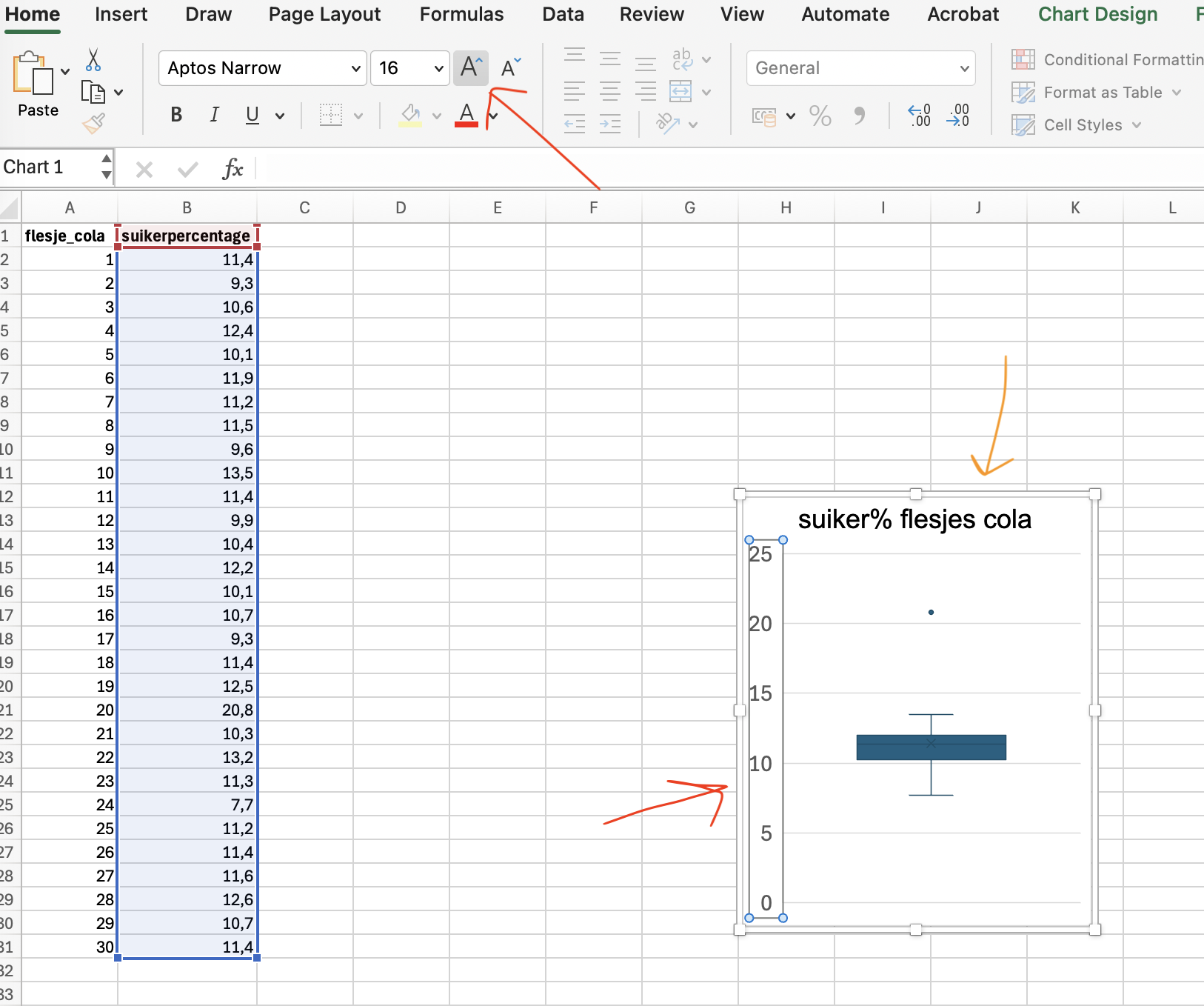
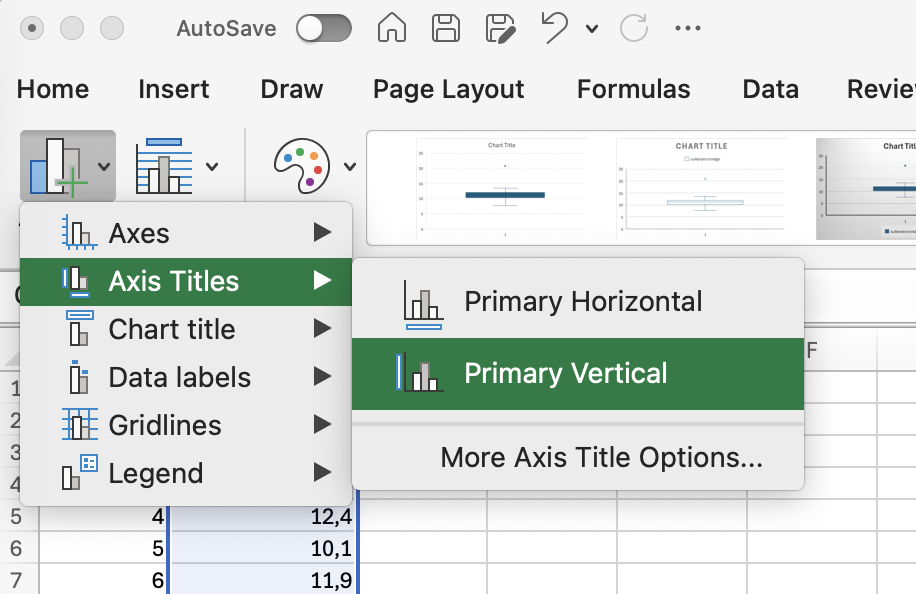
- Geef je grafiek een y-as bijschrift: Klik op je grafiek, buiten de assen –> Klik bovenin de taakbalk op “chart design” –> klik linksboven op “add chart element”, kies “axis title > primary vertical –> pas de tekst van het asbijschrift aan.
Exercise 3
Download hier(klik) data over bloedwaarden voor vitamine B12 in 300 proefpersonen in een experiment.
Maak zelf een boxplot en bepaal of er een outlier in zit.
Bereken nu de gemiddelde en standaarddeviatie van de b12-waarden van proefpersonen in deze steekproef in 1 decimaal nauwkeurig.
Klik hier voor het antwoord
goede antwoord is exclusief de outlier met waarde 24 (proefpersoon 163):
gemiddeld 354,9 pmol/L (vergeet de eenheid niet)
standaarddeviatie 87,6 pmol/L
(Had je 352,9 gemiddeld, dan heb je de outlier er niet uitgegooid)
Werkcollege
Deel 1: reproduceren van een data analyse
We hebben een dataset van iemand anders gekregen met daarin de extincties van een enzym-reactie onder twee verschillende termperatuurcondities, 38 en 35 graden Celcius:
| A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|
| Tijd (seconde) | 38 graden #1 | 38 graden #2 | 38 graden #3 | 35 graden #1 | 35 graden #2 | 35 graden #3 |
| 0 | 0.095 | 0.147 | 0.102 | 0.207 | 0.166 | 0.0183 |
| 30 | 0.129 | 0.157 | 0.126 | 0.315 | 0.205 | 0.246 |
| 60 | 0.232 | 0.24 | 0.225 | 0.373 | 0.332 | 0.353 |
| 90 | 0.365 | 0.372 | 0.383 | 0.415 | 0.451 | 0.476 |
| 120 | 0.425 | 0.463 | 0.488 | 0.547 | 0.542 | 0.498 |
| 150 | 0.449 | 0.475 | 0.462 | 0.523 | 0.554 | 0.521 |
| 180 | 0.464 | 0.492 | 0.489 | 0.508 | 0.582 | 0.522 |
| 210 | 0.486 | 0.503 | 0.499 | 0.541 | 0.575 | 0.524 |
| 240 | 0.465 | 0.505 | 0.503 | 0.552 | 0.575 | 0.525 |
| 270 | 0.485 | 0.523 | 0.513 | 0.563 | 0.581 | 0.561 |
| 300 | 0.503 | 0.523 | 0.521 | 0.567 | 0.637 | 0.551 |
stap 1: kopieer de data in een tabblad en noem dat tabblad “ruwe_data”
stap 2: maak een tabblad “data_check”
stap 3: check de data (getallen, tekst, thousand separator, meetwaarde binnen verwachte range, outliers, maak grafiek(en) voor visuele inspectie)
stap 4: verwijder een outlier als je daar argumenten voor hebt (in een nieuw tabblad)
stap 5: voer berekeningen uit in een tabblad “dataverwerking” (blanco correctie, gemiddelde van triplo’s)
stap 6: visualiseer in hetzelfde tabblad je gemanipuleerde data met de juiste grafiek
Deel 2: werk labdata uit met de Excel template
Verwerk de data van je meest recente vaardighedenles volgens de datamanagement principes van deze les. Maak hiervoor gebruik van de Excel template.