Les3 - Power Analyse
Leerdoelen
De student kent / kan :
- Uitleggen wat de relatie is tussen een steekproef en een populatie.
- Uitleggen wat een null-hypothese is.
- Uitleggen wat type I en type II fouten zijn.
- Power analyse toepassen om de grootte van een steekproef te bepalen.
Inleiding
In les1 hebben we stappenplan geintroduceerd om een experimenteel ontwerp te maken:
- Welke factor(en) (onafhankelijke variabele) ga je testen?
- Wat zijn de levels van de factor(en)?
- Welke controles moet ik meenemen in het experiment?
- Keuze voor modelsysteem?
- Hoeveel proefobjecten (metingen) per experimentele groep?
- Hoe worden de proefobjecten verdeeld over de groepen?
- Wat ga ik meten (afhankelijke variabele)?
- Hoe ga je meten: gepaard of ongepaard?
- Welke statistische test om de data te analyseren?
In deze les gaan we punt (5) verder uitwerken.
Geen verschil tussen experimentele condities?
Stel je doet een experiment en je meet geen statistisch significant verschil tussen de controle groep en de behandelde groep. Kan je dan concluderen dat de experimentele behandeling geen (specifiek) effect heeft gehad in de populatie die getest is?
Er zijn meerdere mogelijke verklaringen:
- De behandeling heeft inderdaad geen effect in de populatie die getest is
- het gebruikte modelsysteem is niet geschikt om te meten wat je wilt meten
- De uitvoering van het experiment was niet goed
- meetfout: het apparaat dat gebruikt wordt om te meten werkt niet goed of is niet gekalibreerd
- De steekproeven zijn te klein om een effect statistisch significant aan te tonen
In les2 hebben we gezien dat met de juiste controles verklaring 3 kunnen uitsluiten. Als laatste moeten we zeker weten dat de steekproef groot genoeg is om effecten die aanwezig zijn in de populatie aan te kunnen tonen. Dit doen we met behulp van een power analyse. Het bepalen van de grootte van de steekproef is een essentieel onderdeel van het experimentele ontwerp. Als op voorhand je steekproef te klein is om een effect aan te tonen zal je dus nooit iets vinden!! Dan kan je het experiment dus net zo goed niet uit voeren. Zonde van je tijd, reagentia en als je werkt met proefdieren is het ook onetisch om proefdieren voor niets op te offeren. Het is ook mogelijk dat je met een kleine steekproef wel een effect vindt, hoewel er te weinig power was. Dit resultaat is dan puur toeval. Je denkt dan een statistisch significant effect te hebben gevonden maar in werkelijkheid is er geen effect (dit noemen ze een type I fout, zie hieronder voor verdere uitleg). Als dit wordt gepubliceerd, kunnen andere onderzoekers hier mee verder gaan, terwijl er dus geen effect is. Dit heeft geleid tot een “replication crisis” in Life Science.
Het bepalen van de grootte van de steekproef met behulp van power analyse heeft altijd betrekking op de biologische replicatie! Dit zegt iets over de biologische variatie van het experiment. Als je meet aan hetzelfde monsters is dat een technische replicatie. Dit zegt iets over de technische variatie van het experiment.
Voordat we de power analyse in detail gaan uitwerken met behulp van R gaan we eerst onze kennis opfrissen over de termen populatie en steekproef.
Populatie en steekproef
Een onderzoeksvraag richt zich altijd op een populatie. In sommige gevallen is het mogelijk om alle proefobjecten (personen, dieren, planten, voorwerpen, cellen, eiwitten enz) in een populatie te meten. Een eigenschap van een populatie die gemeten kan worden noemen we een variabele (iets wat varieert). Een numerieke waarde van de populatie (zoals het gemiddelde, standaard deviatie of de mediaan) noemen we een parameter:
- Hoe lang is de Nederlandse bevolking (variabele = lengte, populatie = Nederlandse bevolking)
- De gemiddelde lengte van alle Nederlandse vrouwen is 170,6 cm (variabele = lengte, populatie = Nederlandse vrouwen, parameter = 170,6 cm)
- Het effect van een medicijn op de tumorgrootte bij kankerpatiënten (variabele = tumorgrootte, populatie = kankerpatiënten)
- De mediaan van alle tentamencijfers van alle VL3 studenten is 6,2 (variabele = tentamencijfers, populatie = VL3 studenten, parameter = 6,2)
- Concentratie van een bepaald eiwit in het bloed van alle patiënten met verhoogde bloeddruk (variabele = eiwitconcentratie in het bloed, populatie = alle patiënten met verhoogde bloeddruk)
In de meeste gevallen is het onmogelijk om een hele populatie te meten omdat de populatie te groot is of te kostbaar om alle objecten te meten.
Als de populatie niet gemeten kan worden maakt men gebruik van een steekproef. Een steekproef is een representatief gedeelte van de populatie. Een numerieke waarde van de steekproef (zoals het gemiddelde, mediaan of de standaard deviatie) noemt men een statistiek. Vervolgens kan men aan de hand van een steekproef (en de berekende statistiek) een voorspelling doen over de populatie-parameter met behulp van inductieve statistiek (zie les 5 t/m 8).
Wetenschappelijke experimenten worden meestal uitgevoerd met behulp van een steekproef. Een steekproef moet daarom altijd groot genoeg zijn om representatief te zijn voor de populatie!!
De symbolen voor gemiddelde, standaard deviatie en aantal elementen voor een populatie en een steekproef staan hieronder weergegeven:
populatie:
gemiddelde: \(\mu\)
standaard deviatie: \(\sigma\)
aantal: N
steekproef:
gemiddelde: \(\bar{x}\)
standaard deviatie: s
aantal: n
les3_opdracht
Geef aan wat het paars gekleurde zinsdeel is. Kies uit populatie, steekproef, parameter, statistiek of variabele.
Een onderzoeker wil de gemiddelde lengte van vrouwen van 20 jaar en ouder schatten. Uit een steekproef van 45 vrouwen berekent de onderzoeker een gemiddelde lengte van 162,5 cm.
Een voedingsdeskundige wil de gemiddelde hoeveelheid natrium schatten die kinderen jonger dan 10 jaar binnenkrijgen. Uit een aselecte steekproef van 75 kinderen jonger dan 10 jaar berekent de voedingsdeskundige een steekproefgemiddelde van 2993 milligram natriuminname.
Nexium is een medicijn dat kan worden gebruikt om de zuurproductie van het lichaam te verminderen en slokdarmschade te herstellen. Een onderzoeker wil het aantal patiënten schatten dat Nexium gebruikt en binnen 8 weken herstelt van slokdarmschade. Er werd een aselecte steekproef genomen van 224 patiënten die leden aan zure refluxziekte en Nexium gebruikten en van deze patiënten waren 213 na 8 weken genezen.
Een onderzoeker wil het aantal lymfocyten per \(\mu\)l bloed meten bij personen met de ziekte van Pfeiffer (mononucleosis infectiosa). Aan de hand van een steekproef van 40 geïnfecteerde personen berekent de onderzoeker een gemiddelde waarde van 6000 lymfocyten per \(\mu\)l bloed.
Een onderzoeker wil het gemiddelde aantal lymfocyten per \(\mu\)l bloed schatten bij personen met de ziekte van Pfeiffer (mononucleosis infectiosa). Aan de hand van een steekproef van 40 geïnfecteerde personen berekent de onderzoeker een gemiddelde waarde van 6000 lymfocyten per \(\mu\)l bloed.
Een onderzoeker wil het gemiddelde aantal lymfocyten per \(\mu\)l bloed schatten bij personen met de ziekte van Pfeiffer (mononucleosis infectiosa). Met behulp van een steekproef van 40 geïnfecteerde personen berekent de onderzoeker een gemiddelde waarde van 6000 lymfocyten per \(\mu\)l bloed.
Een onderzoeker wil het gemiddelde aantal lymfocyten per \(\mu\)l bloed schatten bij personen met mononucleosis infectiosa (ziekte van Pfeiffer). Met behulp van een steekproef van 40 geïnfecteerde personen berekent de onderzoeker een gemiddelde waarde van 6000 lymfocyten per \(\mu\)l bloed.
Klik voor het antwoord
- parameter
- statistiek
- steekproef
- variabele
- populatie
- parameter
- statistiek
Power analyse
Een goede opzet van een experiment vereist een weloverwogen keuze voor het aantal metingen voor iedere experimentele groep. Te weinig metingen vergroten de kans dat een werkelijk effect onopgemerkt blijft (underpowered experiment), terwijl te veel metingen kunnen leiden tot het detecteren van triviale verschillen die biologisch niet relevant zijn (overpowered experiment). Daarnaast zijn overbodig grote steekproeven inefficiënt, duur, en bij dierproeven ethisch onwenselijk. Om deze balans te vinden, wordt gebruikgemaakt van een poweranalyse. Power analyse maakt gebruikt van 4 parameters.
- Significantieniveau (\(\alpha\))
- Statistical power (1-\(\beta\))
- Effectgrootte (effect size)
- Groote van de steekproef (n)
Als er 3 van de 4 parameters bekend zijn dan kan de 4de parameter uitgerekend worden. Poweranalyse is alleen nuttig als je vooraf bepaald hoe groot de steekproef moet zijn om een verwacht biologisch relevant effect aan te tonen. Als je achteraf, na de uitvoering van het experiment, de power analyse gaat doen en je komt erachter dat de steekproef niet groot genoeg was (te weining power) om een bepaald effect aan te tonen dan heb je het experiment dus voor niks uit gevoerd.
De parameters \(\alpha\), \(\beta\) en effectgrootte worden hieronder verder toegelicht zodat we de grootte van de steekproef kunnen uitrekenen met behulp van het R package “pwr”
Type I (\(\alpha\)) en type II (\(\beta\)) fouten
Null hypothese significance testing (NHST) is de meest gebruikte methode om aan te tonen of de controle groep en de experimenteel behandelde groep (of groepen) statistisch significant van elkaar verschillen. Het uitgangspunt van NHTS is altijd dat er geen effect is van de experimentele behandeling. Dit concept wordt formeel vast gelegd in de null hypothese (H0) en een alternatieve (H1) hypothese.
H0: er is geen effect van de experimentele behandeling in de populatie: \(\mu_1 = \mu_2\)
H1: er is wel een effect van de experimentele behandeling in de populatie: \(\mu_1 \ne \mu_2\)
In NHST wordt na een statistisch test de H0 geaccepteerd (geen verschil in de populatie) of verworpen waarna de H1 wordt geaccepteerd (wel een verschil in de populatie). Omdat NHTS berust op kansrekenen is het mogelijk om tot een verkeerde conclusie te komen. Dit zijn de Type I en Type II fouten van NHTS:
Type I: Je concludeert dat er een effect is, maar in werkelijkheid is er geen effect (zie figuur 28, false positive). De kans hierop wordt weergeven met \(\alpha\) en dit is standaard 0,05. Dit betekent dat we voor 1 van de vergelijkbare 20 experimenten, die in werkelijkheid geen effect hebben, concluderen dat er een effect aanwezig is in de populatie
Type II: Je concludeert dat er geen effect is, maar in werkelijkheid is er wel een effect (zie figuur 28, false negative). De kans hierop wordt weergegeven met \(\beta\) en dit is standaard 0,2.
Dit betekent dat we voor 1 van de 5 experimenten, die in werkelijkheid wel een effect hebben, concluderen dat er geen effect was. Andersom beredeneert betekent dit, dat we van 4 van de 5 experimenten een effect aantonen die in werkelijkheid ook aanwezig is. Dit wordt ook wel de power genoemd van een experiment en wordt dus beschreven met 1-\(\beta\). De standaard waarde voor de power is dus 1-0,2 = 0,8 = 80%. Als er daadwerkelijk een effect aanwezig is in de populatie dan wordt het in 80 van de 100 vergelijkbare experimenten aangetoond.

Figure 28: Type I en Type II fouten.
Gerelateerde begrippen die zijn gekoppeld aan \(\alpha\) en \(\beta\) zijn sensitiviteit en specificiteit:
- Sensitiviteit is de kans dat een effect wordt gevonden wanneer het aanwezig is (hoog bij lage β)
- specificiteit is de kans dat geen effect wordt gevonden wanneer het effect niet aanwezig is (hoog bij lage α).
Grootte van het effect
De grootte van het effect na een experimentele behandeling kan op verschillende manieren uitgedrukt worden afhankelijk van de proefopzet. Voor OFAT experimenten gebruiken we Cohen’s d bij twee steekproeven en Cohen’s f voor drie of meer steekproeven.
Cohen’s d wordt op de volgende manier berekend:
\[ d = \frac{\bar{x}_1 - \bar{x}_2}{s_{\text{pooled}}} \]
In deze formule wordt eerst het verschil uitgerekend tussen de gemiddelden van steekproeven en dit verschil wordt gecorrigeerd voor de ruis in het experiment. De ruis wordt weergegeven door de gecombineerde standaard deviatie van de twee steekproeven (= spooled). Afhankelijk of de proef gepaard of ongepaard is wordt de spooled op een iets andere manier uitgerekend. Het verschil tussen de steekproeven wordt dus uitgedrukt als aantal standaarddeviatie en is een effect:ruis ratio zoals we eerder hebben gezien. We zien hier weer het belang om de variatie tijdens het experiment zo klein mogelijk te houden. Als de ruis klein is verkrijgen we een grotere Cohen’s d zodat we met minder steekproeven een effect kunnen aantonen.
Over het algemeen wordt Cohen’s d op de volgende manier geinterpreteerd:
d = 0.2 -> klein effect
d = 0.5 -> medium effect
d = 0.8 -> groot effect
De interpretatie van Cohen’s d is sterk afhankelijk in welk domein van de Life Science de experimenten uitgevoerd worden en of het effect biologisch relevant is!
Als we een groot effect verwachten van de experimentele behandeling dan volstaat een een kleinere steekproef om het effect statistisch aan te tonen (zie figuur 29)
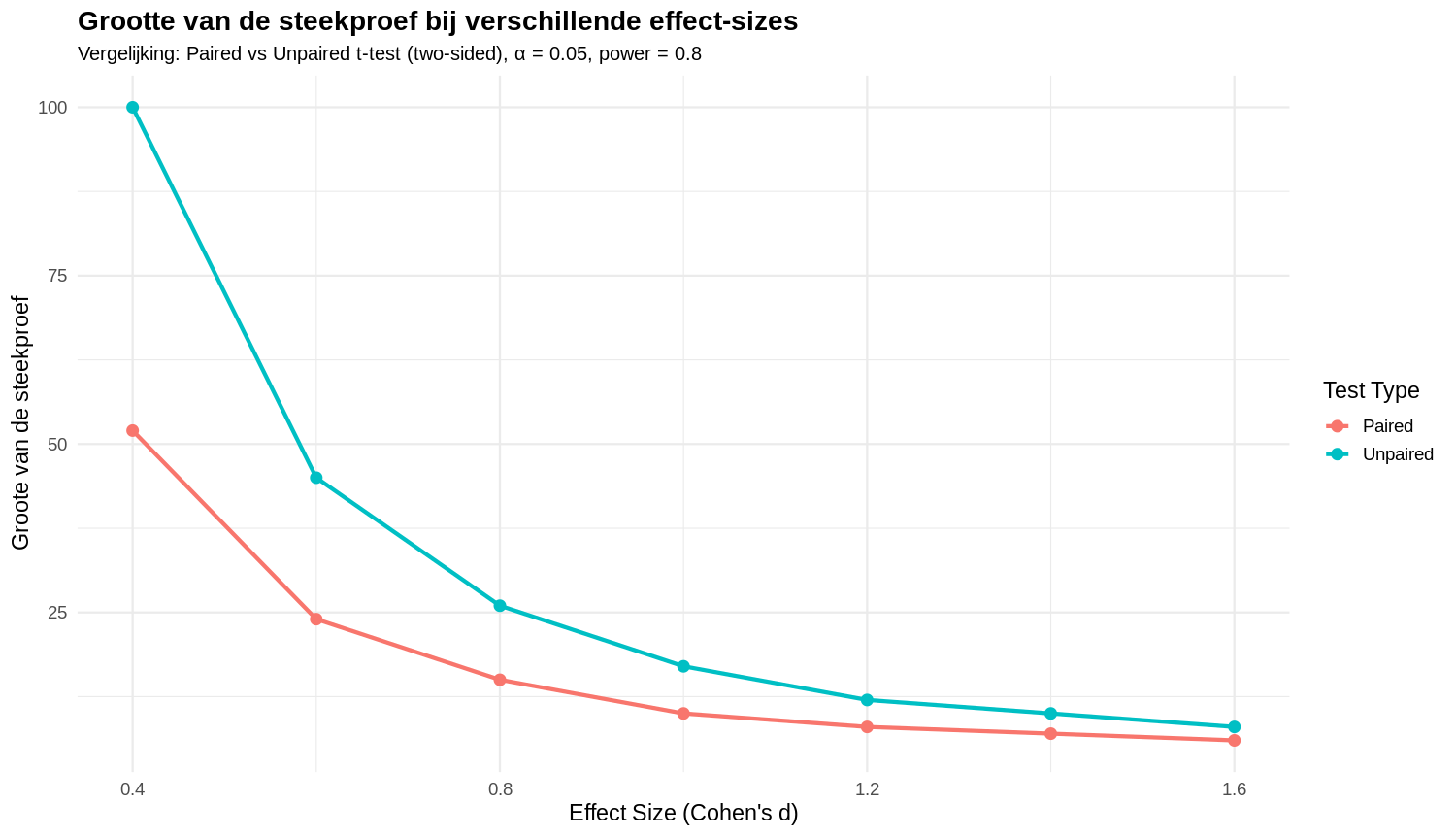
Figure 29: Relatie tussen effect size and grootte van de steekproef voor gepaarde en ongepaarde t-testen. Met een gepaarde proefopzet heb je minder proefobjecten nodig om een effect aan te tonen. Een gepaarde proefopzet is meer gevoeliger (sensitive)
Cohen’s f wordt op de volgende manier berekend:
\(f = \sqrt{\frac{\eta^2}{1 - \eta^2}}\)
In deze formule geeft de \(\eta^2\) aan welk deel van de variatie in een experiment verklaard wordt door de experimentele behandeling. Bijvoorbeeld als \(\eta^2\) een waarde heeft van 0,2 dan betekent dit, dat van alle variatie in een experiment (afkomstig van biologische, technische variatie en het effect van de behandeling) 20% verklaard kan worden door het effect van de behandeling. De f-waarde geeft vervolgens aan hoe groot de verschillen zijn tussen de groepen:
Over het algemeen wordt Cohen’s f op de volgende manier geÏnterpreteerd:
f = 0.10 -> kleine verschillen tussen de groepen
f = 0.25 -> medium verschillen tussen de groepen
f = 0.40 -> grote verschillen tussen de groepen
Als we een groot effect verwachten van de experimentele behandeling dan is er een kleinere steekproef nodig om dit effect statistisch aan te kunnen tonen (zie figuur 30)
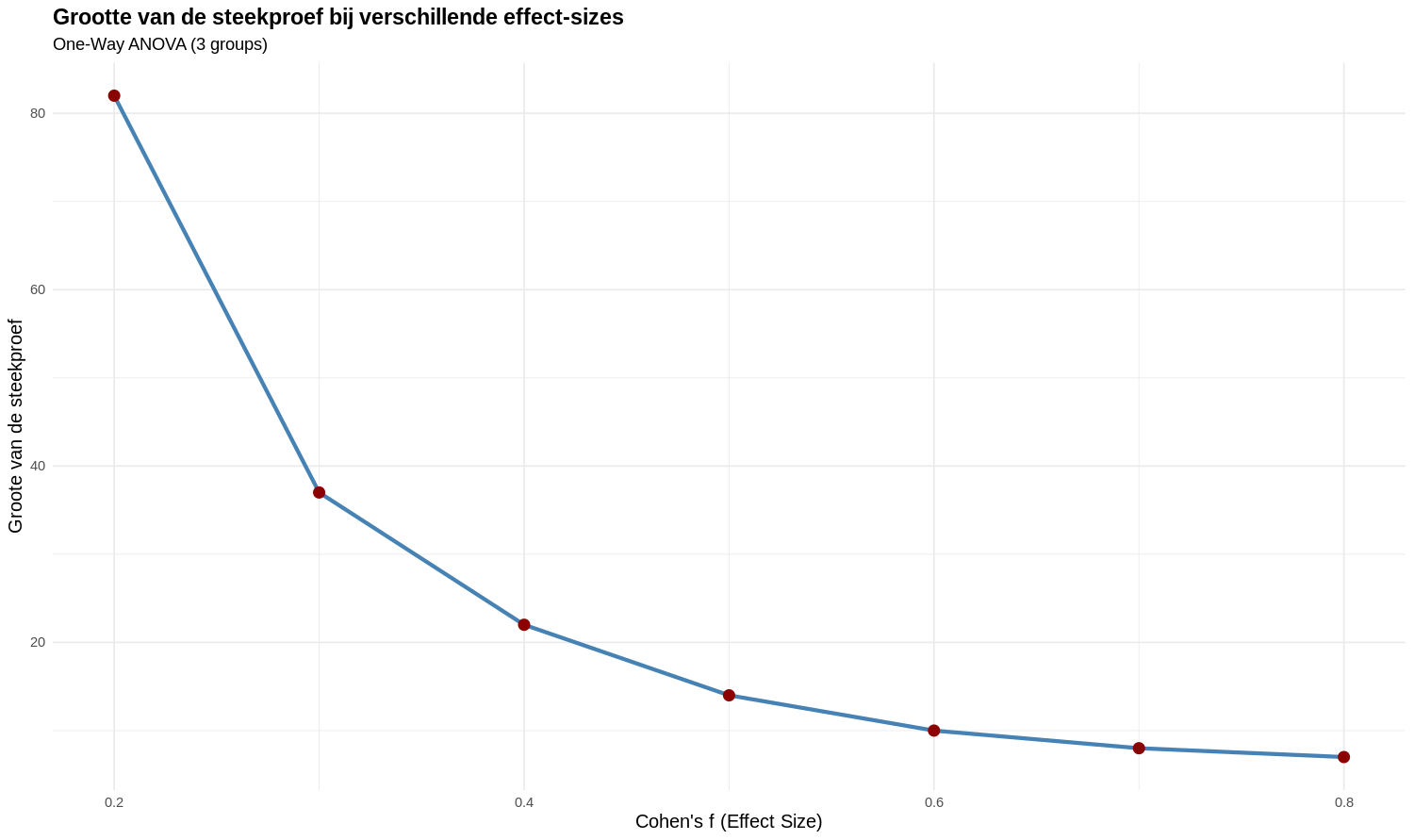
Figure 30: Relatie tussen effect size and grootte van de steekproef voor ANOVA met drie groepen
Bepaling van de grootte van het effect
Maar hoe weten we nu voorafgaand aan het experiment wat de de grootte van het effect zal zijn. Dit is juist wat we willen onderzoeken. Is er een effect en zo ja hoe groot is dit effect. Om een schatting te krijgen wat het effect zal zijn van een experimentele behandeling gaan we terug naar de eerste stap van de onderzoekscyclus: verkennen en verdiepen:
- Ervaring uit het lab: zijn er vergelijkbare experimenten gedaan en wat was de uitkomst?
- Literatuuronderzoek: zijn er vergelijkbare studies gepubliceerd?
Pubmed bevat miljoenen artikelen en het is een hele kunst om daar de juiste informatie in te vinden. Met de keuze voor een Large Language Model (LLM) en een goede prompt kunnen we een idee krijgen wat de verwachtte grootte is van een effect na een experimentele behandeling.
- Ga naar bijlage 2 en lees hoe je verantwoord gebruik kan maken van LLM’s.
Structureer en bewaar je prompts. Het moet altijd transparant zijn voor de docent, onderzoekers, mede-studenten hoe je aan je informatie bent gekomen via een LLM
Wetenschappelijke literatuur is in het Engels. Schrijf daarom je prompts ook in het Engels voor een beter resultaat.
Stap1: maak een keuze in welke LLM je wilt gebruiken, bijvoorbeeld:
https://copilot.microsoft.com/
https://chatgpt.com/
https://www.perplexity.ai/
https://www.pubmed.ai/home
Stap2: gebruik een standaard format om een goede prompt te schrijven. Gebruik bijvoorbeeld de template van de bijlage:
goal:
instruction:
context:
data:
output:
Stap3: controleer de output:
Validatie: voldoet de output aan de opdracht (prompt)?
Verificatie: klopt de output?
les3_opdracht
- Kopieer en plak de onderstaande prompt in een LLM naar keuze.
goal: obtain an estimate of cohen’s d
instruction: search only scientific information listed on NCBI such as pubmed and GEO. Use information from these databases to calculate Cohen’s d. Show the actual numbers used to calculate Cohen’s d
context: what is the expected effect on gene expression of lipid metabolism genes in mice after exposure to PFAS
output: list the papers and or databases used to calculate Cohen’s d
Valideer en verifieer de output van de prompt:
Validatie: voldoet de output aan de opdracht (prompt)?
Verificatie: klopt de output? Waarop is het antwoord gebaseerd. kan je dit terug vinden in de literatuur die gebruikt is?
Is er een verschil in output tussen de LLM’s?
Klik voor het antwoord
Geen antwoord. Zelf kritisch nadenken!!les3_opdracht
Volgens een nieuwe theorie zouden eukaryote cellen in stressvolle omstandigheden hun organellen tijdelijk “parkeren” in de celkern. Mitochondriën en fragmenten van het Golgi-apparaat dringen door de nucleaire poriën heen en functioneren daar als een soort nood-energiecentrale. Het zou de cel in staat stellen om DNA-reparatie sneller uit te voeren door directe levering van ATP en nucleotiden in de celkern. Dir proces wordt aangeduid als Intranucleaire Organel Shift (IOS). Een onderzoeker wil dit proces bestuderen en verwacht een na een stressresponse dat de hoeveelheid ATP in de celkern verhoogd wordt ten opzichte van cellen die geen stress-response ondergaan. Maak gebruik van LLM en een goede prompt om het te verwachtte effect te bepalen (Cohen’s d) voor power analyse
Klik voor het antwoord
goal: obtain an estimate of cohen’s d
instruction: search only scientific information listed on NCBI such as pubmed and GEO. Use information from these databases to calculate Cohen’s d. Show the actual numbers used to calculate Cohen’s d
context: what is the expected effect on nuclear ATP increase caused by Intranucleaire Organel Shift (IOS) in eukaryotic cells after stress response
output: list the papers and or databases used to calculate Cohen’s d
Wat het antwoord ook is van de LLM, Intranucleaire Organel Shift (IOS) bestaat niet. Het is een verzonnen biologisch proces!!
Power analyse in R
Als laatste stap gebruiken we de R package “pwr” om de grootte van de steekproef te bepalen in de context van een OFAT experiment. Dat betekent dat we de grootte van een steekproef gaan bepalen voor:
- gepaarde proefopzet met twee steekproeven:
library(pwr)
pwr.t.test(d=1, # Cohen's d: in dit voorbeeld 1
power=0.8, # standaard 0.8
sig.level=0.05, # standaard 0.05
type="paired", # type t-test
alternative="two.sided") # tweezijdig testenDe output van de analyse staat in figuur 31 waarbij n het aantal proefobjecten aangeeft die nodig zijn om een Cohen’s d van 1 te meten met een gepaarde proefopzet.

Figure 31: Output van de power analyse voor een gepaarde proefopzet met twee steekproeven
- Ongepaarde proefopzet met twee steekproeven:
library(pwr)
pwr.t.test(d=1, # Cohen's d
power=0.8, # standaard 0.8
sig.level=0.05, # standaard 0.05
type="two.sample", # type t-test
alternative="two.sided") # tweezijdig testen- ongepaarde proefopzet met drie steekproeven:
library(pwr)
pwr.anova.test(f = 0.25, # Cohen's f
k = 3, # aantal groepen
power = 0.8, # standaard 0.8
sig.level = 0.05) # standaard 0.05Casus
- Een onderzoeker wil testen of Bacillus subtilis een effect heeft op de ziekteverschijnselen van de ziekte van Alzheimer. De onderzoeker gebruikt hiervoor C. elegans stam CL4176 als modelsysteem en meet de tijd tot volledige paralysis (verlamming):
factor: Bacillus subtilis
modelsysteem: C. elegans stam CL4176
afhankelijke variabele: tijd tot volledige paralysis
- Zoek informatie op over stam CL4176
- Zoek op wat de Cohen’s d waarde is voor deze onderzoeksvraag
- Bereken hoeveel wormen per groep er nodig zijn voor dit experiment
- Ontwerp nu een experiment voor het MIZI3V project in overleg met de tutor. Gebruik hiervoor het stappenplan zoals uitgelegd tijdens les1 t/m3 (denk ook alvast na over stap (9))
- Formuleer een onderzoeksvraag en hypothese
- Welke factor(en) (onafhankelijke variabele) ga je testen?
- Wat zijn de levels van de factor(en)?
- Welke controles moet ik meenemen in het experiment?
- Keuze voor modelsysteem
- Hoeveel proefobjecten (metingen) per experimentele groep?
- Hoe worden de proefobjecten verdeeld over de groepen?
- Wat ga ik meten (afhankelijke variabele)?
- Hoe ga je meten: gepaard of ongepaard?
- Welke statistische test om de data te analyseren?