Les1 - One_Factor_At_the_Time (OFAT)
Leerdoelen
De student kent / kan :
- Een hypothese en afgeleide stelling formuleren voor een onderzoeksvraag
- De begrippen onafhankelijke variabele, modelsysteem en afhankelijke variabele
- Een “One factor at the time” (OFAT) experiment ontwerpen
- Alle experimentele controles benoemen
- De begrippen populatie en steekproef in de context van een experimenteel ontwerp
- De begrippen ongepaard / gepaard proefopzet en dit toepassen in een OFAT ontwerp
- De begrippen biologische / technische replica’s en dit toepassen in een experimenteel ontwerp
Experimenteel ontwerp stappenplan
Om een onderzoeksvraag te kunnen beantwoorden hebben we een experimenteel ontwerp nodig. In deze cursus gebruiken we hiervoor het volgende stappenplan:
- Formuleer een onderzoeksvraag en hypothese
- Welke factor(en) (onafhankelijke variabele) ga je testen?
- Wat zijn de levels van de factor(en)?
- Welke controles moet ik meenemen in het experiment?
- Keuze voor modelsysteem
- Hoeveel proefobjecten (metingen) per experimentele groep?
- Hoe worden de proefobjecten verdeeld over de groepen?
- Wat ga ik meten (afhankelijke variabele)?
- Hoe ga je meten: gepaard of ongepaard?
- Welke statistische test om de data te analyseren?
In les1 worden alle stappen verder uitgelegd. De controles (stap 3) en hoeveel metingen per experimentele groep (stap 5) worden in detail uitgelegd in les2 en les3.
Onderzoeksvraag
Elk onderzoek begint met een onderzoeksvraag. Voordat je een onderzoeksvraag formuleert bestudeer je de wetenschappelijke literatuur over het betreffende onderwerp. Wat is er al bekend ? Welke theorieën zijn gangbaar en hoe zijn deze tot stand gekomen. Welk bewijs wordt ervoor geleverd. Is dit bewijs voldoende of zitten er “gaten” in de theorie. Is er ruimte voor een alternatieve verklaring. Deze fase bestaat uit verkennen en verdiepen.
Er zijn verschillende soorten onderzoeksvragen en het type onderzoeksvraag bepaalt de experimentele opzet.
- Een beschrijvende onderzoeksvraag: een eigenschap van een populatie wordt beschreven / gekwantificeerd
Voorbeelden van beschrijvende onderzoeksvragen zijn:
- Hoe lang duurt de celcyclus van een eukaryote cel?
- Welke P53 mutaties zijn aanwezig in leukemie cellen?
- Wat is de looproute van olifanten? (Het bestuderen van diergedrag in een natuurlijke omgeving, belangrijk bij natuurbescherming)
- Een correlationele onderzoeksvraag: is er een verband / correlatie tussen twee variabelen?
Voorbeelden van correlationele onderzoeksvragen zijn:
- Is er een verband tussen de duur van de celcyclus van een (eukaryote) cel en glucose concentratie?
- Is er een verband tussen P53-mutaties en de prognose van borstkanker?
- Is er een verband tussen de toename in het aantal olifanten en de hoeveelheid neerslag?
- Is er een correlatie tussen roken en aderverkalking?
Om een beschrijvende of correlationele onderzoeksvraag te beantwoorden wordt er gebruik gemaakt van observationeel onderzoek. In dit type onderzoek worden de proefobjecten niet blootgesteld aan een experimentele behandeling maar worden eigenschappen van de proefobecten gemeten en vastgelegd. Bijvoorbeeld, voor een langlopend gezondheidsonderzoek, zoals de relatie tussen roken en aderverkalking in mensen, wordt per proefobject vastgelegd hoeveel er gemiddeld per dag gerookt wordt en de mate van aderverkalking.
Een alternatieve verklaring voor een correlatie tussen twee variabelen is de aanwezigheid van een derde onbekende variabele, een zogenaamd confounder, die de twee andere variabelen onafhankelijk van elkaar beïnvloedt. Er is bijvoorbeeld aangetoond dat er een correlatie bestaat tussen de hoeveelheid ijs die per week wordt geconsumeerd en het aantal verdrinkingen per week. Een conclusie kan zijn dat ijs eten leidt tot verdrinking, maar een betere verklaring is de aanwezigheid van een derde variabele, namelijk warm weer. Warm weer beïnvloedt zowel de ijsverkoop als het aantal mensen dat gaat zwemmen (en daardoor ook het aantal verdrinkingen). Bij observationeel onderzoek bestaat altijd de kans dat een derde variabele over het hoofd is gezien en niet is meegenomen in de metingen.
Een andere verklaring is dat een correlatie op toeval kan berusten. Dit wordt spurious correlation genoemd. Als je dus heel veel verschillende variabelen test op correlaties zul je altijd wel iets vinden!!
LET OP: Als er tussen twee variabelen een (statistische) correlatie is gevonden betekent dat niet dat er ook een causaal verband is. Bij elke correlatie staat niet vast of factor B wordt beïnvloed door factor A, of dat factor A wordt beïnvloed door factor B. Voor het aantonen van een causaal verband moet er een experiment uitgevoerd worden (= interventie onderzoek)!
- Een vergelijkende onderzoeksvraag:
Om een vergelijkende onderzoeksvraag te beantwoorden wordt gebruik gemaakt van interventie onderzoek (= een experiment). In een experiment worden alle condities hetzelfde gehouden (controlled variables) voor de proefobjecten, behalve de experimentele behandeling. Als er dan een effect wordt gemeten moet dit wel veroorzaakt worden door de experimentele behandeling. Maar dit geldt alleen als het experimentele ontwerp voldoet aan strikte voorwaarden!!
Interventie onderzoek bestaat uit drie componenten die met elkaar verbonden zijn (zie figuur 2).
- experimentele behandeling
- modelsysteem
- afhankelijke variabele
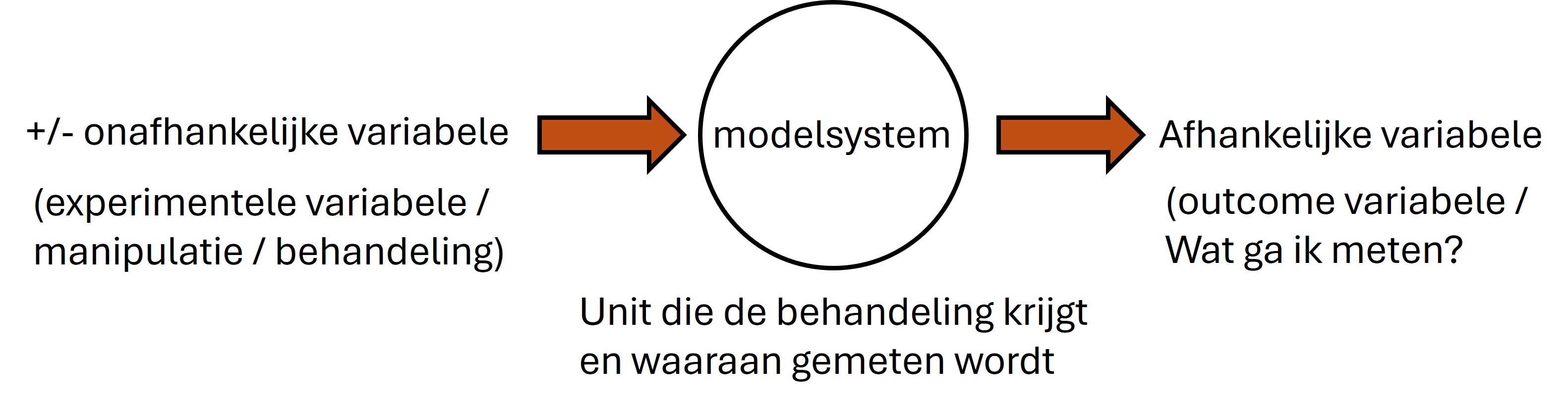
Figure 2: Een experiment bevat een onafhankelijke variabele, een modelsysteem en een afhankelijke variable.
In een gecontroleerde omgeving worden proefobjecten (modelsysteem) blootgesteld aan een experimentele behandeling (onafhanelijke variabele). Na de experimentele behandeling wordt er “iets” (afhankelijke variabele) gemeten aan het proefobject om te bepalen of de experimentele behandeling een effect heeft gehad (zie figuur 2). Een voordeel van experimenteel onderzoek is dat het een beter gecontroleerd systeem is.
De onafhankelijke variabele (=experimentele behandeling) die de proefobjecten ondergaan is vaak fysiek (natuurkundig), fysiologisch, chemisch of genetisch:
- Natuurkundige: temperatuur, stroming (van kleine volumes), licht cyclus, geluidsniveau, UV, irradiatie
- Fysiologische: dieet, lichamelijke inspanning, samenstelling van kweekmedium, 3D cultuur, co-cultuur (kweek van meerdere type cellen)
- Chemische: stoffen die de werking van cellen beïnvloeden door bijvoorbeeld binding aan DNA, eiwitten of celmembranen (bijvoorbeeld testen van geneesmiddelen of natuurlijke ingredienten om celprocessen te beinvloeden), O2 niveaus, pH
- Genetische manipulatie: verwijderen / inactief maken van genen, (over)expressie van genen, aanbrengen van mutaties in het genoom
De onafhankelijke variabele kan één of meerdere “levels” hebben. De “levels” zijn de verschillende waarde of categoriën van de experimentele behandeling die worden getest. Bijvoorbeeld, de experimentele behandeling is stof X die wordt toegevoegd aan cellen om het effect te onderzoeken op de celcyclus. De “levels” zijn de verschillende concentraties van stof X die worden gebruikt in het experiment. Een ander voorbeeld is het testen van de pH op enzymactiviteit. De pH is de factor die getest wordt en de verschillende pH’s (pH 7.0, 7.5 en 8.0) zijn de levels.
LET OP: In de reader wordt de onafhankelijke variabele vanaf nu aangegeven als factor. In deze les behandelen we het “One Factor At the Time” (OFAT) ontwerp en in les4 behandelen multi-factoriale ontwerpen.
Het modelsysteem ondergaat de experimentele behandeling en kan een levend organisme zijn zoals mensen, muizen, ratten, watervlooien, rondwormen, fruitvliegjes, maar ook organen, cellen of onderdelen van cellen zoals celorganellen, eiwitten of DNA. In bijlage 1 staat verdere achtergrondinformatie over de kenmerken van verschillende organisme als modelsystemen.
De afhankelijke variabele is wat je gaat meten aan het modelsysteem. De meting kan op verschillende biologische niveau’s zoals DNA, RNA, eiwit, celorganellen, cellen, organen of een eigenschap van organisme. Het is belangrijk om van te voren te weten wat voor type data er gegeneerd wordt omdat dit de statistische analyse bepaald.
Een ander belangrijk aspect is of de meting direct of indirect is. Bijvoorbeeld, als we willen weten wat het effect is van een bepaald dieet op het gewicht, kan het gewicht direct worden gemeten met behulp van een weegschaal. Als we vervolgens willen weten wat het effect is van het dieet op de concentratie van het stress hormoon cortisol in het bloed, kan dit ook direct gemeten worden met een biochemische assay. Echter als we willen weten hoe gestressed de proefpersoon is dan kunnen we stress niet direct meten. Een indirecte meting is een methode waarbij je een variabele afleidt via een andere variabele die ermee samenhangt en wel is te meten. Om stress niveau’s in personen te meten kunnen we de proefobjecten een vragenlijst laten invullen. Een andere indirecte meting is om de bloedtoevoer te meten in hersengebieden die betrokken zijn bij stress met behulp van een MRI scan. De meting van de bloedtoevoer is dan een indirecte meting voor de hersenactiviteit. De aanname die je hebt gedaan is dat neurale activiteit en bloedtoevoer altijd samengaan, maar dit hoeft niet altijd te correleren. Een indirecte meting moet dus altijd met voorzichtigheid worden geinterpreteerd en gecombineerd worden met andere (indirecte) metingen om de onderzoeksvraag te kunnen beantwoorden.
Voorbeelden van vergelijkende onderzoeksvragen zijn:
- Is er een verschil in de duur van de celcyclus van een (eukaryote) cel gegroeid met een standaard of hoge glucose concentratie?
- Is er een verschil in LDL cholesterol tussen patienten die wel of niet zijn behandeld met medicijn X?
- Is er een verschil in genexpressie van genen die betrokken zijn bij stress response in rondwormen die wel of niet zijn gevoed met verschillende concentraties nanoplastics?
LET OP: Een onderzoeksvraag moet zo specifiek mogelijk geformuleerd worden met een verwijzing naar de onafhankelijke variabele (donkerblauw), afhankelijke variabele (lichtblauw) en het modelsysteem (paars). In het vervolg van deze cursus ligt de focus op de vergelijkende onderzoeksvraag
Hypothese en voorspelling
Vanuit de onderzoeksvraag wordt een hypothese geformuleerd die vervolgens wordt geverifieerd met behulp van een wetenschappelijk experiment. Een hypothese is een veronderstelling of verklaring gebaseerd op de theorie die nog bewezen moet worden. Een hypothese wordt geformuleerd als een stelling (alsof het waar is) en niet als een vraag. Op basis van de hypothese worden voorspellingen gedaan die worden getest met een experiment. Anders geformuleerd, “als mijn hypothese correct is dan verwacht ik een bepaalde observatie (waarneming)”. Als een voorspelling uitkomt kan de hypothese worden bevestigd.
Een klassiek voorbeeld is het experiment van Hershey en Chase: in het begin van de jaren 50 was nog niet bekend of het erfelijk DNA bestond uit DNA of eiwitten. Bij de onderzoeksvraag “waaruit bestaat het erfelijk materiaal in de cel?” zijn de volgende twee hypothesen opgesteld:
- het erfelijk materiaal in de cel bestaat uit DNA
- het erfelijk materiaal in de cel bestaat uit eiwitten
Om de twee hypotheses de testen werden bacteriën geïnfecteerd met bacteriofagen met radioactief gelabeld DNA of bacteriofagen met radioactief gelabelde eiwitten. Hieruit volgden twee voorspellingen:
Als het erfelijk materiaal in de cel bestaat uit DNA verwacht ik radioactiviteit te meten in bacteriën die geinfecteerd zijn door bacteriofagen met radioactief gelabelled DNA.
Als het erfelijk materiaal in de cel bestaat uit eiwitten verwacht ik radioactiviteit te meten in bacteriën die geinfecteerd zijn door bacteriofagen met radioactief gelabelled eiwitten.
Als een voorspelling uitkomt dan wordt de bijbehorende hypothese aannemelijker. De onderzoekers detecteerden alleen radioactiviteit in bacteriën die geïnfecteerd waren door bacteriofagen met radioactief gelabelled DNA. Hieruit concludeerden de onderzoekers dat hypothese I aannemelijker was en hypothese 2 werd verworpen. Een hypothese blijft net zolang aannemelijk totdat een ander experiment het tegendeel bewijst. Een hypothese kan dus altijd weerlegd worden door een ander experiment. Dit wordt falsificeerbaarheid genoemd.
les1_opdracht
Vul in voor de proefopzet van Hershey en Chase:
Factor (behandeling):
Modelsysteem:
Afhankelijke variabele (wat ga ik meten?):
Klik voor het antwoord
Factor: infectie met radioactief gelabelde fagen (DNA of eiwit)Modelsysteem: bacteriën
Afhankelijke variabele (wat ga ik meten?): radioactiviteit in het binnenste van geïnfecteerde bacteriën
les1_opdracht
Een onderzoeker heeft de volgende onderzoeksvraag:
Is er een verschil in genexpressie van genen die betrokken zijn bij stress response in rondwormen die wel of niet zijn gevoed met verschillende concentraties nanoplastics?
Benoem het modelsysteem, factor en afhankelijke variabele die bij de onderzoeksvraag horen:
Modelsysteem:
Factor (behandeling):
Afhankelijke variabele (wat ga ik meten?):
Formuleer een hypothese en een stelling voor de onderzoeksvraag:
Hypothese:
Voorspelling:
Klik voor het antwoord
Modelsysteem: rondwormenFactor (behandeling): nanoplastics
Afhankelijke variabele (wat ga ik meten?): genexpressie van genen die betrokken zijn bij stress response
hypothese: nanoplastics activeren stress response genen in rondwormen
voorspelling: als de hypothese klopt dan verwacht ik meer mRNA moleculen te meten van stressreponse genen in rondwormen die blootgesteld zijn aan nanopplastics.
les1_opdracht
Een onderzoeker heeft de volgende onderzoeksvraag:
Is er een verschil in de duur van de celcyclus van een (eukaryote) cel gegroeid met een standaard of hoge glucose concentratie?
Benoem het modelsysteem, factor en afhankelijke variabele die bij de onderzoeksvraag horen:
Modelsysteem:
Factor (behandeling):
Afhankelijke variabele (wat ga ik meten?):
Formuleer een hypothese en een stelling voor de onderzoeksvraag:
Hypothese:
Voorspelling:
Klik voor het antwoord
Modelsysteem: (eukaryote) celFactor (behandeling): glucose concentratie
Afhankelijke variabele (wat ga ik meten?): duur van de celcyclus
hypothese: met een hoge glucose concentratie zal de celcyclus korter zijn.
voorspelling: als de hypothese klopt dan verwacht ik een hogere celconcentratie te meten van cellen die gegroeid zijn in hoog glucose.
One Factor At the Time (OFAT)
Er zijn verschillende experimentele ontwerpen in de Life Science. In deze les behandelen het OFAT ontwerp en in les4 gaan we verder met multifactorial ontwerpen. Bij een OFAT ontwerp wordt één factor getest. Het OFAT ontwerp wordt verder uitgewerkt aan de hand van de volgende twee onderzoeksvragen:
Onderzoeksvraag1:
Is er een verschil in LDL cholesterol tussen patiënten die wel of niet zijn behandeld met medicijn X?
Medicijn X is de factor die getest wordt met één level namelijk de concentratie van 50 mg / kg (zie figuur 3A). Het minimaal aantal experimentele condities is het aantal levels + de negatieve controle (zie figuur 3B). De negatieve controle is de experimentele groep die de behandeling niet krijgt. Alle andere condities (dit zijn de gecontroleerde variabelen) zijn hetzelfde tussen de experimentele groepen. De negatieve controle meet de achtergrondwaarde (=referentiewaarde) als we de proefobjecten niet behandelen. Om statistisch te bepalen of een behandeling een effect heeft gehad worden de meetwaarden van de behandelde groep(en) altijd vergeleken met de meetwaarden van de negatieve controle.
Een experiment moet altijd een negatieve controle bevatten en indien mogelijk positieve en specificiteits controles. Dit wordt verder uitgelegd in les2.
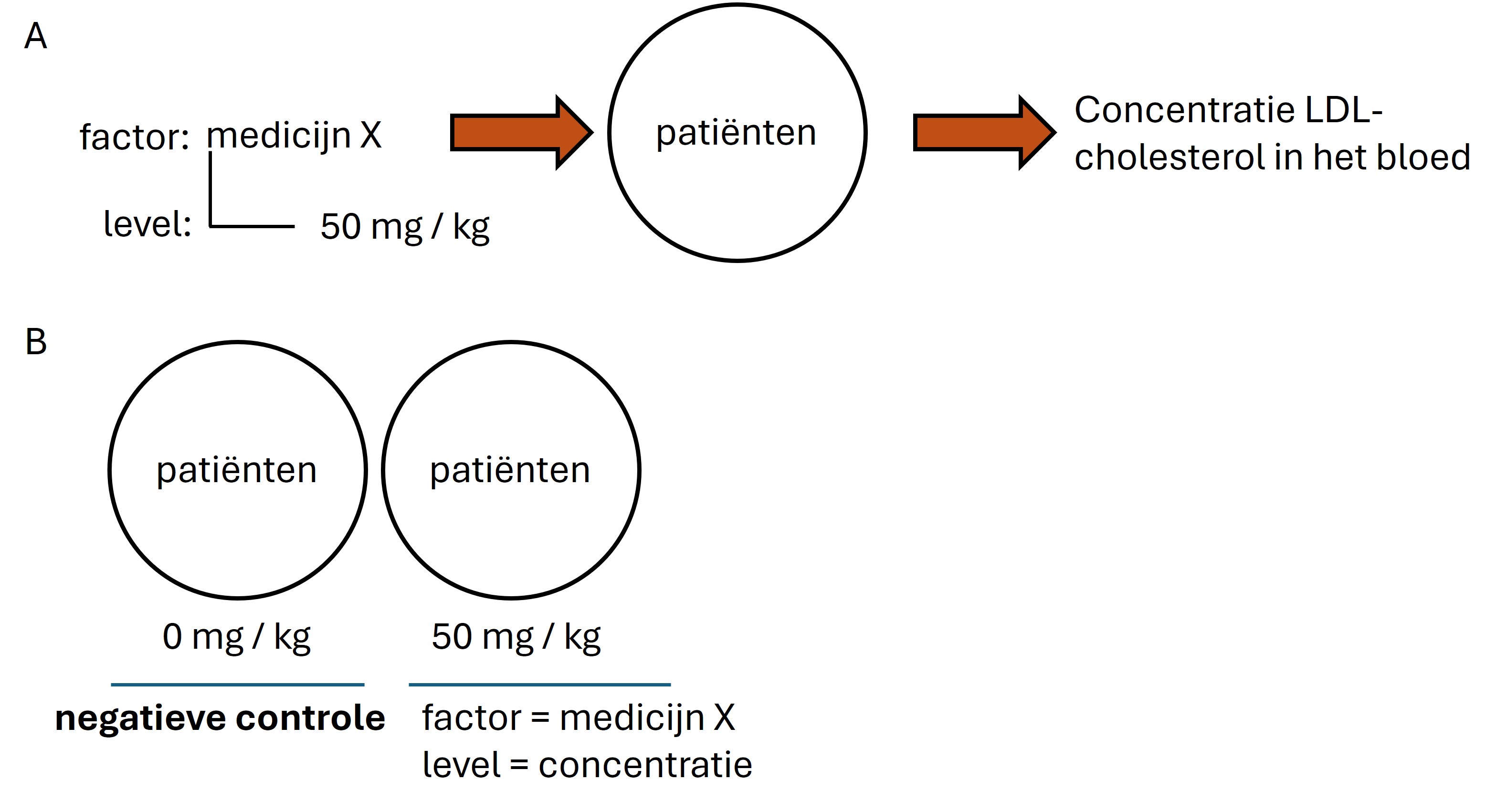
Figure 3: (A) De behandeling bestaat uit medicijn X met een concentratie van 50 mg / kg. (B) Het aantal experimentele condities bestaat uit de experimentele behandeling + een groep die de behandeling niet krijgt (=negatieve controle).
Onderzoeksvraag2:
Is er een verschil in de cellulaire opname van nanoplastics tussen rondwormen die blootgesteld zijn aan nanoplastics met verschillende diameters?
Nanoplastics is de factor die getest wordt met drie levels namelijk de nanoplastics hebben een verschillende grootte van 20, 50 en 100 nm (zie figuur 4A). De concentratie van de nanoplastics en de tijd van blootstelling zijn hetzelfde tussen experimentele condities. Het minimaal aantal experimentele condities is het aantal levels + de negatieve controle (zie figuur 4B).
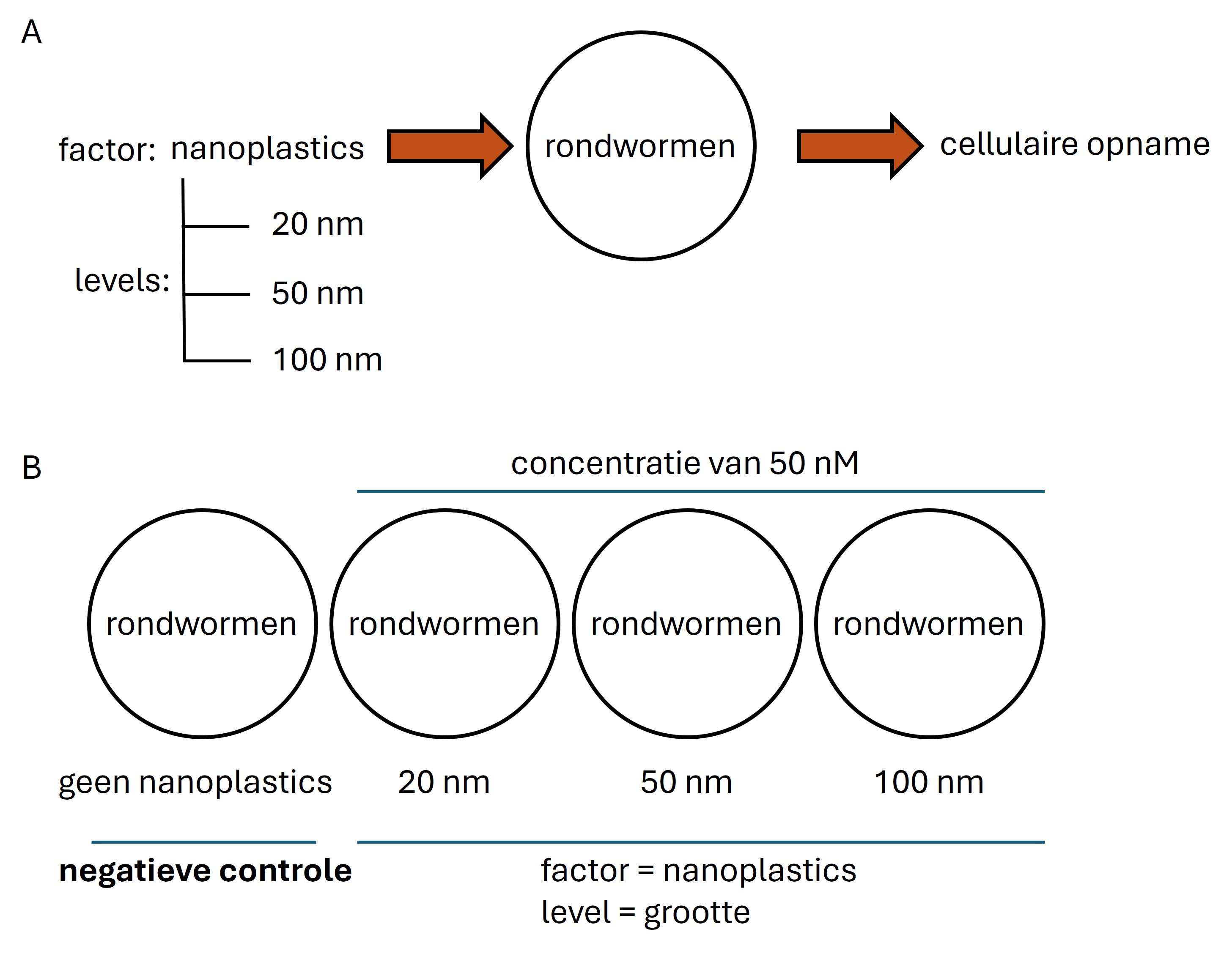
Figure 4: (A) De behandeling bestaat uit nanoplastics (=factor) met een grootte van 20, 50 en 100 nm (=levels) die in dezelfde concentraties (50 nM) worden toegevoegd aan de proefobjecten (B) het aantal experimentele condities bestaat uit de experimentele behandelingen + een groep die de behandeling niet krijgt (=negatieve controle)
In het voorbeeld van figuur 4 zijn er twee vragen die je wilt beantwoorden.
- Is er een opname van nanoplastics in de cellen van de rondworm?
- Als de nanoplastics worden opgenomen in de cellen, is dit dan afhankelijk van de grootte van de nanoplastics?
Een belangrijk onderdeel van een experimentele behandeling is de duur van de experimentele behandeling en in het geval van een chemische behandeling met welke concentratie er getest wordt voordat je een effect verwacht. Voor het bepalen van de concentratie is de EC50 / IC50 waarde een goed startpunt onder de voorwaarde dat het experiment dat uitgevoerd is om de EC50 / IC50 waarde te bepalen aansluit bij het experiment dat je wilt uitvoeren. Bijvoorbeeld, een EC50-waarde gebaseerd op rondwormen zal waarschijnlijk minder relevant zijn voor humane organoids. Als er een (relevante) EC50 bekend is, kan dat als richtlijn dienen voor het testen van verschillende concentraties. Vaak wordt er dan één level onder en één level boven de EC50 waarde getest. Het is belangrijk dat de gekozen levels fysiologisch relevant zijn en dat de hoogste level(s) niet algeheel toxisch zijn voor het modelsysteem.
De tijd van blootstelling kan ook als factor geïntroduceerd worden in het experimenteel ontwerp (zie figuur 5). De verschillende levels zijn dan de duur van blootstelling (zie figuur 5).
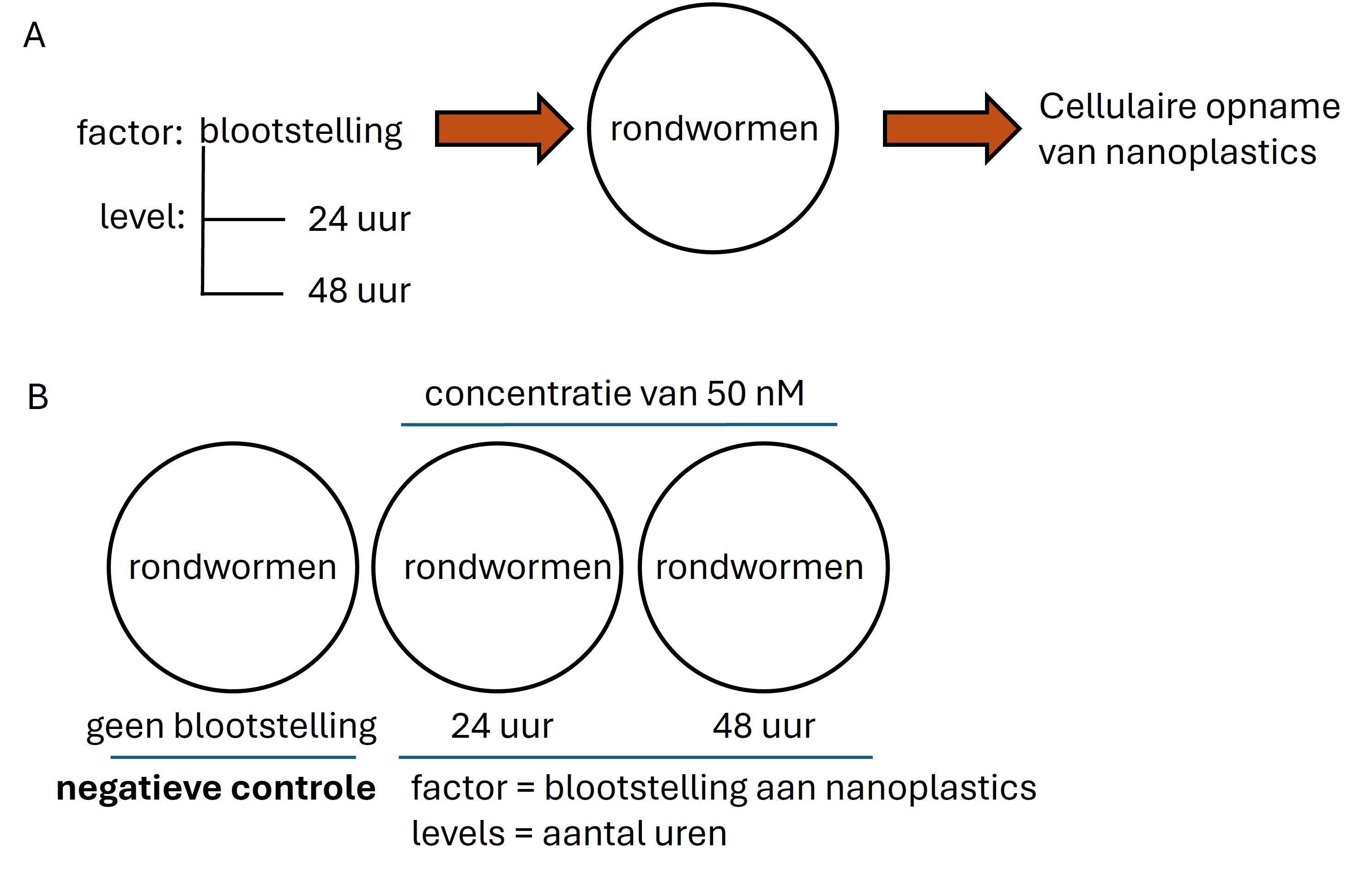
Figure 5: (A) De behandeling bestaat uit blootstelling aan nanoplastics (=factor) voor een duur van 24 en 48 uur (=levels) (B) het aantal experimentele condities bestaat uit de behandelingen + een groep die de behandeling niet krijgt (=negatieve controle)
In het voorbeeld van figuur 5 zijn er twee vragen die je wilt beantwoorden.
- Is er een opname van nanoplastics in de cellen van de rondworm?
- Als de nanoplastics worden opgenomen in de cellen, is dit dan afhankelijk van de duur van blootstelling?
In het experiment van figuur 5 wordt alleen de duur van blootstelling aan nanoplastics getest waarbij voor iedere testconditie dezelfde concentratie en grootte van nanoplastics is gebruikt. Als je deze eigenschappen ook wilt testen in combinatie met de duur van de blootstelling maken we geen gebruik van een OFAT ontwerp maar van een multiple factor ontwerp (zie les4).
les1_opdracht
Een onderzoeker test het effect van LPS op Reactive Oxygen Species (ROS) productie in raw cellen. De onderzoeker wil drie concentraties LPS testen.
Wat zijn de experimentele condities (werk uit zoals weergegeven in figuur 3,4 en 5)
Klik voor het antwoord
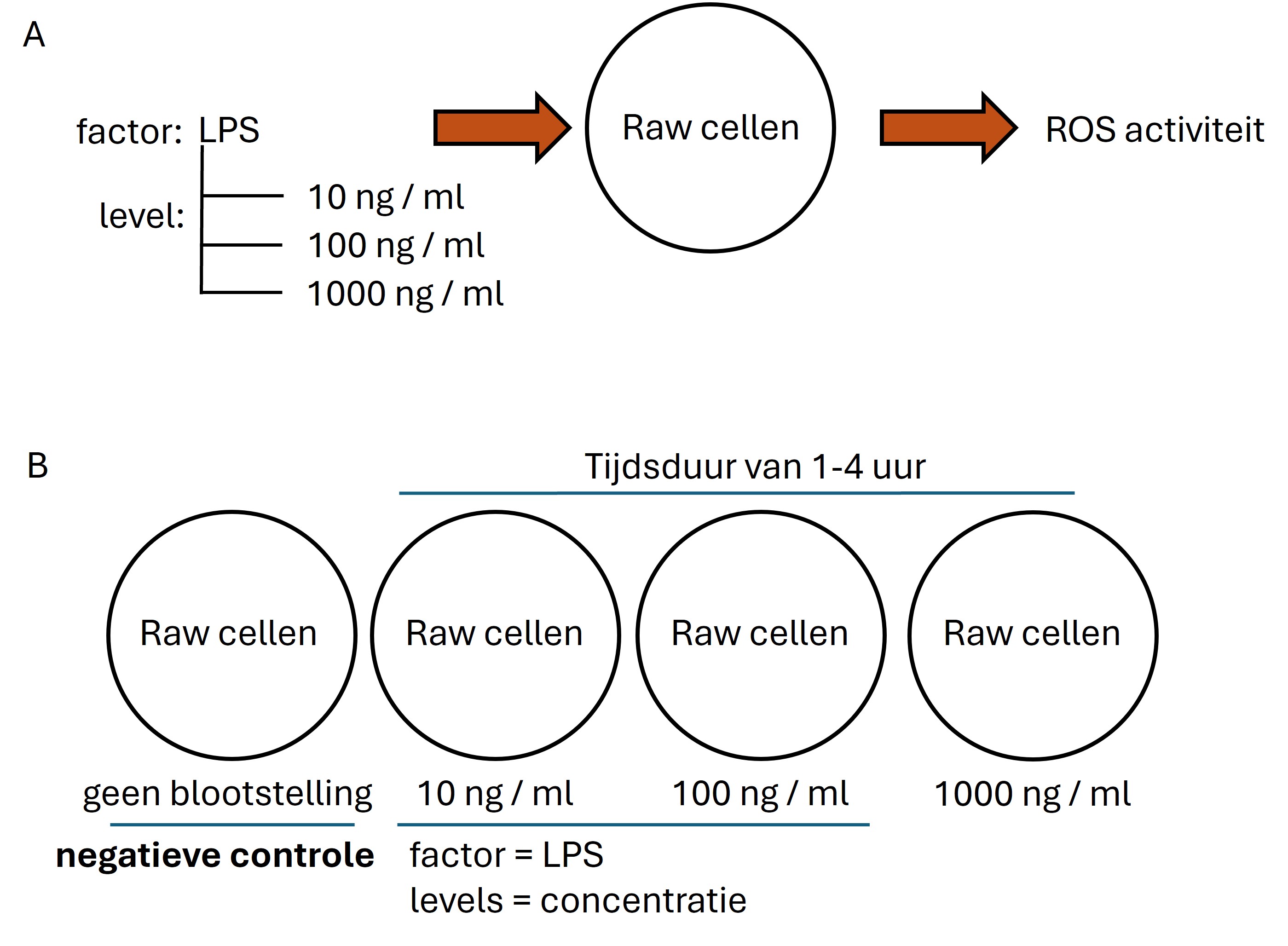
Grootte van de steekproef
Nadat de experimentele condities zijn bepaald (inclusief controles), is de volgende vraag hoe groot de steekproef moet zijn voor iedere experimentele conditie. Met andere woorden, hoeveel biologische replica’s per experimentele conditie. Een steekproef moet altijd groot genoeg zijn zodat de steekproef representatief is voor de populatie. Een belangrijke vraag in het experimenteel ontwerp is hoe groot een steekproef moet zijn. Wat is de minimale hoeveelheid proefobjecten per experimentele conditie zodat je betrouwbare meetresultaten verkrijgt en eventuele effecten van de behandeling statistisch kan aantonen.
Als we één meting doen voor iedere experimentele conditie krijgen we geen goed representatief beeld van de populatie. Eén meting kan immers afwijken van de rest van de metingen. Een te kleine steekproef noemen we een underpowered experiment. De steekproef is niet representatief voor de populatie en een eventueel effect van de experimentele behandeling kan nooit statistisch aangetoond worden.
Met een grote steekproef verkrijgen we een beter representatief beeld van de populatie en is het experiment gevoeliger om eventuele effecten van de experimentele behandeling statistisch aan te tonen. Echter als de steekproef heel groot is zijn de experimenten tijdrovend en kostbaar. En als je werkt met muizen of ratten (of andere vertebrate proefdieren) is het onethisch om (te)veel proefdieren te gebruiken. Het is landelijk beleid om het gebruik van proefdieren te verminderen. Een ander nadeel van een grote steekproef is dat het mogelijk is om zeer kleine verschillen tussen de experimentele groepen statistisch aan te tonen die niet biologisch relevant zijn. In dat geval is het een overpowered experiment. Hoe groot een steekproef moet zijn om biologische relevante verschillen tussen experimentele groepen aan te tonen kan berekend worden met power analyse en dit wordt in les3 verder uitgewerkt.
Natuurlijke en technische variatie
In een OFAT experiment zijn dus (minimaal) twee experimentele condities: een referentie groep (= controle groep) en een behandelde groep.
In een ideaal (fictief) experiment is er geen verschil in de meetwaarden tussen de proefobjecten voor aanvang van het experiment (zie figuur6, linker panel). De groepen hebben precies hetzelfde gemiddelde. Als er een verschil wordt gemeten tussen de groepen na de experimentele behandeling (= effect) moet dit wel door de behandeling komen (zie figuur6, rechter panel, gele verticale lijn). In deze proefopzet is er geen ruis in het experiment en daarom is het mogelijk om met een zeer kleine steekproef een effect aan te tonen van de experimentele behandeling.
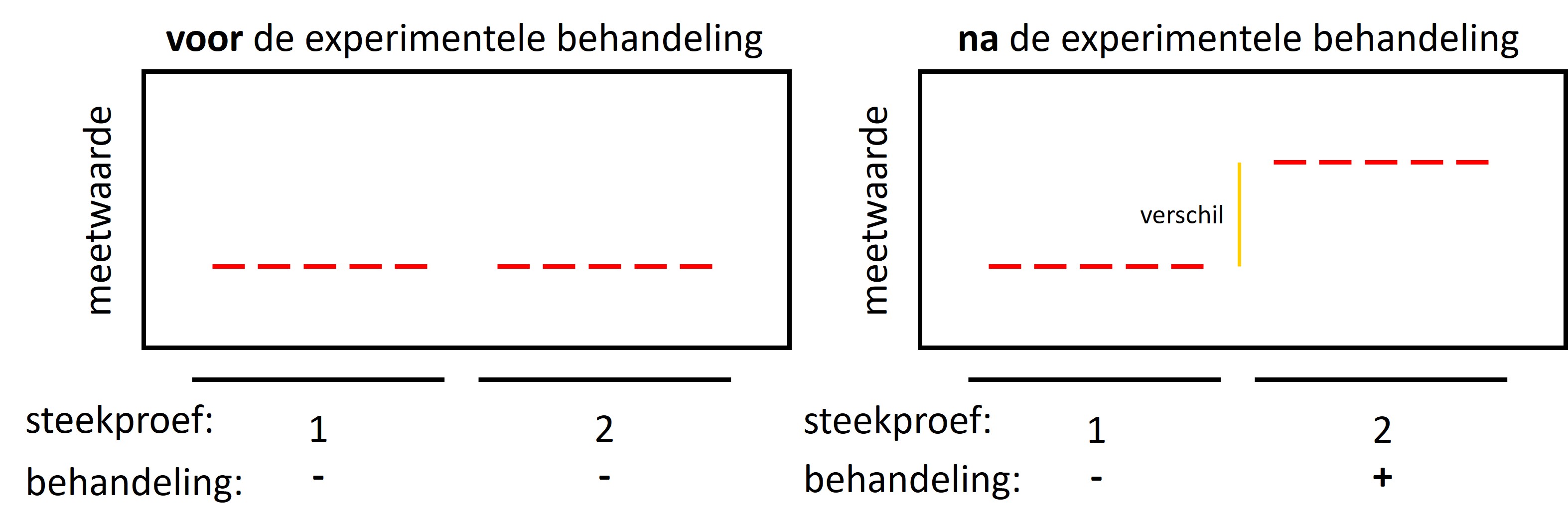
Figure 6: In een ideaal (fictief) experiment zijn, voor aanvang van het experiment, de meetwaarden van de proefobjecten gelijk in de groepen en tussen groepen (zie figuur links; iedere groep heeft 5 metingen). Het verschil in de metingen, na de behandeling, kan alleen veroorzaakt zijn door de behandeling (zie figuur rechts
Het principe van een experiment is dat alle condities hetzelfde zijn tussen de groepen die je wilt vergelijken, behalve de experimentele behandeling die je wilt onderzoeken. Als er dan een verschil wordt gemeten tussen de groepen moet deze verandering wel veroorzaakt zijn door de behandeling.
Het experiment zoals weergegeven in figuur 6 is in de Life Science niet mogelijk. Er is namelijk altijd ‘ruis’ die voorafgaand aan het experiment al aanwezig was en dit wordt veroorzaakt door natuurlijke variatie.
Natuurlijke variatie
De meeste eigenschappen van een organisme volgen een normaal verdeling in de populatie. Er is dus altijd variatie in de populatie voor wat je wilt gaan meten. In de wetenschap werken we altijd met een steekproef. Het is namelijk onmogelijk om de hele populatie te meten. De steekproef moet representatief zijn voor de populatie. Twee steekproeven uit dezelfde populatie zullen nooit precies hetzelfde gemiddelde hebben voor wat je gaat meten (bijvoorbeeld lengte, gewicht, bloeddruk enzovoorts). Als er uit een populatie twee steekproeven van 2 x 10 proefobjecten worden geselecteerd zal er dus altijd onderlinge verschillen (= variatie) zijn tussen de proefobjecten. Dit is de natuurlijke variatie. Daarom zal de gemiddelde meetwaarde van wat je gaat meten in het experiment voor iedere groep verschillend zijn voorafgaand aan de behandeling. Het toeval bepaalt hoe groot dit verschil zal zijn tussen de experimentele groepen en dit verschil kan zowel groter als kleiner zijn ten opzichte van elkaar. In een experiment wil je dat dit verschil tussen de groepen voorafgaand aan de experimentele behandeling zo klein mogelijk is. Dit kan bereikt worden door een homogene populatie of door een grote steekproef (of een combinatie).
Als de natuurlijke variatie in een populatie groot is (er is onderling veel variatie in wat je wilt gaan meten) dan is een grote steekproef nodig om representatief te zijn voor de populatie. In een kleine steekproef zijn de onderlinge verschillen groter in vergelijking met een grote steekproef (zie figuur 7, vergelijk de steekproeven met n=5 en n=10 biologische replica’s. De gestippelde lijn geeft het gemiddelde van de groep aan). Een representatieve steekproef zorgt er dus voor dat twee steekproeven uit dezelfde populatie min of meer hetzelfde gemiddelde hebben die dicht bij elkaar liggen, hoewel de gemiddelden nooit precies hetzelfde zullen zijn.
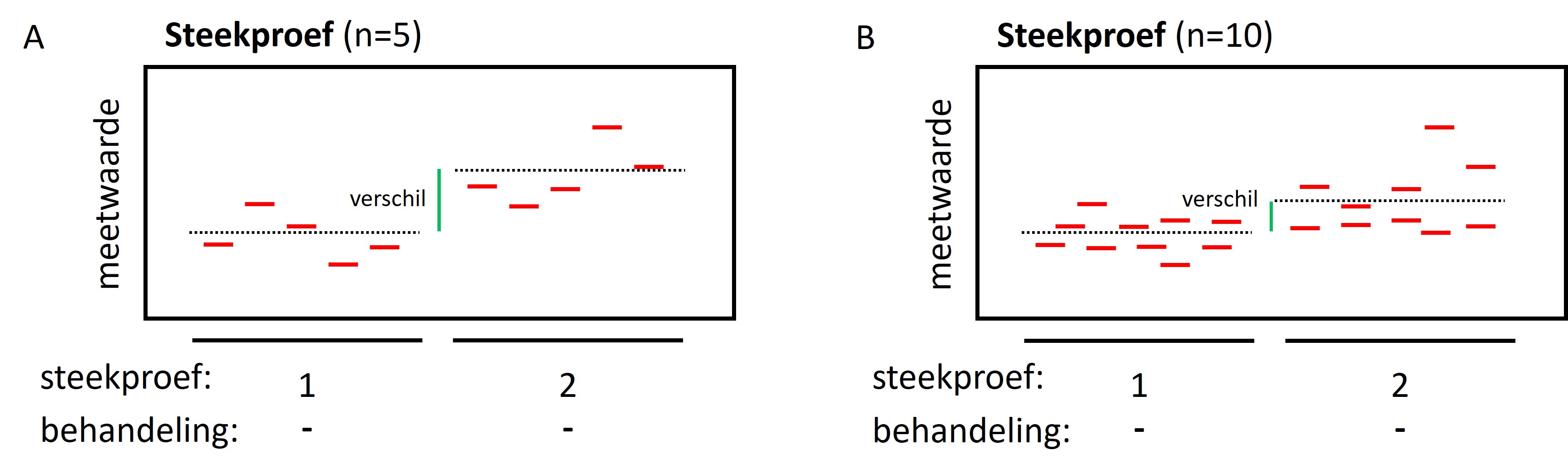
Figure 7: Een grote steekproef is meer representatief voor de populatie en geeft minder variatie
Van te voren willen we graag weten hoe groot het verschil kan zijn tussen twee steekproeven uit dezelfde populatie voorafgaand aan het experiment. Dit is de experimentele ruis van het experiment. Het is dus mogelijk, puur gebaseerd op toeval, dat twee steekproeven uit dezelfde populatie al een groot verschil laten zien in de gemiddelde meetwaarden voorafgaand aan de experimentele behandeling. Als de behandeling dan niet werkt, meet je toch een verschil (per toeval) en kan je onterecht concluderen dat de behandeling wel heeft gewerkt. Andersom beredeneert kan je ook concluderen dat een behandeling niet heeft gewerkt terwijl in werkelijkheid de behandeling wel een effect heeft gehad. In de meeste gevallen is het toevallige verschil tussen twee steekproeven niet zo groot en wordt de kans op grotere verschillen steeds kleiner. Hoe groot het toevallige verschil is tussen de gemiddelden van twee steekproeven uit dezelfde populatie wordt uitgedrukt met de SEM:
\[SEM=\frac{s}{\sqrt{n}}\] De SEM is afhankelijk van de grootte van de steekproef (=n) en de standaarddeviatie van de steekproef (=s). De standaarddeviatie van de steekproef hangt weer af van de standaardeviatie van de populatie, grootte van de steekproef en hoe de proefobjecten zijn verdeeld over de groepen. Uit de formule kunnen we afleiden dat een grote steekproef in combinatie met een kleine standaardeviatie leidt tot een kleine SEM. Dit betekent dat het gemiddelde van twee steekproeven uit dezelfde populatie een klein onderling verschil hebben (kleine ruis). De SEM is dus een maat voor de achtergrondruis van het experiment.
Het verschil dat gemeten wordt tussen de experimentele groepen na de experimentele behandeling bestaat uit ruis wat voorafgaand aan het experiment al aanwezig was tussen de steekproeven (groene gedeelte van de verticale lijn) en een (eventueel) effect van de behandeling (geel gedeelte van de verticale lijn)( zie figuur 8, rechter panel).
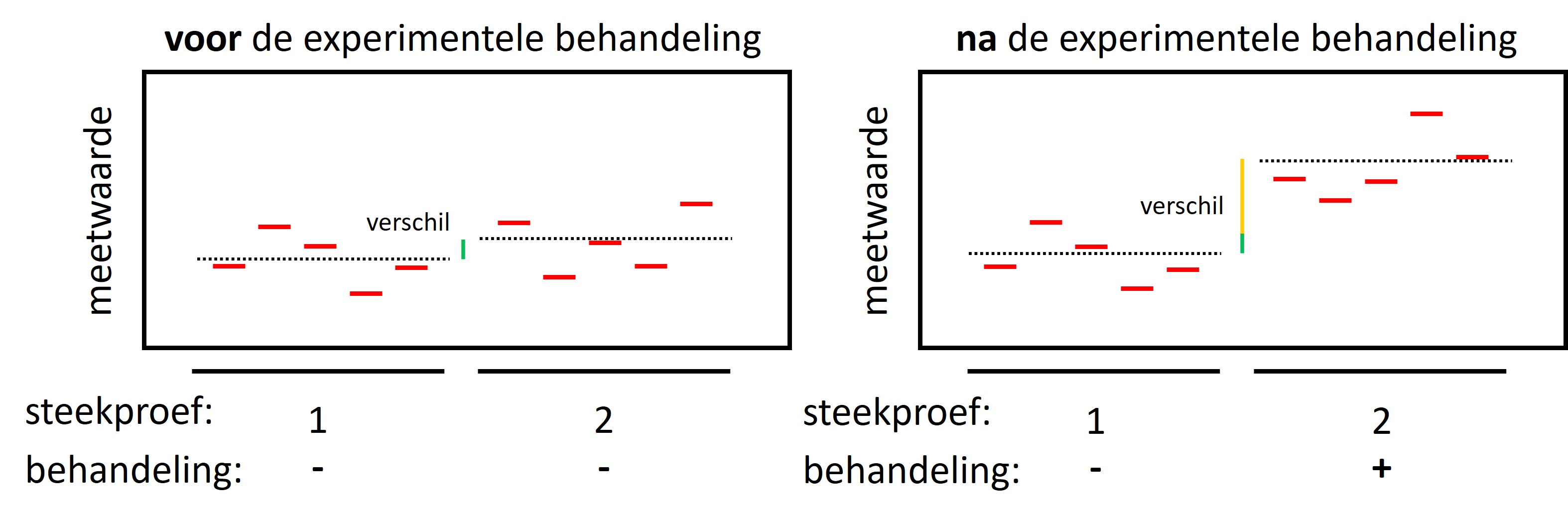
Figure 8: In een experiment is altijd natuurlijke variatie aanwezig in en tussen de groepen voorafgaand aan het experiment (linker figuur, n=5, de stippellijn geeft het gemiddelde weer). Een verschil tussen de experimentele groepen na de behandeling wordt veroorzaakt door de natuurlijke variatie (groene gedeelte van de verticale lijn) + het eventuele effect van de behandeling (gele gedeelte van de verticale lijn)
Als een experimentele behandeling geen / nauwelijks effect heeft gehad zal je altijd iets van een verschil meten tussen de experimentele groepen afkomstig van de ruis. Als deze ruis groot is kan je tot de verkeerde conclusie komen dat er wel een effect is van de experimentele behandeling terwijl in werkelijk de experimentele behandeling geen of nauwelijks een effect heeft gehad (zie figuur 9).
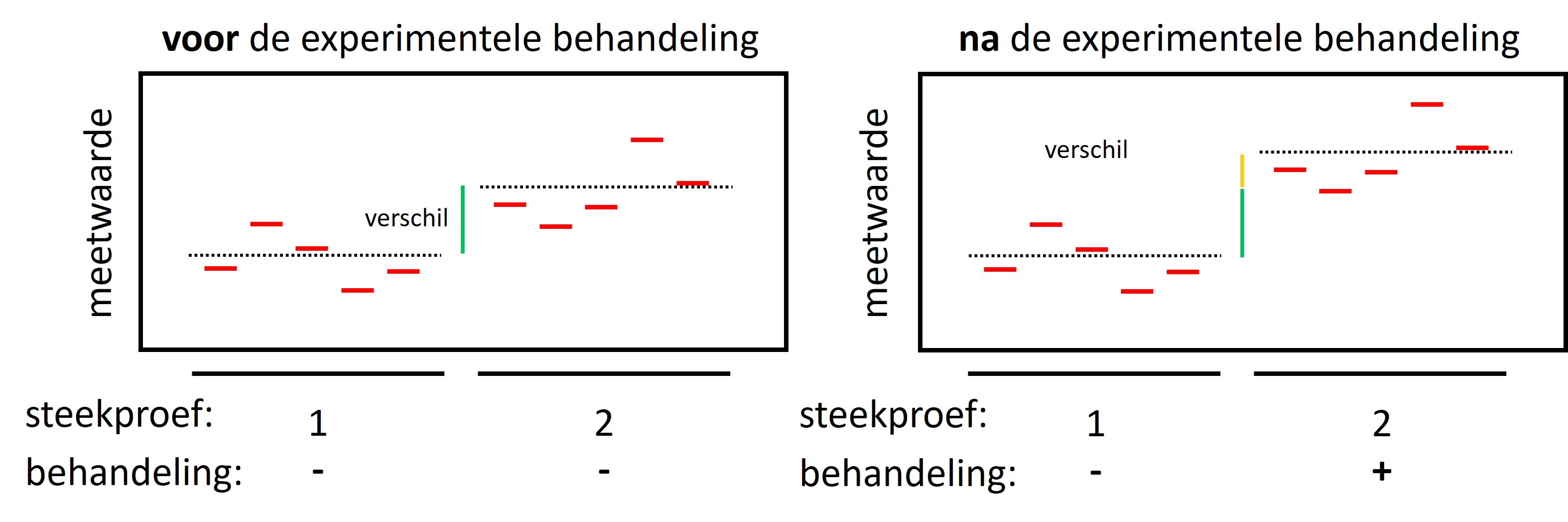
Figure 9: Experiment met veel ruis voorafgaand aan de experimentele behandeling. Er is wel een effect van de experimentele behandeling maar dit kan niet statistisch aangetoond worden door de kleine effect:ruis verhouding
In figuur 9 is voorafgaand aan de experimentele behandeling de natuurlijke variatie groot tussen de groepen. Bijvoorbeeld omdat de steekproef (te) klein is. De experimentele behandeling heeft een klein effect (figuur 9, rechter panel, gele gedeelte van de verticale lijn). Het effect is echter klein ten opzichte van de achtergrondruis en kan daardoor niet statistisch aangetoond worden.
Een andere bron van achtergrondruis is als de proefobjecten niet random worden verdeeld (bijvoorbeeld een ongelijke verdeling in gender, leeftijd of gewicht) tussen de experimentele groepen of als de groepen niet dezelfde hoeveelheid proefobjecten hebben (ongebalanceerde proefopzet). Dit vergroot de standaarddeviatie in de steekproef met als gevolg een grotere achtergrondruis in het experiment (en dus ook een grotere SEM).
les1_opdracht
- Een steekproef van 25 deelnemers geeft een gemiddelde van 70 en een standaard deviatie van 10. Wat is de SEM?
B Je verzamelt data van twee steekproeven:
Groep A: n = 100, SD = 20 Groep B: n = 25, SD = 20
Welke groep heeft de kleinste SEM?
Klik voor het antwoord
A
\[SEM=\frac{s}{\sqrt{n}}=\frac{10}{\sqrt{25}}=2\] B Groep A: populatie is groter (n=100) in vergelijking met n=25
Technische variatie
Het verschil tussen twee steekproeven na de behandeling hangt niet alleen af van de natuurlijke variatie + het eventuele effect van de behandeling maar ook van technische variatie: variatie die afkomstig is door de uitvoering van het experiment (zie figuur 10, rechter panel). Proefobjecten worden niet op precies dezelfde manier opgewerkt in de uitvoering van het protocol. Bijvoorbeeld, de experimentele groepen zijn opgewerkt op verschillende dagen, met verschillende “batches” reagentia, door verschillende analisten of meetinstrumenten.
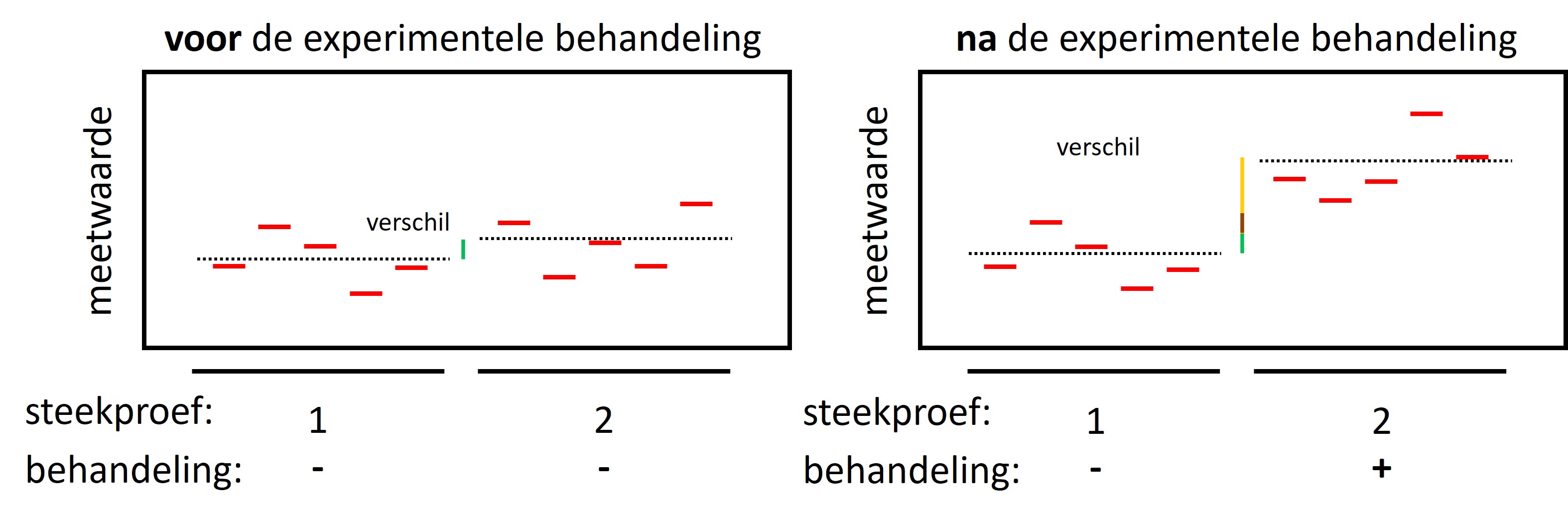
Figure 10: In een experiment is altijd natuurlijke variatie aanwezig in en tussen de groepen voorafgaand aan het experiment (linker figuur, n=5, de stippellijn geeft het gemiddelde weer). Een verschil tussen de experimentele groepen na de behandeling wordt veroorzaakt door de natuurlijke variatie (groene gedeelte van de verticale lijn) + technische variatie (bruine gedeelte van de verticale lijn) + het eventuele effect van de behandeling (gele gedeelte van de verticale lijn)
Het is belangrijk om alle monsters uit de steekproeven op dezelfde manier op te werken, bijvoorbeeld door dezelfde analist, op dezelfde dag met dezelfde reagentie en gemeten door hetzelfde meetinstrument (wat goed gekalibreerd is). Als een protocol slecht uitgevoerd wordt is de technische variatie groot. Na de behandeling wordt er een verschil gemeten tussen de experimentele groepen. In werkelijkheid is er geen effect van de experimentele behandeling en kan dit verschil verklaard worden door de technische variatie (figuur 11, rechter panel, bruine gedeelte van de verticale lijn).
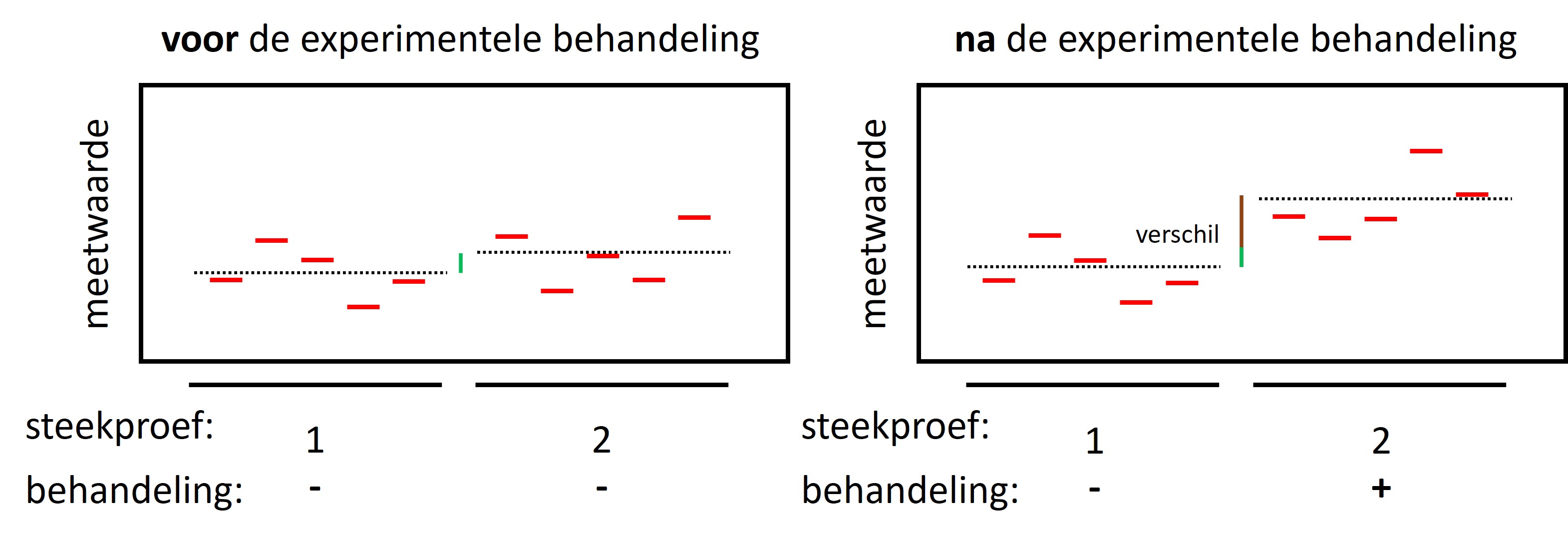
Figure 11: Er is een verschil na de experimentele behandeling tussen de experimentele groepen, maar dit verschil kan verklaard worden door de technische variatie
Effect:ruis verhouding
Om het effect van een experimentele behandeling statistisch significant aan te tonen wordt er een effect:ruis verhouding berekend (de precieze berekening verschilt per statistische toets, maar het principe blijft hetzelfde).
Het effect is het (gemiddelde) verschil dat gemeten wordt tussen de experimentele groepen na de behandeling. Dit verschil bestaat dus uit de natuurlijke en technische ruis en het eventuele effect van de experimentele behandeling.
De ruis is het verschil tussen de experimentele groepen voorafgaand aan het experiment. Om de ruis te meten wordt van iedere steekproef de Standard Error of the Mean (SEM) gemeten.
In een goed experimentele ontwerp en uitvoering wordt de ruis tot een minimum beperkt zodat verschillen tussen de experimentele groepen statistisch aangetoond kunnen worden en specifiek toegeschreven kunnen worden aan de experimentele behandeling. Met een goed ontwerp vergroot je de gevoeligheid om effecten van de experimentele behandeling aan te tonen. Je kan het vergelijken met de ruis op de radio. Als er veel ruis is, kost het veel moeite of het echte signaal (effect) te horen.
Het doel van een goede experimentele opzet is om de natuurlijke en technische variatie (ruis) zo klein mogelijk te maken zodat de effect:ruis verhouding groot wordt. Op deze manier kunnen effecten van de experimentele behandeling (indien aanwezig) statistisch aangetoond worden en specifiek toegeschreven worden aan de experimentele behandeling.
Reductie van de achtergrondruis
Hoe zorgen we ervoor dat de natuurlijke en technische variatie zo klein mogelijk wordt in een experimentele opzet?
natuurlijke variatie
We willen de SEM zo klein mogelijk hebben, zodat twee steekproeven uit dezelfde populatie min of meer hetzelfde zijn voorafgaand aan het experiment. Om de SEM zo klein mogelijk te houden in een experiment kunnen we gebruik maken van:
een grote steekproef: Maar welke grootte is goed genoeg? Hoe groter de steekproef, hoe kleiner de ruis in een experiment. De grootte van een steekproef kunnen we uitrekenen met behulp van Power Analyse en is afhankelijk van de variatie in de populatie, het te verwachtte effect van de experimentele behandeling en of de metingen gepaard of ongepaard zijn (dit wordt verder in detail uitgelegd in de les3 over Power Analyse).
een homogene populatie: een homogene populatie heeft een kleine standaarddeviatie wat leidt tot een kleine standaarddeviatie in de steekproef.
Een voorbeeld hiervan is het gebruik van genetisch zeer verwante muizenstammen of andere modelorganismen zoals rondwormen of fruitvliegen. Cellijnen zijn ook genetisch hetzelfde en dus homogeen. Het nadeel is dat de gevonden data niet representatief hoeven te zijn voor andere (muizen)stammen en of (primaire) cellijnen.
technische variatie
De variatie in de meetwaarden (na de behandeling) wordt niet alleen veroorzaakt door de natuurlijke variatie van de populatie maar ook door technische variatie. Hieronder enkele aanbevelingen om de technische variatie te verminderen:
- uitvoering van het protocol
- lees het protocol goed door en begrijp wat je moet doen
- maak pipeteerschema’s
- werk nauwkeurig en veilig
- bereid je goed voor en zorg dat alles klaar staat
- verwerk alle monsters op dezelfde dag
- noteer alles in je labjournaal
- lees het protocol goed door en begrijp wat je moet doen
- gebruikte reagentia
- werk met “verse” reagentia
- indien mogelijk verwerk alle monsters met dezelfde reagentie
- controleer of alles en in voldoende mate aanwezig is voor de uitvoering van het experiment - meetapparatuur
- gebruik hetzelfde meetinstrument voor alle monsters
- begrijp hoe het meetinstrument werkt:
- hoe werkt de software?
- hoe wordt het apparaat bediend. Wat zijn de verschillende opties?
- zijn er technische beperkingen?
- hoeveel monsters kan ik per keer meten?
- moet het apparaat gewassen worden voor en na gebruik?
- hoe werkt de software?
- werk met “verse” reagentia
- kalibreer het meetinstrument
Technische variatie kan gemeten worden door technische replicaties. Hetzelfde monster wordt gesplitst en onafhankelijk op dezelfde manier behandeld en gemeten. Na elke stap in het protocol kan een monster gesplitst worden zodat bij iedere stap de technische variatie gemeten kan worden. Het is belangrijk om van te voren na te denken waar deze technische variatie vandaan kan komen zodat in de uitvoering van het experiment, de technische variatie tot een minimum beperkt kan worden.
LET OP: Het is belangrijk om te weten dat de meetwaarden van een technische replicatie dus niets zeggen over over de biologische variatie van een experiment! De biologische variatie in een experiment wordt gemeten met biologische replicaties ( = de grootte van de steekproef)
samenstellen van de steekproeven
- randomizatie: de proefobjecten worden random verdeeld over de experimentele groepen zodat alle variatie tussen de proefobjecten gelijk verdeeld wordt over de experimentele groepen.
Bijvoorbeeld, als gender niet gelijk verdeeld is over de experimentele groepen kan een mogelijk verschil tussen de experimentele groepen verklaard worden door de behandeling maar ook door het verschil in gender. Op deze manier kan je tot de verkeerde conclusie komen dat een behandeling wel werkt maar in werkelijk wordt het verschil verklaard door de ongelijke verdeling van gender tussen de experimentele groepen.
- gebalanceerde experimentele groepen: elke experimentele groep heeft evenveel proefobjecten. Dit vergroot de statistische gevoeligheid om effecten van een experimentele behandeling aan te tonen. Als groepen niet in balans zijn moet de statistische test worden aangepast en wordt de test minder gevoelig om effecten aan te tonen
Gepaarde en ongepaarde proefopzet
In beschrijving van OFAT experimenten hebben we tot nu toe steeds (minimaal) twee verschillende steekproeven gebruikt waarbij de ene groep dient als controle groep (geen behandeling) en de andere groep(en) de behandeling krijgen. Dit is een ongepaarde proefopzet. Het is ook mogelijk om maar één experimentele groep te gebruiken om een een experiment uit te voeren. In dat geval spreek men van een gepaarde proefopzet. De voor- en nadelen worden hieronder verder toegelicht.
Gepaarde proefopzet:
Er is maar één experimentele groep en ieder “proefobject” wordt twee of meerdere keren gemeten: voor de behandeling en na de behandeling (zie figuur 12). Een groot voordeel van deze proefopzet is dat er geen onderlinge verschillen zijn tussen de groepen. Ieder proefobject is namelijk een controle van zichzelf omdat voor ieder proefobject het verschil wordt uitgerekend tussen de voor en de na meting.
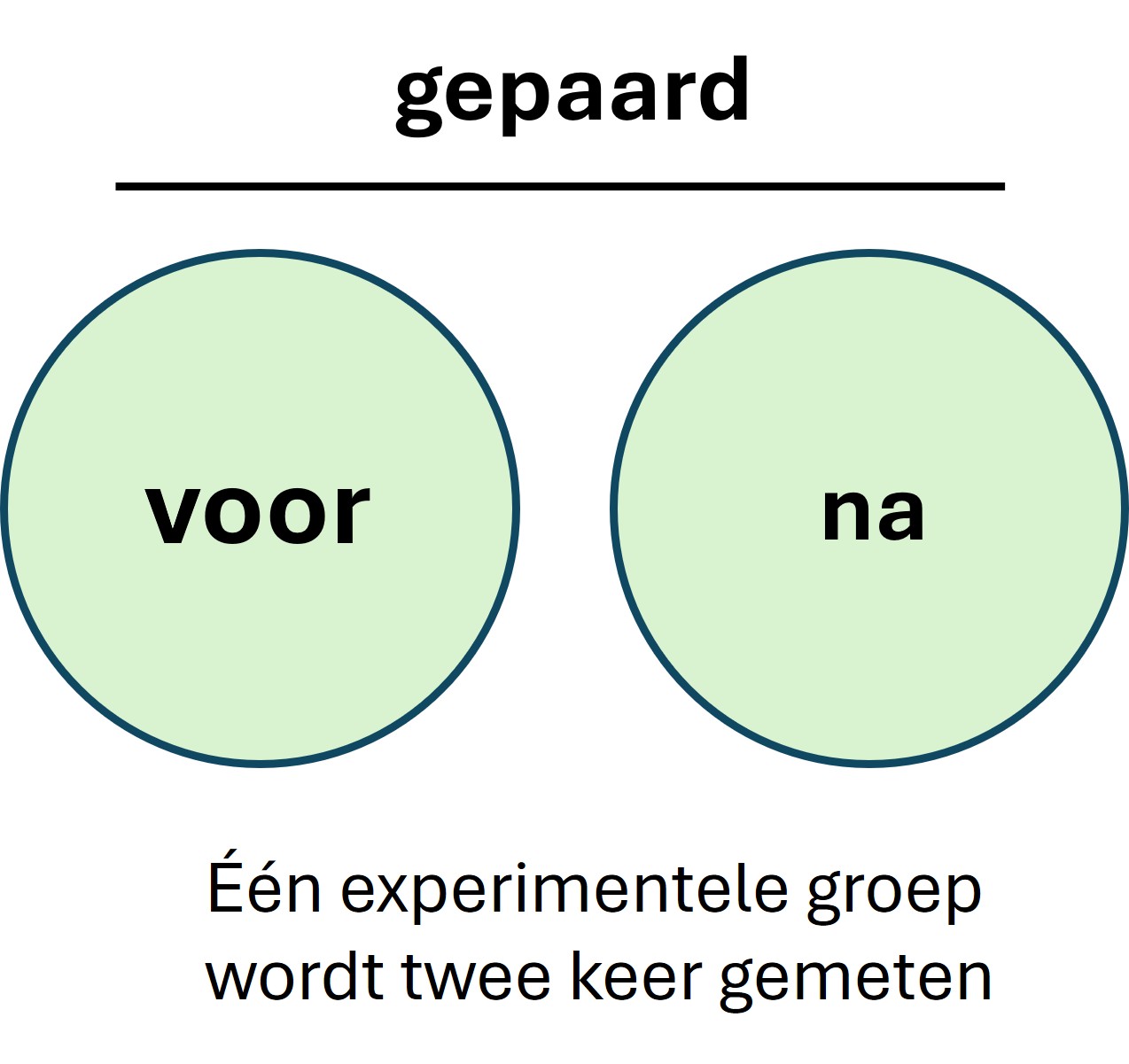
Figure 12: gepaarde experimentele proefopzet. De proefobjecten worden ieder twee keer gemeten
Potentiële problemen bij gepaarde experimenten zijn de mogelijke aanwezigheid van volgorde effecten of een gebrek aan omkeerbaarheid (=reversibiliteit). In de tijd tussen de metingen kunnen de proefobjecten een verandering ondergaan zodat het niet meer dezelfde meting heeft als de begin meting. Bijvoorbeeld, men meet eerst het weefsel zonder behandeling. Vervolgens past men de behandeling toe. Maar in de tijd van de behandeling gaat de kwaliteit van het weefsel ook achteruit. Er zijn nu twee variabelen geïntroduceerd. De behandeling en de achteruitgang van de kwaliteit van het weefsel. Beide variabelen beïnvloeden de meting. Als de kwaliteit van de stukjes weefsel in de loop van de tijd afneemt dan is het onverstandig om altijd dezelfde volgorde van behandeling toe te passen. De procedure kan voor een deel van de proefobjecten ook omgedraaid worden. Eerst beginnen met de behandeling en vervolgens wachten tot de behandeling is uitgewerkt. Als de behandeling is uitgewerkt kan je de “voor” meting doen. De voorwaarde is wel dat de behandeling omkeerbaar is en de proefobjecten geen blijvende schade ondervinden.
Een gepaarde proefopzet kan niet worden gebruikt indien de meting destructief is. Dat wil zeggen dat de proefobjecten worden opgeofferd of als de behandeling niet omkeerbaar is. In dat geval maak je gebruik van een ongepaarde proefopzet.
Ongepaarde proefopzet:
Er zijn (minimaal) twee experimentele groepen en ieder “proefobject” in de groep wordt maar één keer gemeten (zie figuur 13).
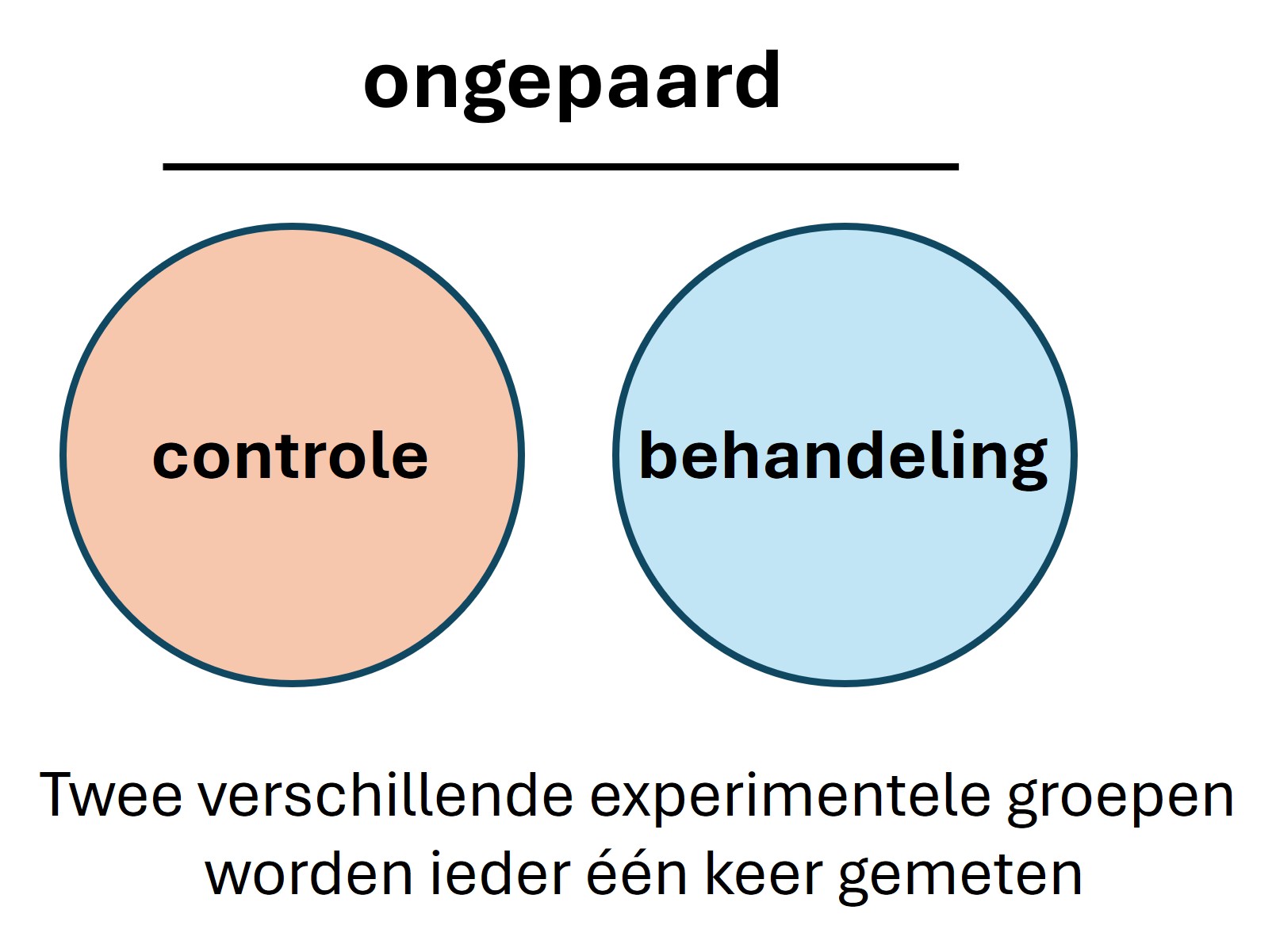
Figure 13: ongepaarde experimentele proefopzet. De proefpersonen worden verdeeld over (minimaal) twee groepen en iedere proefpersoon wordt één keer gemeten
Het voordeel van een ongepaarde meting is dat metingen waarbij proefobjecten worden opgeofferd mogelijk zijn. Een nadeel is de eerder genoemde variatie tussen de proefobjecten zodat er altijd al een verschil is tussen de experimentele groepen voorafgaand aan het experiment. Bijvoorbeeld, als onderzoek wordt gedaan aan humaan hersenweefsel van epilepsie patiënten, is men afhankelijk van donorweefsel dat is weggehaald bij patiënten. De aanvoer en kwaliteit van het weefsel zal niet constant zijn en er is dus grote variatie tussen de meetobjecten (leeftijd, geslacht, genetische achtergrond van de donoren, mate van epilepsie). Als het doel van een onderzoek is om te kijken wat het effect is van een hormoon op de neurale signaaltransductie, kan men een ongepaarde test doen en de weefsels verdelen over een controle groep (zonder hormoon) en een behandelde groep (met hormoon). In deze proefopzet is de kans groot dat de meetresultaten een te grote variatie vertonen om een effect aan te tonen (zie figuur 14, linker panel). Er zijn dan heel veel weefsels nodig om een bepaald effect aan te tonen.
Indien mogelijk, is het beter om voor een gepaarde proefopzet te kiezen. Ieder stukje weefsel kan gesplitst en behandeld worden met en zonder hormoon. Het voordeel van een gepaarde proefopzet is dat elke gepaarde meting dezelfde achtergrond heeft en dit verminderd de natuurlijke variatie. Bij een gepaarde meting is het dus eenvoudiger om een effect aan te tonen omdat ieder proefobject een controle van zichzelf is. Als voor ieder stukje weefsel de signaaltransductie toeneemt dan is er een effect van de hormoonbehandeling, ondanks dat de absolute waarden per weefsel sterk verschillen (zie figuur 14, rechter panel).
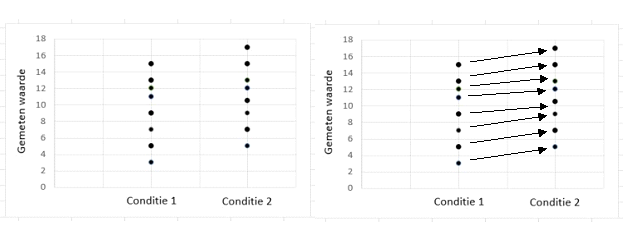
Figure 14: Ongepaard en gepaard experiment. In de linker grafiek staan resultaten van een ongepaard experiment. Er zijn twee gerandomiseerde groepen van 8 weefsels gemeten, ieder punt is een meting. Er lijkt een verschil te zijn tussen de twee condities, maar de grote variatie in de experimentele groepen maakt dat er geen significant verschil wordt gevonden. In de rechter grafiek zijn de resultaten van een gepaard ontwerp te zien, waarbij ieder weefsel zowel bij conditie 1 als conditie 2 is getest. De pijlen laten zien welke voor en na meetpunten van hetzelfde weefsel zijn. Door acht keer het verschil per weefsel te meten is er wel een significant verschil tussen de condities te meten. Gepaarde metingen kunnen alleen uitgevoerd worden als de meting niet destructief is
Statistiek voor OFAT experimenten
Data van OFAT experimenten worden gevisualiseerd door middel van
- Boxplots (spreiding van de datapunten per experimentele groep)
- Staafdiagram (gemiddelde per groep + standaarddeviatie)
- Lijngrafiek (als een factor meerdere levels heeft zoals een concentratie- of tijdreeks)
De statistische toetsen die gebruikt voor de analyse van OFAT experimenten zijn:
- Unpaired two sample T-test
- Paired two sample T-test
- Unpaired ANOVA
- Paired ANOVA
Om deze toetsen uit te voeren (in R) moet de data wel aan een aantal voorwaarden voldoen. Dit wordt verder besproken in de statistiek lessen 5 t/m 8
Casus
Deel 1:
In het volgende artikel van liu-et-al-2020 wordt onderzocht of er een verschil is in de expressie van de genen sel-12 en hop-1 in rondwormen die blootgesteld zijn aan nanoplastics.
Bestudeer de Materiaal en Methode:
- sectie 4.1, 4.2, 4.3, 4.9, 4.10
- Table 2. Primer Sequences for RT-qPCR
- Figuur 4A
Beantwoord de volgende vragen over het experimentele ontwerp:
- Onafhankelijke variabele:
- Welke factor wordt er getest?
- Wat zijn de levels van de factor?
- Controles
- Wat is er toegevoegd aan de negatieve controle?
- Wat is de loading controle (normalizatie controle) voor de qPCR?
- Modelsysteem
- Welke C.elegans stam is er gebruikt voor de qPCR analyse?
- In welke ontwikkelingsfase is de C elegans?
- Hoeveel metingen per experimentele groep?
- Afhankelijke variabele
- Zijn de primers (Table 2. Primer Sequences for RT-qPCR) specifiek voor de sel-12 en hop-1 genen?
HINT: gebruik de UCSC browser -> Tools -> In-Silico PCR. Noteer ook voor ieder gen in welke exonen de forward en reverse primer liggen
- Zoek (summary) informatie op over de sel-12 en hop-1 genen:
- Wat is de functie van deze genen in C. elegans
- In welk proces spelen deze genen een rol? (Gebruik de NCBI / Uniprot databanken)
- Wat is de humane ortholog van de sel-12 en hop-1 genen
- Hoeveel overeenkomst vertoont het CDS van de humane ortholog met de sel-12 en hop-1 genen. Gebruik NCBI BLAST global align
- Hoe wordt er gemeten: gepaard of ongepaard?
- Welke statistische test wordt er gebruikt om de data te analyseren
Deel 2
Een andere onderzoeker wil het experiment herhalen met een andere set primers voor sel-12 en hop-1
- De onderzoeker verkrijgt de volgende resulaten:
| gen | level | gemiddelde | stdev |
|---|---|---|---|
| control | 10 µg/ml | 1.0 | 0.23 |
| control | 100 µg/ml | 1.0 | 0.13 |
| sel-12 | 10 µg/ml | 1.2 | 0.11 |
| sel-12 | 100 µg/ml | 1.1 | 0.13 |
| hop-1 | 10 µg/ml | 1.3 | 0.23 |
| hop-1 | 100 µg/ml | 1.1 | 0.11 |
- Maak voor ieder gen een staafdiagram + standaarddeviatie in R
- Interpreteer de resultaten en vergelijk met figuur 4A. Wat is je conclusie?
- Welke positieve controle kan de onderzoeker mee nemen om tot een betere conclusie te komen?