Les7 - Parametrische testen(1)
Leerdoelen
Uitvoeren van parametrische toetsen:
- Ongepaarde t-test
- Gepaarde t-test
Inductieve statistiek
Om een parametrische test te doen moet de experimentele opzet en de data aan een aantal voorwaarden voldoen:
- Je wilt een verschil aantonen tussen de controle groep en experimentele groep(en) (een vergelijkende onderzoeksvraag)
- De meetwaarden zijn kwantitatief
- Geen uitbijters in de dataset
- De data is normaal verdeeld
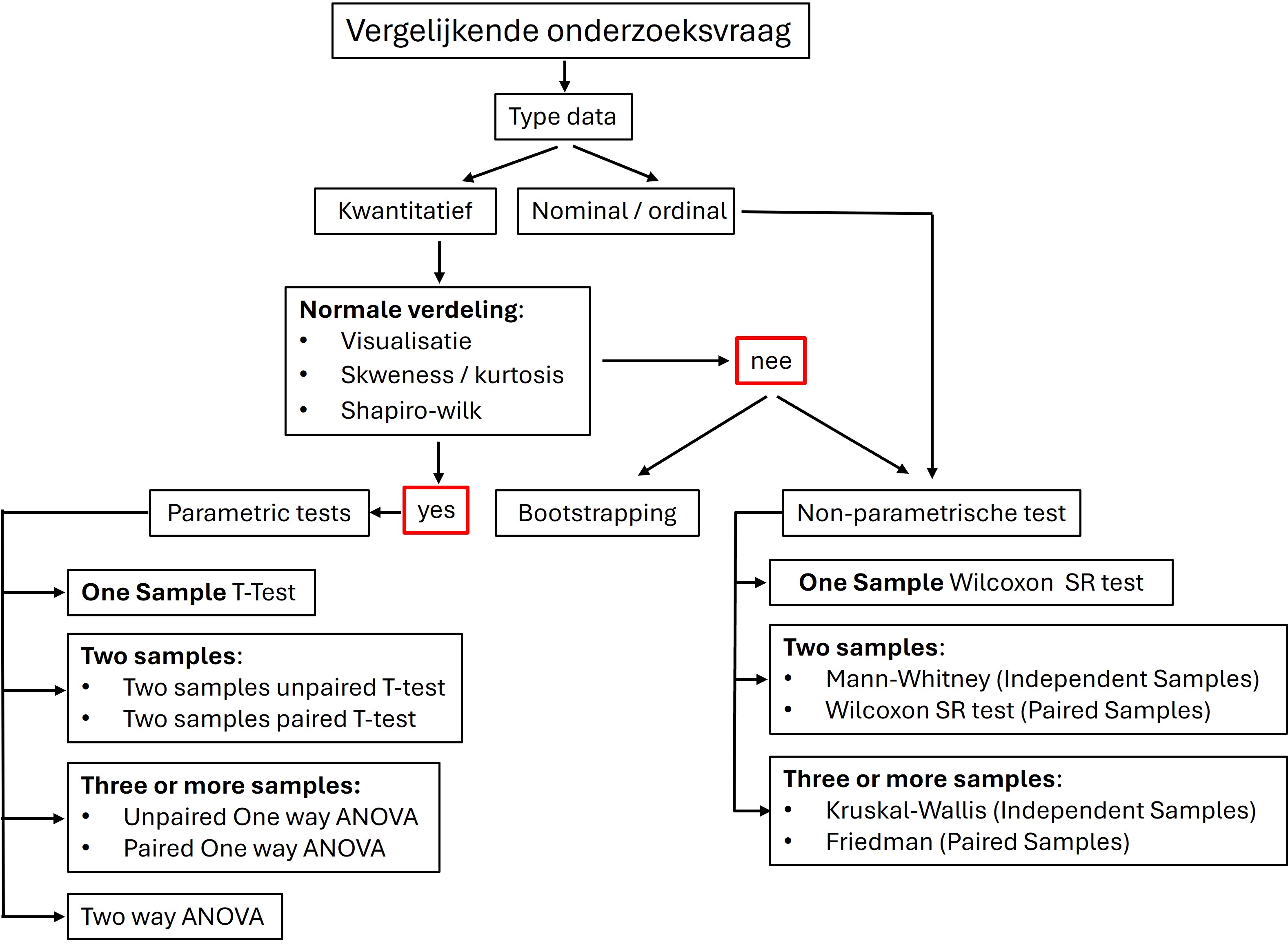
Figure 58: Beslissingsboom statistische testen
Als er voldaan is aan deze voorwaarden (zie ook les5) kan je een parametrische toets uitvoeren. Met behulp van de gemiddelden van de steekproeven wil je een uitspraak doen over de populaties: is er een verschil in wat je hebt gemeten tussen de controle populatie met de populatie die de experimentele behandeling heeft ondergaan.
Het principe van een parametrische test is dat als er geen verschil is tussen de controle groep en de behandelde groep de steekproeven allebei min of meer hetzelfde gemiddelde hebben en dat dus het verschil tussen de steekproeven ongeveer 0 zal zijn. Dit verschil wordt het signaal genoemd en wordt vervolgens gedeeld door de ruis van het experiment. Het is dus zeer belangrijk (zoals beschreven in les1) om de ruis te minimaliseren zodat de signaal-ruis verhouding toeneemt en het gemeten verschil tussen de controle groep en de behandelde groep niet berust op toeval maar verklaard kan worden door de experimentele behandeling.
Two Samples unpaired T-test
Gebruik de “Two Samples unpaired T-test” bij een ongepaard OFAT experiment waarbij er twee onafhankelijke groepen zijn die ieder één keer zijn gemeten:
De t-test statistiek van een “Two Samples unpaired T-test” is:
\[ t = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}} \]
Vanuit deze formule kunnen we zien dat we eerst het signaal uitrekenen in de teller en dit signaal is het verschil tussen de steekproefgemiddelden van de controle groep en de behandelde groep. Dit signaal wordt gedeeld door de achtergrondruis van het experiment en de ruis wordt gedefiniëerd door de gecombineerde SEM van de steekproeven. Deze waarde is de t-statistiek. Vervolgens wordt m.b.v. de t-verdeling uitgerekend wat de kans is om dit verschil te meten onder de aanname dat de behandeling niet heeft gewerkt. Met andere woorden wat is de kans dat dit verschil op toeval berust. Dit wordt formeel vastgelegd met de nul-hypothese (H0):
H0: \(\mu1\) = \(\mu2\)
H1: \(\mu1\) ≠ \(\mu2\)
Intiutief voel je aan dat de kans steeds kleiner wordt om per toeval grote verschillen te meten tussen twee steekproeven uit dezelfde beginpopulatie. Als deze kans (p-waarde) kleiner is dan 0,05 dan verwerpen we de H0 en wordt de H1 geaccepteerd. Er is wel een verschil tussen het gemiddelde van de controle steekproef en het gemiddelde van de behandelde steekproef. Dit verschil berust niet op toeval.
P-waarde van de t-test ≥ 0,05: accepteer H0. Er is geen statistisch significant verschil tussen de populaties P-waarde van de t-test < 0,05: verwerp H0 en accepteer H1. Er is wel statistisch significant verschil tussen de populaties.
Als we een significantie niveau hanteren van 0,05 dan nemen we een risico van 5% (1 op de 20 gelijke experimenten) dat we een statististisch significant effect waarnemen, maar in werkelijkheid berust het verschil op toeval. Dit is een type I fout. We concluderen dat er een statistisch significant verschil is tussen de controle groep en de behandelde groep, maar in werkelijkheid berust dit verschil dus op toeval.
Het is belangrijk om te vermelden dat er hier tweezijdig getoetst wordt. Bij een tweezijdige toets wil je alleen weten of er een verschil is en niet in welke richting het verschil gaat. We houden beide opties open: het verschil wordt veroorzaakt door een grotere gemiddelde waarde van de controle groep t.o.v. de behandelde groep of andersom. Een eenzijdige toets is geschikt als je een specifieke richting verwacht voor het verschil. Bijvoorbeeld, de gemiddelde waarde van de behandelde groep is groter dan de gemiddelde waarde van de controle groep. Voor een eenzijdige toets hoeft het verschil minder groot te zijn om statistisch significant te zijn. Daarom zienm we vaak dat er eenzijdig getoets wordt in wetenschappelijke publicaties. Als dit niet onderbouwt kan worden mag je niet zomaar eenzijdig toetsen. Bij twijfel test je altijd tweezijdig!!
LET OP: Voordat een “Two Samples unpaired T-test” uitgevoerd kan worden moet er eerst bepaald worden of de variances gelijk zijn. Dit wordt getest met de Levene’s test.
De functie leveneTest() is onderdeel van de “car” package
install.packages("car")
library(car)De leveneTest() berekent een p-waarde. Met behulp van deze p-waarde wordt de nulhypothese (H0) geaccepteerd of verworpen. Als de H0 wordt verworpen, wordt de alternatieve hypothese (H1) geaccepteerd.
H0: De varianties van de experimentele groepen zijn gelijk
H1: De varianties van de experimentele groepen zijn niet gelijk
P-waarde van de leveneTest() ≥ 0.05: H0 wordt geaccepteerd. De varianties zijn gelijk.
P-waarde van de leveneTest() < 0.05: H0 wordt verworpen en de H1 wordt geaccepteerd. De varianties zijn niet gelijk.
Voor het uitvoeren van LeveneTest() is het aan te raden om de data-kolom waar de experimentele groepen zijn definiëerd om te zetten naar een factor met behulp van de as.factor() functie. De leveneTest() functie verwacht dat de kolom die de groepen weergeeft expliciet is aangegeven als een factor variabele.
R code om de Levene’s test uit te voeren:
# De data is het percentage oppervlakte wat dicht is gegroeid na een scratch assay
# data koppelen aan een variabele
les7_scratch <- tibble(controle=c(10,10,10,9,15,9,10,8,7,10,11,13,10,11,9),
behandeld=c(12,14,16,10,11,17,13,13,16,16,16,12,16,16,12))
# Tidyverse maken van de data
les7_scratch_tidy <-les7_scratch |>
pivot_longer(cols=c("controle", "behandeld"),
names_to="groep",
values_to="area_perc")
# de kolom 'groep' omzetten naar een factor variabele
les7_scratch_tidy$groep <-as.factor(les7_scratch_tidy$groep)
# Test of de variances gelijk zijn met de Levene test
leveneTest(data=les7_scratch_tidy, # data bestand waarop de Levene test moet worden uitgevoerd
area_perc~groep) # formule die de afhankelijke variabele (links) en de onafhankelijke variabele (rechts) aangeeftDe output van leveneTest() ziet er als volgt uit:
Levene’s Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 3.1698 0.08587 .
28
—
Signif. codes: 0 ’’ 0.001 ’’ 0.01 ’’ 0.05 ‘.’ 0.1 ‘ ’ 1
De p-waarde staat aangegeven onder Pr(>F) en is 0.08587. Dat is groter dan 0,05. De H0 wordt geaccepteerd en de varianties zijn gelijk.
Met behulp van de uitkomst van de Levene’s test kunnen we nu aangeven dat de varianties gelijk zijn in de t.test() functie.
Als de p-waarde van de Levene’s test < 0,05 dan wordt de Welch t-test uitgevoerd die rekening houdt met de ongelijke varianties. Dit is een variant van de t-test. De p-waarde wordt groter en is dus conservatiever.
De t.test() functie test standaard met tweezijdig, ongepaard, gelijke varianties en een 95% BI (zie opties hieronder). Pas deze opties aan als ze afwijken van de standaard instellingen.
t.test(data, # data bestand waarop de t.test moet worden uitgevoerd
formula, # formule die de afhankelijke variabele (links) en de onafhankelijke variabele (rechts) aangeeft
alternative="two.sided",
paired=FALSE,
var.equal=FALSE, # Als de varianties niet gelijk zijn dan wordt de Welch test uitgevoerd, een variant van de T-test
conf.level=0.95)We gaan verder met object ‘les7_scratch_tidy’ om de t.test() uit te voeren.
R code om een ongepaarde t-test uit te voeren met tidy data:
# Uitvoeren van de ttest
t.test(data=les7_scratch_tidy, # data bestand waarop de t.test moet worden uitgevoerd
area_perc~groep, # afhankelijke variabele ~ onafhankelijke variabele
var.equal = TRUE) # Geef aan dat de varianties gelijk zijn na uitvoering van de LevenetestDe output van de ongepaarde t-test ziet er als volgt uit:
Two Sample t-test
data: area_perc by groep
t = 5.0374, df = 28, p-value = 2.504e-05
alternative hypothesis: true difference in means between group behandeld and group controle is not equal to 0
95 percent confidence interval:
2.294314 5.439019
sample estimates:
mean in group behandeld mean in group controle
14.00000 10.13333
De p-waarde = 2.504e-05 en dat is kleiner dan 0,05. De H0 wordt verworpen en de H1 wordt geaccepteerd. Er is wel een statistisch significant verschil tussen de controle groep en de behandelde groep.
We zien ook dat het 95% BI loopt van 2.294314-5.439019 dit betekent dat het populatieverschil tussen de controle groep en de behandelde groep ergens tussen deze limieten ligt. Het 95% BI bevat geen 0 waarde wat aan zou geven dat er geen verschil is tussen de groepen.
les7_opdracht
Een oncoloog wil de grootte van colorectale kanker meten na behandeling met een nieuw biofarmaceutisch middel. De oncoloog selecteerde patiënten met een stadium I-tumor met tumorgroottes van minder dan 2 cm. De patiënten werden verdeeld in twee groepen:
groep1: controle zonder behandeling
groep2: behandeling met nieuw biofarmaceutisch middel
De data is aanwezig in bestand les7_opdracht1.txt
- Kopiëer bestand les7_opdracht1.txt vanuit de gedeelde map (/home/data/mizi3v/les7) naar de map mizi3v/data/les7 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server).
De data is normaal verdeeld en heeft geen uitbijters:
- Wat is de p-waarde van de Levene’s test? Hebben de steekproeven gelijke variantie?
- Is er een statistisch significant verschil in tumorgrootte tussen groep1 en groep2?
- Wat is je conclusie?
Klik voor het antwoord
library(tidyverse)
library(car)
# Importeer de data in R object. Let op het decimaal teken!!
# De data is al tidy!
les7_opdracht1 <- read_tsv("data/les7/les7_opdracht1.txt",
locale=locale(decimal_mark = ","))
# De kolom 'group' omzetten naar een factor variabele
les7_opdracht1$group <-as.factor(les7_opdracht1$group)
# Test of the varianties gelijk zijn met de levene's test
leveneTest(data=les7_opdracht1,
size_cm~group)
# P-waarde van de leveneTest = 0.05973. De p-waarde > 0,05. De varianties zijn gelijk
# test of er een verschil is tussen de groepen met een t-test.
# Test met gelijke varantie
t.test(data=les7_opdracht1,
size_cm ~group,
var.equal=TRUE)
# P-waarde = 0.05955. P-waarde > 0.05. Accepteer de H~0~ Er is geen verschil.les7_opdracht
Het effect van caffeïne op de hartslag (bpm) van Daphnia magna wordt getest.
groep1: controle zonder behandeling
groep2: behandeling met caffeïne
De data is aanwezig in bestand les7_opdracht2.txt
- Kopiëer bestand les7_opdracht2.txt vanuit de gedeelde map (/home/data/mizi3v/les7) naar de map mizi3v/data/les7 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server).
Bepaal of er een statistisch significant verschil is tussen de controle groep en de behandelde groep?
Wat is je conclusie?Maak een staafdiagram met errorbars.
Vergelijk de visualisatie met de uitkomst van de t.test
Wat is je conclusie?
Klik voor het antwoord
# laad de libraries
library(tidyverse)
library(ggplot2)
library(car)
# (a)
# laad de data in een R object
les7_opdracht2 <- read_tsv("data/les7/les7_opdracht2.txt")
# Bepaal het aantal metingen per groep
les7_opdracht2 |> map_dbl(length)
# Er zijn meer dan 50 metingen per experimentele groep. We hoeven dus niet te testen of de data normaal is verdeeld
# Maak de data tidy
les7_opdracht2_tidy <- les7_opdracht2 |>
pivot_longer(cols=c("controle","groep1"),
names_to="groep",
values_to="hartslag")
# de kolom 'groep' omzetten naar een factor variabele
les7_opdracht2_tidy$groep <- as.factor(les7_opdracht2_tidy$groep)
# Uitvoeren van de Levene's test
leveneTest(data=les7_opdracht2_tidy,
hartslag ~ groep)
# p-waarde van de Levene's test < 0.05. Varianties zijn niet gelijk
# Uitvoeren van de ttest
t.test(data=les7_opdracht2_tidy,
hartslag ~ groep,
var.equal=FALSE)
# P-waarde van de Welch t-test (0.002717) < 0.05. Verwerp H~0~ en accepteer H~1~.
# Er is wel een statistisch significant verschil
# (b)
# Bereken het gemiddelde en de standaard deviatie van de twee groepen
les7_opdracht2_tidy_summarise <-les7_opdracht2_tidy |>
group_by(groep) |>
summarize(hartslag_gem = mean(hartslag),
hartslag_sd = sd(hartslag))
# Maak een staafdiagram met errorbars
les7_opdracht2_tidy_summarise |>
ggplot(aes(x=groep, y=hartslag_gem))+
geom_col()+
geom_errorbar(aes(ymin=hartslag_gem-hartslag_sd,
ymax=hartslag_gem+hartslag_sd),
width=.2)+
labs(
title="effect van caffeine op de hartslag in Daphnia magnia",
x="groep",
y="hartslag (bpm)")+
theme_minimal()
# Het verschil tussen het gemiddelde van de controle groep (305) en de behandelde groep (306) is minimaal ...
# en niet biologisch relevant: toename van 1 bpm op een baseline hartslag van 305
# Omdat we met een zeer grote steekproef werken is de SEM (ruis van het experiment) extreem klein.
# Hierdoor worden kleine verschillen statistisch significant terwijl dat niet biologisch relevant is!!Two Samples paired T-test
Gebruik de “Two Samples paired T-test” bij een gepaard OFAT experiment waarbij één groep twee keer wordt gemeten
De t-test statistiek van een “Two Samples paired T-test” is:
\[ t=\frac{\bar{d}}{s_d / \sqrt{n}} \] Vanuit de formule kunnen we zien dat we eerst het signaal uitrekenen in de teller. Voor iedere gepaarde meting wordt het verschil uitgerekend en vervolgens wordt van deze verschillen het gemiddelde uitgerekend. Dit signaal wordt gedeeld door de achtergrondruis van het experiment en de ruis wordt gedefiniëerd door de SEM. In een gepaarde opzet wordt de SEM uitgerekend door eerst de standaarddeviatie te berekenen van de verschillen gedeeld door de wortel van het aantal waarnemingen. Deze waarde is de t-statistiek voor de gepaarde t-test. Vervolgens wordt m.b.v. de t-verdeling uitgerekend wat de kans is om dit verschil te meten onder de aanname dat de behandeling niet heeft gewerkt. Met andere woorden wat is de kans dat dit verschil op toeval berust. Dit wordt formeel vastgelegd met de nul-hypothese (H0):
H0: \(\mu_d\) = 0
H1: \(\mu_d\) ≠ 0
Intiutief voel je aan dat de kans steeds kleiner wordt om per toeval grote verschillen te meten tussen twee gepaarde metingen als er geen effect is van de behandeling. Als deze kans (p-waarde) kleiner is dan 0,05 dan verwerpen we de H0 en wordt de H1 geaccepteerd. Er is wel een verschil tussen de gepaarde metingen in de populatie. Dit verschil berust niet op toeval (mety een kans van 1 op 20 dat het wel op toeval berust, de type I fout).
P-waarde van de t-test ≥ 0,05: accepteer H0. Er is geen statistisch significant gemiddeld verschil tussen de gepaarde metingen.
P-waarde van de t-test < 0,05: verwerp H0 en accepteer H1. Er is wel statistisch significant gemiddeld verschil tussen de gepaarde metingen.
LET OP: Als je een t.test uitvoert met gepaarde data in R dan moeten de gepaarde metingen over twee kolommen verdeeld worden. De berekening vindt plaats over de verschillen van de gepaarde meting. Om te bepalen of de data normaal verdeeld is gebruik je ook de verschillen tussen de gepaarde metingen
LET OP: Voor een gepaarde t.test hoef je niet de Levene’s test uit te voeren. De Levene’s test geldt alleen voor onafhankelijke groepen en dat is bij een gepaarde meting niet het geval omdat de waarde van de tweede meting afhangt van de waarde van de eerste meting.
De ruis in een gepaarde proefopzet is kleiner in vergelijking met een ongepaarde proefopzet. Dat komt omdat ieder proefobject een controle van zichzelf is. Hierdoor is het makkelijker om een statistisch significant effect aan te tonen met een gepaarde proefopzet.
R code om een gepaarde t-test uit te voeren met untidy data:
# De data is de concentratie van een metaboliet (ng/ml) in de urine
# voor en na behandeling met medicijn X
# We nemen aan dat de data normaal verdeeld is
# data koppelen aan een variabele
les7_urine <- tibble(voor=c(10,8,7,9,12),
na=c(13,12,8,9,15))
# Maak een extra kolom aan met de verschillen tussen de na en de voor meting
les7_urine_verschil <- les7_urine |>
mutate(verschil=na-voor)
# Doe de gepaarde ttest waarbij het gemiddelde verschil vergeleken wordt met 0
# Als het gemiddelde verschil dicht bij 0 zijn de waarde van de voor en de na meting min of meer gelijk
t.test(les7_urine_verschil$verschil,
mu=0)De output van de gepaarde t-test ziet er als volgt uit:
One Sample t-test
data: les7_urine_verschil$verschil
t = 2.9938, df = 4, p-value = 0.04019
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.1597379 4.2402621
sample estimates:
mean of x
2.2
De p-waarde = 0.04019 en dat is kleiner dan 0,05. De H0 wordt verworpen en de H1 wordt geaccepteerd. Er is wel een statistisch significant verschil tussen de na en de voor behandeling.
Omdat de t-test plaats vindt op de verschillen van de gepaarde metingen is er maar één data kolom. Vandaar dat in de output staat dat het een One Sample t-test is.
les7_opdracht
Een oncoloog wil de grootte van colorectale kanker meten na behandeling met een nieuw biofarmaceutisch middel. De oncoloog selecteerde patiënten met een stadium I-tumor met tumorgroottes van minder dan 2 cm. De oncoloog gebruikte een gepaarde proef opzet met twee metingen (voor en na de behandeling)
De data is precies hetzelfde als van opdracht1. De data is anders georganiseerd en is nu dus afkomstig van een gepaarde proefopzet.
- Kopiëer bestand les7_opdracht3.txt vanuit de gedeelde map (/home/data/mizi3v/les7) naar de map mizi3v/data/les7 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server).
De data is normaal verdeeld en heeft geen uitbijters:
- Is er een statistisch significant verschil in tumorgrootte tussen de voor en de na meting?
- Vergelijk de uitkomst van de gepaarde t-test met de uitkomst van opdracht1
- Wat is je conclusie?
Klik voor het antwoord
library(tidyverse)
# Importeren van de data in R object. Let op het decimaal teken!!
les7_opdracht3 <- read_tsv("data/les7/les7_opdracht3.txt",
locale=locale(decimal_mark = ","))
# Maak een extra kolom met het verschil tussen de voor en de na meting
les7_opdracht3_verschil <- les7_opdracht3 |>
mutate(verschil=na-voor)
# Voer de gepaarde ttest uit door het gemiddelde verschil te vergelijken met 0
t.test(les7_opdracht3_verschil$verschil,
mu=0)
# P-waarde = 0.02216. P-waarde < 0.05. Verwerp de H~0~ en accepteer de H~1~.
# Er is wel een statistisch significant verschil
# Conclusie: de p-waarde van de ongepaarde ttest (met dezelfde data) is 0.05955 > 0.05
# Dus gepaarde ttest is gevoeliger dan een ongepaarde proefopzet
# LET OP. Met een harde grens van 0.05 stimuleren we het zwart / wit denken: wel een verschil of geen verschil
# De p-waarde is maar net boven de 0.05. Met extra metingen was de p-waarde waarschijnlijk onder de 0.05 gekomen
# Dit is eigenlijk niet goed. Uiteindelijk gaat het er om of het verschil biologisch relevant is!Casus
In folder les7 op de gedeelde map staat bestand les7_casus.txt. het bestand bevat het gewicht van een groep mensen voor en na het gebruik van een afslankmiddel.
- Kopiëer bestand les7_casus.txt vanuit de gedeelde map (/home/data/mizi3v/les7) naar de map mizi3v/data/les7 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Laad de data in R
- Bepaal of de data normaal is verdeeld?
- Is er een statistisch significant verschil?