Les6 - Uitbijters en normaal verdeling
Leerdoelen
- Bepalen of er uitbuiters in een dataset aanwezig zijn en deze verwijderen
- Bepalen of een dataset normaal verdeeld is
Introductie
Na het ontwerpen van een experiment (les1 t/m les4) en de uitvoering ervan op het lab willen we graag weten of er een verschil is tussen de controle groep en de experimentele groep(en). Na het verkennen en visualiseren van de data (les5) hebben we al een goed beeld van de data en of er visueel gezien een verschil is tussen de verschillende experimentele condities. Als we een visueel verschil waarnemen betekent dit niet dat we kunnen concluderen dat het verschil door de experimentele behandeling komt. We moeten dit statistisch testen zodat we met een bepaalde zekerheid kunnen vaststellen dat het verschil in experimentele groepen niet op toeval berust maar op de experimentele behandeling (=onafhankelijke variabele). Hiervoor gebruiken we zogenaamde parametrische toetsen. Er zijn een aantal voorwaarden waaraan de data moet voldoen voordat je een parametrische test mag uitvoeren (zie figuur 56):
- Je wilt een verschil aantonen tussen de controle groep en experimentele groep(en) van je experiment (een vergelijkende onderzoeksvraag)
- De meetwaarden zijn kwantitatief
- Geen uitbijters in de dataset
- De data is normaal verdeeld
(Voor sommige testen zijn er nog aanvullende voorwaarden voordat de test uitgevoerd mag worden. Dit wordt verder uitgewerkt in les7)
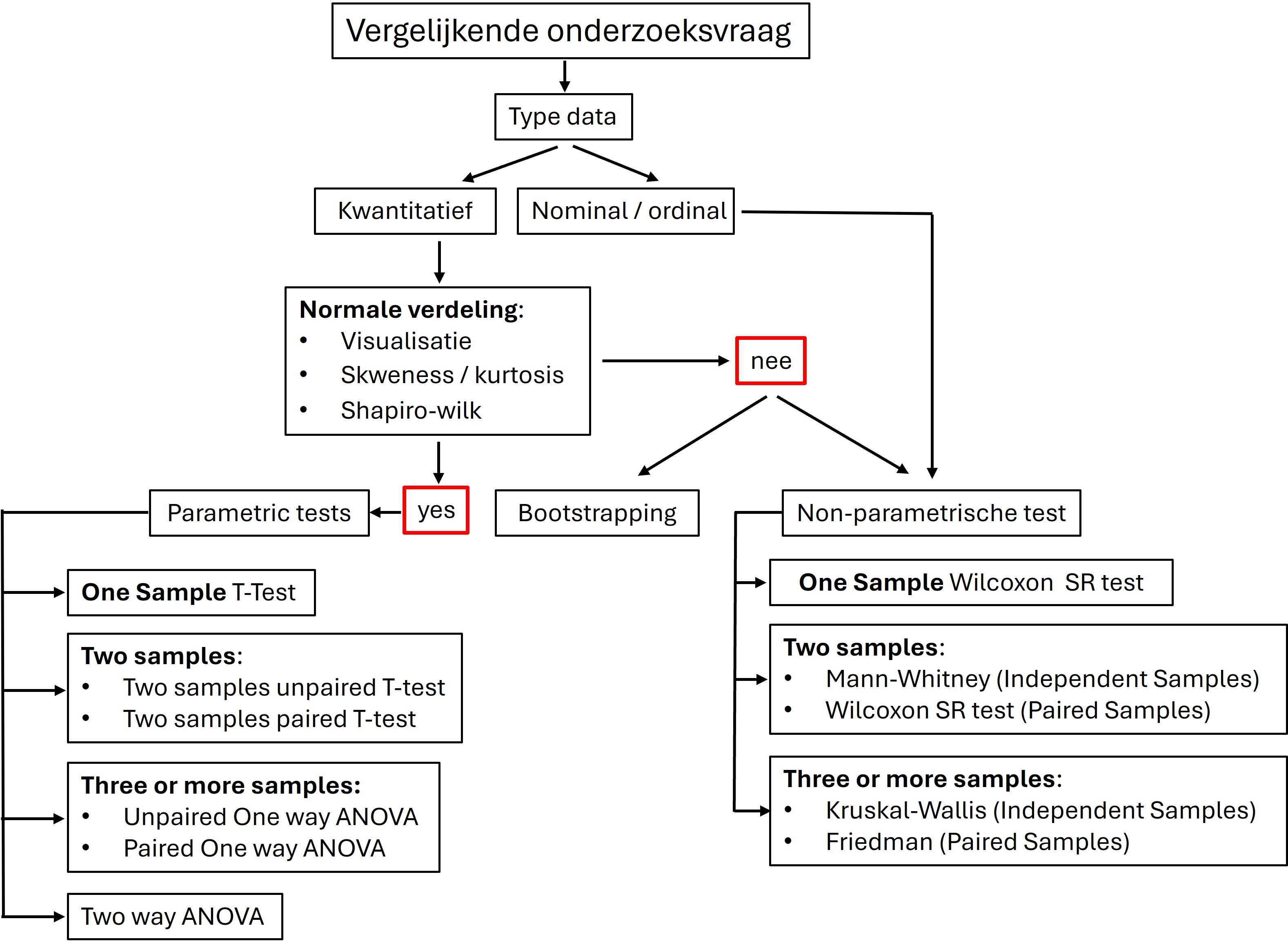
Figure 56: Beslissingsboom statistische testen
LET OP: Als er niet aan de voorwaarden wordt voldaan heeft het uitvoeren van een parametrische test geen zin. Het is dus altijd belangrijk om eerst te bepalen of de experimentele opzet en de data aan de voorwaarden voldoen.
Verwijderen van uitbijters
Uitbijters kunnen ontstaan door:
- Een “vermijdbare fout”: bijvoorbeeld de waarde is 2,02 en er wordt per ongeluk 20,02 genoteerd
- Natuurlijke variatie binnen de steekproef (natuurlijke variatie)
- Slechte praktijk in het lab: bijvoorbeeld een verkeerde berekening of slecht pipetteren (technische variatie)
Als het gemiddelde en standaardeviatie van de steekproef vertekend zijn door uitbijters (wat betekent dat steekproefgemiddelde teveel afwijkt van de het populatiegemiddelde), heeft het geen zin om parametrische toetsen uit te voeren.
Voordat we een parametrische toets uitvoeren, moeten we er zeker van zijn dat het steekproefgemiddelde het populatiegemiddelde vertegenwoordigt. Je wilt immers een uitspraak doen over de populatie waarbij de steekproef de populatie vertegenwoordigt. Een uitbijter heeft een sterke invloed op het gemiddelde (\(\bar{x}\)) en de standaarddeviatie (s) van de steekproef.
Voordat we beginnen met het verwijderen van uitbijters en het bepalen of de data normaal is verdeeld, zorg er voor dat je de benodigde packages activeert in de R console met de library() functie:
library(tidyverse)
library(ggplot2)
library(outliers)
library(dslabs)
library(moments)Effect van een uitbijter op de standaard deviatie:
# Data in tibble. Dataset2 heeft een uitbijter (20)
les6_dataset <- tibble(data1=c(2,3,4,5,4,6,7,8,3,4),
data2=c(2,3,4,5,4,6,7,8,3,20))
# Beschrijvende statistiek
# De data is niet tidy. Berekening van de stdev voor iedere dataset ...
# met behulp van de map_dbl() functie in combinatie met de sd() functie.
# De output van map_dbl is een vector met de berekende stdev waarde voor iedere dataset
les6_dataset_sd <-les6_dataset |> map_dbl(sd)
# Selectie van de stdev waarde van dataset1 met een index []
# Met een index achter het R object kunnen we een element selecteren uit de output vector
# standaard deviatie van dataset1
data1_sd <-les6_dataset_sd[1] |> round(digits=2) # [1] betekent het 1ste element van de vector = stdev van dataset1
# standaard deviatie van dataset2
data2_sd <-les6_dataset_sd[2] |> round(digits=2) # [2] betekent het 2de element van de vector = stdev van dataset2
# print standaarddeviatie van data1 en data2
data1_sd
data2_sdWe zien dus dat een uitbijter de standaarddeviatie vergroot. De standaarddeviatie (s) wordt gebruikt in de formule van de SEM (zie formule hieronder) en dus heeft een uitbijter ook invloed op de berekening van de SEM.
\[SEM=\frac{s}{\sqrt{n}}\]
Effect van een uitbijter op de SEM:
# Bereken de SEM van data1
# Hiervoor hebben we nodig:
# (1) de standaard deviatie van data1
# (2) en de hoeveelheid metingen van data1
# (1) stdev van data1
data1_sd <-les6_dataset_sd[1] |> round(digits=2)
# (2) Bepaal grootte van de steekproef (n) van data1 m.b.v. de length() functie
data1_n <- les6_dataset$data1 |> length()
# (3) berekening van de SEM
data1_sem <- data1_sd/sqrt(data1_n)
data1_semles6_opdracht
Bereken de SEM van data2 (van R object les6_dataset).
Vergelijk se SEM van data1 en data2? Wat is de conclusie?
Klik voor het antwoord
Effect van een uitbijter op de SEM:
# Bereken de SEM van data2
# Hiervoor hebben we nodig:
# (1) de standaard deviatie van data2
# (2) en de hoeveelheid metingen van data2
# (1) sd van data2: zie ook bovenstaande code voor R object les6_dataset_sd
data2_sd <-les6_dataset_sd[2] |> round(digits=2)
# (2) Bepaal grootte van de steekproef (n) van data1 m.b.v. de length() functie
data2_n <- les6_dataset$data2 |> length()
# (3) berekening van de SEM
data2_sem <- data2_sd/sqrt(data2_n)
data2_sem
# SEM van data2 is groterDe SEM wordt vervolgens weer gebruikt om 95% betrouwbaarheidsintervallen (95%BI) mee uit te rekenen (en wordt ook gebruikt in de formule van de t-testen).
Formule voor het betrouwbaarheidsinterval (BI): \[ \text{BI} = \bar{x} \pm t \cdot SEM \]
Voor het uitrekenen van een BI moeten we het gemiddelde en de t-waarde bepalen. Als de grootte van de steekproef (n) ≥ 50 gebruiken 1.96 als t-waarde. Als de grootte van de steekproef (n) < 50 zoeken we de t-waarde op in een tabel. In R gebruiken we een de functie qt() die dat voor ons doet (de t in de naam van de functie staat voor t-verdeling).
R code om (handmatig) het 95% BI uit te rekenen van de eerste dataset (data1):
# (1) mean van data1: zie ook bovenstaande code voor R object les6_dataset_mean
les6_dataset_mean <-les6_dataset |> map_dbl(mean)
data1_mean <-les6_dataset_mean[1]
# bepaal de t-waarde
# Als grootte steekproef < 50 bepaal de t-waarde met de qt() functie gebaseerd op aantal vrijheidsgraden (df)
# Als grootte steekproef >=50, t-waarde = 1.96
# 0.975 = 95%BI, 0.995 = 99%BI
if (data1_n < 50) {
t_waarde <- qt(0.975, df = data1_n - 1)
} else {
t_waarde <- 1.96 # Approximation from standard normal distribution
}
# Bereken lower en upper limiet van het 95% BI
data1_BI95_lower <- (data1_mean - t_waarde * data1_sem) |> round(digits=2)
data1_BI95_upper <- (data1_mean + t_waarde * data1_sem) |> round(digits=2)
#print limieten 95% BI van data1
data1_BI95_lower
data1_BI95_upper les6_opdracht
Bereken het 95% BI voor dataset2
Wordt het steekproefgemiddelde als schatting voor het populatie gemiddelde meer of minder nauwkeuriger?Bereken voor beide datasets het 99% BI
Wordt het 99%BI groter of kleiner in vergelijking met het 95%BI
Klik voor het antwoord
#In het bovenstaande voorbeelden hebben we de formule voor het BI stap voor stap uitgewerkt.
# In R is er een formule die het BI direct kan uitrekenen: t.test()
# Geef de confidence levels aan 95%BI=0.95 en 99%BI=0.99. Deze getallen wijken net iets af van de qt() formule
# Dat heeft te maken met de standaard instelling van één- en tweezijdig toetsen
# In combinatie met de map() functie kunnen we het voor beide dataset tegelijkertijd het BI uitrekenen
les6_dataset |> map(t.test,conf.level=0.95) |> map("conf.int") |> map(round, digits=2)
les6_dataset |> map(t.test,conf.level=0.99) |> map("conf.int") |> map(round, digits=2)
# 95% BI is groter voor data2 (met de uitbuiter)
# 99% BI is voor beide datasets groter in vergelijking met het 95%BIHet is dus zeer belangrijk om uitbijters op te sporen en indien verantwoord te verwijderen. Het doel van een (goede) steekproef is om representatief te zijn voor de populatie en uitbijters verstoren hoe goed een steekproef representatief is voor de populatie. De beste manier om uitbijters op te sporen is een combinatie van beschrijvende statistiek zoals het berekenen van de standaarddeviatie, variatie-coëfficiënt en visualisatie van de data met behulp van distributieplots, boxplots, dotplots en staafdiagrammen+error bars (zie les5). Een laatste kritsich punt over uitbijters is dat de uitbijter ook een interessante observatie kan zijn die verder onderzocht moet worden. Misschien is de uitbijter wel de uitzondering van de regel en heb je iets interessants ontdekt.
LET OP: In de data-analyse mag je alleen een uitbijter verwijderen als je het kan onderbouwen met een statistische test, berekening of als er een goede reden is (bijvoorbeeld een vermijdbare fout). Verwijder de uitbijter nooit direct uit de ruwe data. Beschrijf altijd welke methode er gebruikt is om een uitbijter te verwijderen en leg dit vast in een R script.
Hieronder worden een aantal methoden beschreven in R om uitbijters op te sporen en te verwijderuen uit de dataset.
Dixon’s Q test
Deze test kan alleen gebruikt worden bij herhaaldelijke metingen en onder de voorwaarde dat er maar één uitbijter aanwezig is. Deze test kan dus alleen gebruikt worden bij technische replica’s en niet bij biologische replica’s. In de cursus TLSC-DAVE1V-24 les2 paragraaf Dixons Q-test hebben jullie geleer hoe je in Excel en met een tabel kan bepalen of één meetwaarde een uitbijter is. In R kunnen we dit automatisch berekenen met behulp van de dixon.test() functie van het “outliers” packages.
De dixon.test() berekent een p-value. Met behulp van deze p-waarde wordt de nulhypothese (H0) geaccepteerd of verworpen. Als de H0 wordt verworpen, wordt de alternatieve hypothese (H1) geaccepteerd.
H0: De laagste / hoogste waarde in de dataset is geen uitbijter
H1: De laagste / hoogste waarde in de dataset is wel een uitbijter
P-waarde van de dixon.test() ≥ 0.05: H0 wordt geaccepteerd. Er is geen uitbijter aanwezig in de dataset
P-waarde van de dixon.test() < 0.05: H0 wordt verworpen en de H1 wordt geaccepteerd. Er is wel een uitbijter aanwezig in de dataset
Voor het uitvoeren van de Dixon’s Q test gebruiken we de functie dixonx.test() van de outliers package.
R code om om te bepalen of er één uitbijter aanwezig is m.b.v. de Dixon’s Q test
# Met de standaard instellingen selecteert dixon.test() ...
# de meetwaarde die het verst afligt van het gemiddelde.
# dixon test op data1 van object les6_dataset
dixon.test(les6_dataset$data1)
# dixon test op data2 van object les6_dataset
dixon.test(les6_dataset$data2)
# of met behulp van de map() functie zodat' beide datasets getest kunnen worden
les6_dataset |> map(dixon.test)De output van de Dixon Q test voor data1 ziet er als volgt uit:
Dixon test for outliers
data: les6_dataset$data1
Q = 0.2, p-value = 0.8718
alternative hypothesis: highest value 8 is an outlier
De p-value = 0.8718 en dat is groter dan 0,05. De H0 wordt geaccepteerd en er is geen uitbijter aanwezig in de dataset. De waarde die getest wordt als uitbijter staat genoteerd in de alternatieve hypothese. In dit voorbeeld is dat 8
De output van de Dixon Q test voor data2 ziet er als volgt uit:
Dixon test for outliers
data: les6_dataset$data2
Q = 0.70588, p-value < 2.2e-16
alternative hypothesis: highest value 20 is an outlier
De p-value = 2.2e-16 en dat is kleiner dan 0,05. De H0 wordt verworpen en de H1 wordt geaccepteerd. Er is wel een uitbijter aanwezig in de dataset. De waarde die getest wordt als uitbijter staat genoteerd in de alternatieve hypothese. In dit voorbeeld is dat 20
Om de uitbijter te verwijderen kunnen we de uitbijter vervangen voor NA (not applicable). Dat kan met de volgende R code:
# Verwijderen van de uitbijter in data2 met behulp van mutate() i.c.m. een if_else statement
# Mutate() voegt een extra kolom toe, maar omdat we hier dezelfde kolomnaam gebruiken...
# namelijk data2, wordt data2 vervangen en niet extra aangemaakt
# De if_else statement bestaat uit drie onderdelen:
# (1) conditie
# (2) als conditie = TRUE, voer deze actie uit
# (3) als conditie = FALSE, voer deze actie uit
# (1) data2 == 20. Als een waarde in data2 is gelijk aan 20
# (2) Als de voorwaarde klopt (=TRUE), doe regel 2, vervang 20 uit data2 voor NA_real...
# (3) Als voorwaarde niet klopt (=FALSE), doe regel 3, gebruik de originele data zoals in data2
les6_dataset <- les6_dataset |>
mutate(data2 = if_else(data2 == 20, NA_real_, data2))les6_opdracht
In folder les6 op de gedeelde map staat bestand les6_opdracht3.txt. Het bestand bevat het percentage alcohol van twee flessen wijn gemeten door 10 studenten.
- Kopiëer bestand les6_opdracht3.txt vanuit de gedeelde map (/home/data/mizi3v/les6) naar de map mizi3v/data/les6 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Laad de data in R
- Sorteer iedere data kolom in dit bestand
- Bepaal of er uitbijters aanwezig zijn in de datasets met behulp van de Dixon’s Q test
- Verwijder de uitbijters
- Maak de data tidy
- Bepaal het gemiddelde en de standaard deviatie
- Maak een staafdiagram + error bars van het gemiddelde alcohal percentage voor iedere fles
Klik voor het antwoord
# les6_opdracht1
# (1) Inlezen van de data. Let op de data heeft een komma als decimaal teken
# Dat moet expliciet aangegeven worden met de locale() functie
les6_opdracht3 <-read_tsv("data/les6/les6_opdracht3.txt",
locale = locale(decimal_mark = ","))
# (2) Sorteer de data van fles1 en fles2 om te zien wat de hoogste en laagste waarden zijn
les6_opdracht3 |>
select(fles1, fles2) |>
map(sort)
# (3) Test of er uitbijters aanwezig zijn in de dataset
les6_opdracht3 |>
select(fles1, fles2) |>
map(dixon.test)
# In data kolom fles1 is 15.9 een uitbijter
# In data kolom fles2 is 8.1 een uitbijter
# (4) Vervang de uitbijters door NA
les6_opdracht3 <- les6_opdracht3 |>
mutate(fles1= if_else(fles1 == 15.9, NA_real_, fles1),
fles2= if_else(fles2 == 8.1, NA_real_, fles2))
# (5) Maak de data tidy
les6_opdracht3_tidy <- les6_opdracht3 |>
select(fles1, fles2) |>
pivot_longer(cols=c("fles1","fles2"),
names_to="fles",
values_to = "percentage")
# (6) Bereken het gemiddelde en de standaard deviatie
les6_opdracht3_tidy_summarize <- les6_opdracht3_tidy |>
group_by(fles) |>
summarize(perc_gem=mean(percentage, na.rm=TRUE),
perc_sd = sd(percentage, na.rm=TRUE))
# (7) Maak een staaf diagram + error bars
les6_opdracht3_tidy_summarize |>
ggplot(aes(x=fles, y=perc_gem))+
geom_col()+
geom_errorbar(aes(ymin=perc_gem-perc_sd,
ymax=perc_gem+perc_sd),
width=.2)+
labs(title = "Alcohol percentage van twee flessen wijn",
x="fles",
y="gemiddelde alcohol percentage (%)") +
theme_minimal()IQR methode
In les5 hebben we gezien dat boxplots uitbijters aangeven. Uitbijters in een boxplot worden gedefiniëerd als meetwaarden die
- kleiner zijn dan 1ste kwantiel - 1.5 x IQR
- groter zijn dan 3de kwantiel + 1.5 IQR
R code om de grenzen te berekenen voor het bepalen of een meetwaarde een uitbijter is:
les6_dataset2 <- tibble(data=c(2,3,4,5,4,6,7,8,3,11,6,8,20))
q1 <- quantile(les6_dataset2$data, 0.25, type=2)
q3 <- quantile(les6_dataset2$data, 0.75, type=2)
les6_dataset2_iqr <- IQR(les6_dataset2$data, type=2)
lower_boundary <- q1 - 1.5 * les6_dataset2_iqr
upper_boundary <- q3 + 1.5 * les6_dataset2_iqrMet de uitgerekende grenzen (lower_boundary en upper_boundary) kunnen we uitbijters eruit filteren. Omdat we niet van te voren weten hoeveel meetwaarden eruit gefilterd gaan worden gebruiken we een iets andere methode dan bij de Dixon’s Q-test omdat bij de Dixon’s Q-test er maar één uitbijter is. Om de data te filteren gebruiken we een index, aangegeven met [] waarbinnen we een conditie kunnen definiëren. Alleen de waarden die voldoen aan de conditie worden gekoppeld aan een nieuw R object.
les6_dataset2_clean <- les6_dataset2[les6_dataset2 >= lower_boundary & les6_dataset2 <= upper_boundary]
# les6_dataset2_clean = nieuw object
# De index [] heeft twee condities die allebei waar moeten zijn. Dat is aangegeven met een &
# conditie 1: les6_dataset2 >= lower_boundary -> de data in object les6_dataset2 moet groter zijn dan de lower_boundary
# conditie 2: les6_dataset2 <= upper_boundary -> de data in object les6_dataset2 moet kleiner zijn dan de upper_boundaryData trimming:
Data trimming is het weglaten van een deel van de laagste en de hoogste meetwaarden. Dit is gebaseerd op twee methoden:
(1) Standaardeviatie: data punten die 2.5 x de standaarddeviatie afwijken van het gemiddelde
(2) Percentage: Bijvoorbeeld het verwijderen van 10 % van de laagste en hoogste scores
De eerste methode kan je nog wel eens tegenkomen in tekstboeken maar is eigenlijk geen goede methode. We hebben namelijk gezien dat een uitbijter het gemiddelde en de standaarddeviatie beïnvloed. Dus een uitbijter rekt de grens op wanneer een meetwaarde een uitbijter is.
les6_dataset3 <- tibble(data=c(2, 3, 4, 5, 3, 4, 20))
les6_dataset3_sd <- sd(les6_dataset3$data)
les6_dataset3_mean <- mean(les6_dataset3$data)
limiet_lower <- les6_dataset3_mean - (2.5 * les6_dataset3_sd)
limiet_upper <- les6_dataset3_mean + (2.5 * les6_dataset3_sd)
limiet_lower
limiet_upper
# De upperlimiet is 21,6 voor een uitbijter. Dus met deze methode is 20 geen uitbijter!!!Met de tweede methode verwijder je extreme meetwaarden door middel van trimming (zie figuur 57)

Figure 57: Beslissingsboom statistische testen
Het verwijderen van meetwaarden klinkt als data manipulatie. Maar het doel van trimming is om de extreme waarden eruit te halen zonder “bias” naar de laagste of hoogste waarden. Op deze manier wordt de steekproef beter representatief voor de populatie. Als we alles links en rechts trimmen komen we uiteindelijk bij de middelste meetwaarde uit, de mediaan.
R code voor data trimming:
# koppelen van data aan object les6_dataset3
les6_dataset4 <- tibble(data1=c(2, 3, 4, 5, 3, 4, 6, 8, 3, 20))
# verwijderen van de laagste en hoogste meetwaarden
# les6_dataset4 wordt gekoppeld aan x
# Op deze manier heb je een generieke code en...
# ...hoef je alleen maar de koppeling met x aan te passen met een nieuwe dataset
# Sorteer de data
les6_dataset4_sorted<-sort(les6_dataset4$data1)
# Koppel de gesorteerde data aan variabele x
x <-les6_dataset4_sorted
# Trim de data met de quantile functie: 0.1 en 0.9 is 10% trimming...
# ... als je 5 % wilt trimmen noteer 0.05 en 0.95 en voor 20% noteer 0.2 en 0.8
trimmed_x <- x[x > quantile(x, 0.1) & x < quantile(x, 0.9)]
trimmed_x## [1] 3 3 3 4 4 5 6 8trimmed_x_mean <- mean(trimmed_x)
trimmed_x_mean## [1] 4.5# Directe berekening van de trimmed mean
les6_dataset4_trimmed <- mean(x, trim = 0.1) # Verwijder 10% van de laagste en hoogste meetwaarden en bereken het gemiddelde
les6_dataset4_trimmed## [1] 4.5les6_opdracht
In folder les6 op de gedeelde map staat bestand les6_opdracht4.txt. Het bestand bevat de originele meetwaarden (ordered data) van figuur 57. De data staat in kolom 2 onder metaboliet.
- Kopiëer bestand les6_opdracht4.txt vanuit de gedeelde map (/home/data/mizi3v/les6) naar de map mizi3v/data/les6 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Laad de data in R
- Trim de data voor 5, 10 en 15% (zoals aangegeven in figuur 57)
- Bereken het gemiddelde, mediaan en standaarddeviatie voor de originele en de getrimde data
- Wat is je conclusie
Klik voor het antwoord
# Inlezezen van de data
les6_opdracht4 <- read_tsv("data/les6/les6_opdracht4.txt")
# sorteren van de data
les6_opdracht4_sort <- sort(les6_opdracht4$metaboliet)
# trimmen van de data voor 5, 10 en 15%
x <- les6_opdracht4_sort
trimmed_x_5 <- x[x >= quantile(x, 0.05) & x <= quantile(x, 0.95)]
trimmed_x_10 <- x[x >= quantile(x, 0.10) & x <= quantile(x, 0.90)]
trimmed_x_15 <- x[x >= quantile(x, 0.15) & x <= quantile(x, 0.85)]
# maak een list van de getrimde data. Een tibble werkt niet....
# omdat er verschillende aantal meetwaarden zijn voor iedere getrimde dataset
trimmed_data<- list(data_non_trimmed=x,
data_trimmed_5=trimmed_x_5,
data_trimmed_10=trimmed_x_10,
data_trimmed_15=trimmed_x_15)
trimmed_data |> map_dbl(mean)
trimmed_data |> map_dbl(median)
trimmed_data |> map_dbl(sd)
# Als alternatief kan je ook voor iedere getrimde dataset afzonderlijk ...
# het gemiddelde, mediaan of standaarddeviatie berekenen
# Bereken het gemiddelde
x_mean_0 <-mean(x)
x_mean_5 <-mean(trimmed_x_5)
x_mean_10 <-mean(trimmed_x_10)
x_mean_15 <-mean(trimmed_x_15)
# Bereken de mediaan
x_median_0 <-median(x)
x_median_5 <-median(trimmed_x_5)
x_median_10 <-median(trimmed_x_10)
x_median_15 <-median(trimmed_x_15)
# Bereken de standaarddeviatie
x_sd_0 <-sd(x)
x_sd_5 <-sd(trimmed_x_5)
x_sd_10 <-sd(trimmed_x_10)
x_sd_15 <-sd(trimmed_x_15)
# Gemiddelde wordt kleiner t.o.v. de originele data.
# Extreme hoogste waarden heeft meeste invloed op het gemiddelde
# Mediaan blijft hetzelfde
# Standaarddeviatie wordt kleiner bij meer trimmingIs de data normaal verdeeld
De andere vereiste voor het uitvoeren van parametrische tests is dat de waarden in de steekproef normaal verdeeld zijn (formeel betekent dit dat de residuen, het verschil van iedere meetwaarde met het het steekproefgemiddelde, zie les5, figuur 49, groene pijlen), normaal verdeeld zijn). Met andere woorden: als de gegevens normaal verdeeld zijn, is het gemiddelde de beste puntschatting met de minste variantie.
BELANGRIJK: Het testen of de data normaal is alleen relevant als de steekproefgroottes < 50. Als de steekproef ≥ 50 is, stelt de centrale limietstelling (CLT) dat de verdeling van steekproefgemiddelden een normale verdeling benadert.
Om te testen of data normaal verdeeld is maken we gebruik van:
- Histogrammen (zie les5)
- Q-Q grafieken
- Berekening van de “skewness” en de “kurtosis”
- Shapiro-Wilk-toets
Q-Q plots
Een Q-Q plot test of de meetwaarden zo goed mogelijk op een referentie lijn liggen. Een Q-Q-plot kan worden gemaakt in ggplot met behulp van de stat_qq() en de stat_qq_line() functies
R code om een Q-Q plot te maken:
# alleen meetwaarden van de regio Sardinia worden geselecteerd m.b.v. filter()
olive_sardinia<- olive |>
filter(region=="Sardinia")
# Q-Q plot voor de palmitic meetwaarden
olive_sardinia |>
ggplot(aes(sample = palmitic)) +
stat_qq() +
stat_qq_line(color = "red") + # stat_qq_line() maakt de referentielijn
theme_minimal()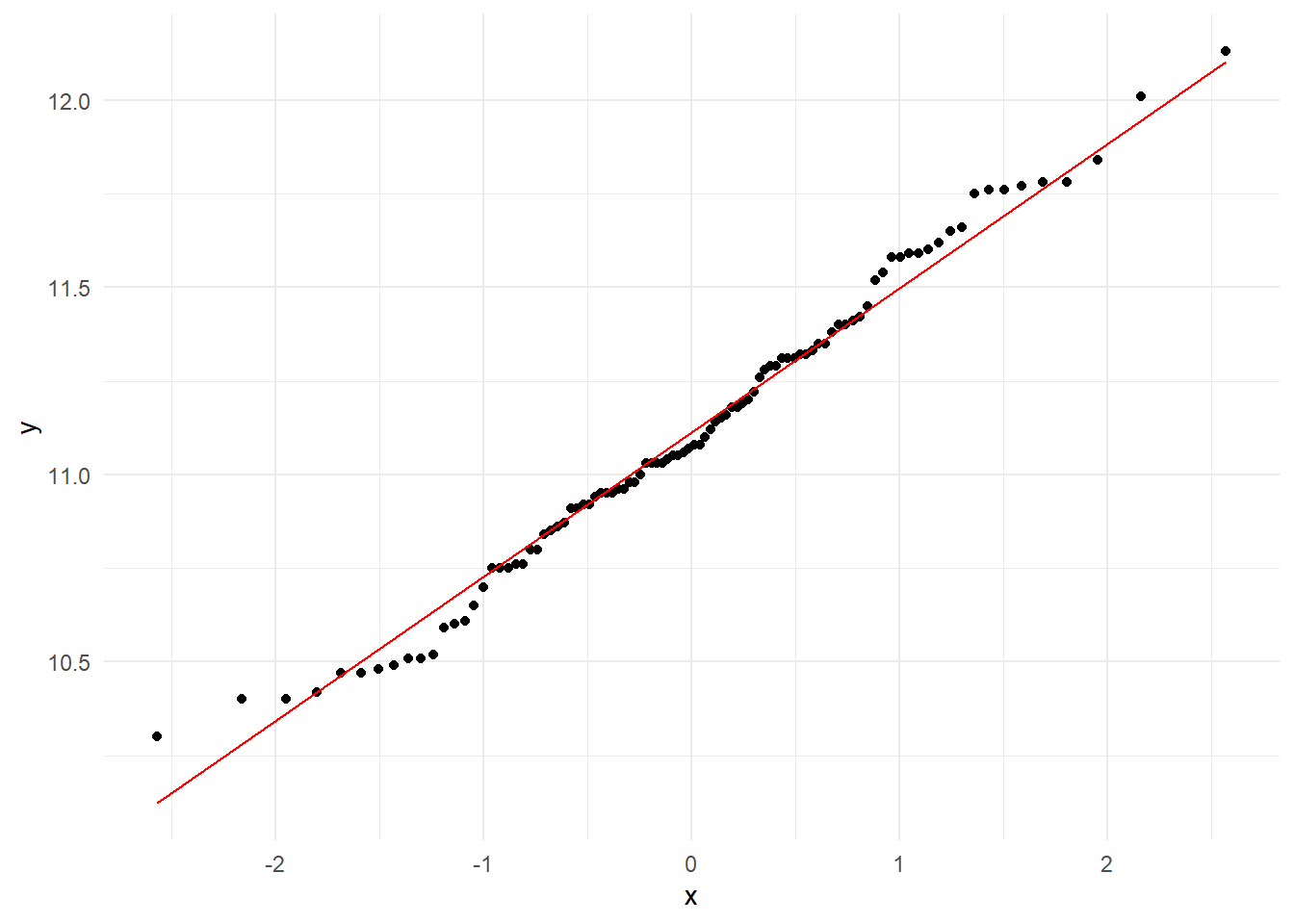
De Q-Q plot van de palmitic data van de regio Sardina laat zien dat de meeste data punten dicht bij de referentielijn liggen.
Laten we de Q-Q plot van Sardinia vergelijken met de andere twee regio’s die in deze dataset aanwezig zijn: Northern Italy en Southern Italy:
olive |>
ggplot(aes(sample = palmitic)) +
stat_qq() +
stat_qq_line(color = "red") +
facet_wrap(~ region, scales = "free") + ## De facet_wrap maakt drie verschillende Q-Q plots gebaseerd op de region
theme_minimal()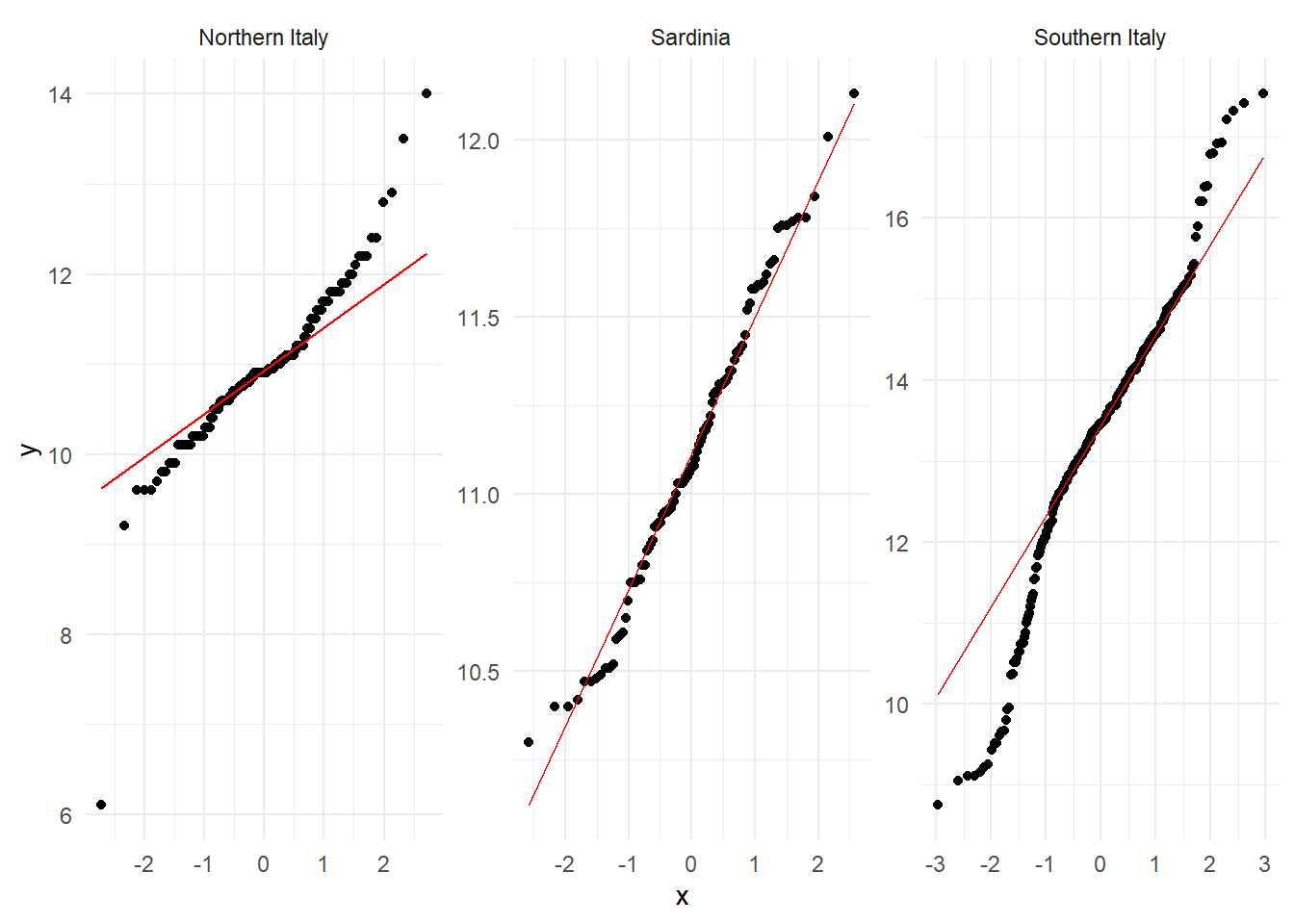
De palmitic data van de Northern Italy en Southern Italy liggen niet allemaal op de referentie lijn. Deze datasets zijn niet normaal verdeeld. Gebruik de onderstaande tabel voor de interpretatie van de Q-Q-plots:
| Patroon | Interpretatie |
|---|---|
| Data ligt op de referentielijn | Data is normaal verdeeld |
| Data ligt boven de referentielijn | Rechts scheve verdeling |
| Data ligt onder de referentielijn | Links scheve verdeling |
| S-vorm | Zware of lichte staarten |
Skewness en Kurtosis
Twee maten die de verdeling aangeven van een dataset zijn:
(1) skewness
(2) kurtosis
Om dit uit te rekeken gebruiken we de skewness() en de kurtosis() functies van de ‘moments’ package. Als de skewness en de kurtosis liggen tussen -2 en 2 is de data min of meer normaal verdeeld met een optimale skewness en kurtosis van 0.
R code voor het bereken van de skewness en de kurtosis:
# skewness en kurtosis voor de palmitic meetwaarden van de verschillende regio's
# de olive dataset is al tidy. Dus we gebruiken group_by() i.c.m. summarize()
olive |>
group_by(region) |>
summarize(sk=skewness(palmitic),
kt=kurtosis(palmitic))De waarden voor de skewness liggen tussen de -2 en 2. De waarden voor de kurtosis zijn groter dan 2 waarbij Northern Italy (11.1) en Soutern Italy (4.1) ver afwijken van de bovengrens. De skewness en kurtosis analyse bevestigt de conclusie van de Q-Q plots. De palmitic data van Northern en Southern Italy is niet normaal verdeeld.
Shapiro-Wilk test
De Shapiro-Wilk test berekent een p-value. Met behulp van deze p-waarde wordt de nulhypothese (H0) geaccepteerd of verworpen. Als de H0 wordt verworpen, wordt de alternatieve hypothese (H1) geaccepteerd.
H0: De data is normaal verdeeld
H1: De data is niet normaal verdeeld
P-waarde van de Shapiro-Wilk test ≥ 0.05: H0 wordt geaccepteerd. De data is normaal verdeeld
P-waarde van de Shapiro-Wilk test < 0.05: H0 wordt verworpen en de H1 wordt geaccepteerd. De data is niet normaal verdeeld
De Shapiro-Wilk test wordt uitgevoerd in R met de shapiro.test()
R code om de Shapiro-Wilk test uit te voeren:
# Shapiro-Wil test voor de palmitic meetwaarden van de verschillende regio's
# de olive dataset is al tidy. Dus we gebruiken group_by() i.c.m. summarize()
olive |>
group_by(region) |>
summarize(sw=(shapiro.test(palmitic)$p.value |> # de output bevat meerdere elementen. We selecteren alleen de p-value met $p.value
round(digits=2) # afronden van de p-waarden op 2 cijfers
)
)De Shapiro-Wilk test geeft de volgende p-waarden:
Northern Italy = 0.00
Sardinia = 0.39
Southern Italy = 0.00
Alleen de p-waarde van Sardinia is groter dan 0.05. De H0 wordt geaccepteerd. De data is normaal verdeeld. Voor de data van Northern en Southern Italy is de p-waarde < 0.05 en wordt de H0 verworpen. De alternatieve H1 wordt aangenomen: de data is niet normaal verdeeld.
Gebruik altijd een combinatie van visualisatie, berekening van skewness en kurtosis en de Shapiro-Wilk test om te bepalen of de data normaal is verdeeld.
les6_opdracht
In folder les6 op de gedeelde map staat bestand les6_opdracht5.txt. Het bestand bevat de looptijd van muizen op een loopband van muizen die niet en wel zijn blootgesteld aan sigaretten rook.
- Kopiëer bestand les6_opdracht5.txt vanuit de gedeelde map (/home/data/mizi3v/les6) naar de map mizi3v/data/les6 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Laad de data in R
- Inspecteer de data en maak de data tidy
- Maak een Q-Q plot voor de “Controle” en de “Rook” groep
- Bereken de p-waarde van de Shapiro-Wilk voor de “Controle” en de “Rook” groep
- Wat is de conclusie?
Klik voor het antwoord
# inlezen van de data
roken <- read_tsv("data/les6/les6_opdracht5.txt")
roken_tidy <- roken|>
pivot_longer(cols=c("Controle", "Rook"),
names_to = "groep",
values_to = "looptijd")
# uitvoeren van de Q-Q-plot met behulp van tidyverse en ggplot
roken_tidy |>
ggplot(aes(sample=looptijd)) +
stat_qq() +
stat_qq_line(color = "red") +
facet_wrap(~ groep, scales = "free") + # met facet wrap maken we drie figuren gebaseerd op de region
theme_minimal()
# Shapiro-wilk test op tidy data
roken_tidy |>
group_by(groep) |>
summarize(sw=(shapiro.test(looptijd)$p.value |>
round(digits=2)
)
)
# conclusie: data van Controle en Rook zijn beide normaal verdeeld gebaseerd op de Q-Q plot en de SW testCasus
In folder les6 op de gedeelde map staat bestand les6_casus_tumor_data.csv.
Het bestand bevat de tumor grootte mm^3 van drie groepen muizen waarvan twee groepen zijn behandeld met een cytotoxische stof waarvan de hypothese is dat de deze stoffen speficiek de tumor cellen vernietigd:
1. control
2. treatment1
3. treatment2
- Kopiëer bestand les6_casus_tumor_data.csv vanuit de gedeelde map (/home/data/mizi3v/les6) naar de map mizi3v/data/les6 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Laad de data in R
- Maak de data tidy
- Gebruik beschijvende statistiek om een eerste indruk te verkrijgen van de data
- Visualiseer de data met een staafdiagram + error bars
- Controleer of er uitbijters aanwezig zijn en indien aanwezig verwijder de uitbijter
- Controleer of de data normaal verdeeld is m.b.v:
- Q-Q plots
- Skewness en kurtosis
- Shapiro-Wilk test
Wat is je conclusie?