Les4 - Multiple Factors
Leerdoelen
De student kent / kan :
- Een full factorial ontwerp maken
- Hoofd en interactie effecten aflezen uit een grafiek
- Een Plackett-Burman ontwerp maken voor screening m.b.v. R
- Een fractional factorial ontwerp maken voor screening m.b.v. R
- Data van screening experimenten analyseren
Multiple factor ontwerp
In een “One Factor at the Time” (OFAT) ontwerp wordt zoals de naam al aangeeft slechts één onafhankelijke variabele (=factor) getest waarbij de factor één of meerdere “levels” kan hebben (zie les1). Bijvoorbeeld je test één drug (factor) met verschillende concentraties (levels) op een cellijn en meet het percentage apoptotische cellen. In een OFAT experiment kan alleen de vraag beantwoord worden of er een verschil is in de gemiddelde reponse tussen de groep die de behandeling niet heeft gehad (negatieve controle) en de groep(en) die de experimentele behandeling wel hebben gehad.
In werkelijkheid wordt de afhankelijke variabele beïnvloed door meerdere factoren die elkaar kunnen beïnvloeden (zie figuur 32). Als je meerdere factoren tegelijkertijd wilt testen wordt er gebruik gemaakt van een multiple factor ontwerp. De verzamelnaam en onderliggende methode om meerdere factoren te testen wordt Design of Experiments (DoE) genoemd.
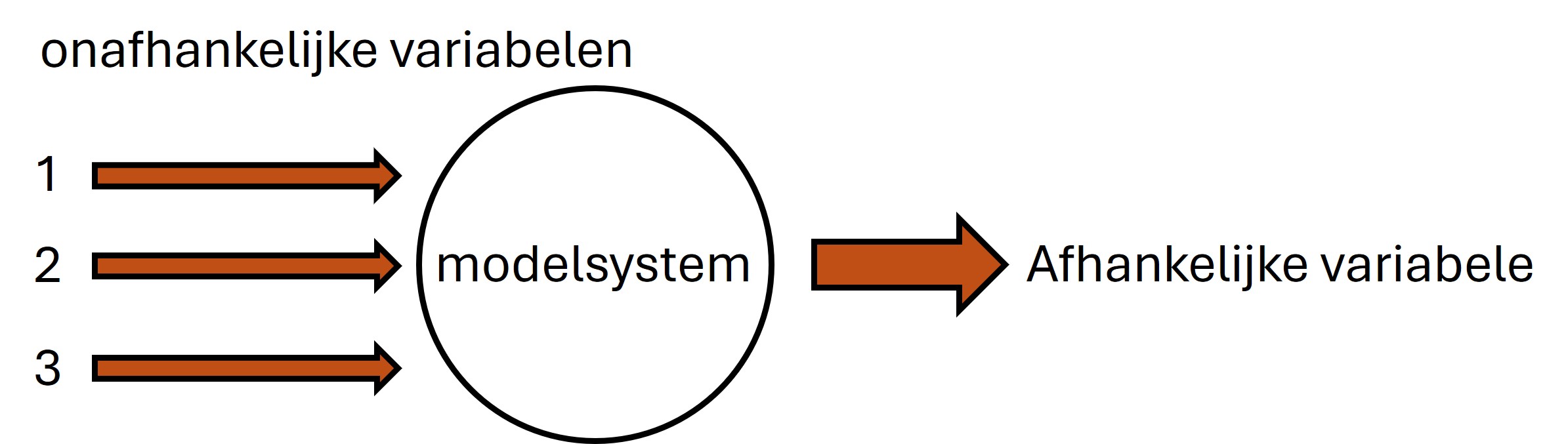
Figure 32: schematische weergave van een multiple-factor experimenteel ontwerp
Het testen van meerdere factoren in één experimenteel ontwerp maakt het mogelijk om:
- Hoofd en interactie-effecten aan te tonen tussen factoren
- Factoren te screenen die invloed hebben op de afhankelijke variabele
Afhankelijk van de onderzoeksvraag en het aantal factoren en bijbehorende levels wordt er gebruik gemaakt van een:
full factorial design: alle combinaties van de factoren en bijbehorende levels worden getest
fractional factorial design: een beperkt aantal combinaties van de factoren en bijbehorende levels worden getest
Plackett-Burman design: screening van 6 of meer factoren die onafhankelijk zijn
Full factorial: hoofd- en interactie effecten
Als er twee of drie factoren worden getest met voor iedere factor een beperkt aantal levels (2 of 3) kan een full factorial design worden gebruikt. In een full factorial experiment kunnen twee effecten bepaald worden:
- hoofd effect (main effect): wat zijn de effecten van iedere afzonderlijke factor (zonder rekening te houden met de andere factor)
- interactie-effect: hangt het effect van een factor af van de levels van de andere factor
Er zijn drie verschillende interactie-effecten:
- Additief effect: er is geen interactie, het gecombineerde effect is een optelsom van de afzonderlijke factoren
- Synergy effect: er is wel een interactie, het gecombineerde effect is groter dan de optelsom van de afzonderlijke factoren
- Antagonistisch effect: er is wel een interactie, het gecombineerde effect is kleiner dan de optelsom van de afzonderlijke factoren
Het verschil tussen een OFAT design en een full factorial design wordt uitgelegd aan de hand van de volgende onderzoeksvraag:
Wat is de invloed van drug X op de groeisnelheid in twee verschillende cellijnen:
modelsysteem: cellijn
factor1: drug X (0 nM en 25 nM)
factor2: celtype (darm en long)
afhankelijke variabele: groeisnelheid (verdubbelingstijd)
In een OFAT design worden de cellijnen ieder afzonderlijk getest (zie figuur 33A) en de enige factor die varieert is drug X met de levels 0 en 50 nM. In de statistische analyse (Student’s T test) kan voor iedere cellijn de vraag beantwoord worden of er een verschil is in de gemiddelde meetwaarden van de controle groep (0 nM) en de behandelde groep (50 nM). Voor iedere conditie gebruikt de onderzoeker 4 replica’s dus in totaal 4 x 4 = 16 replica’s.
In een full factorial ontwerp test de onderzoeker alles op dezelfde dag, met dezelfde reagentia en apparatuur waarbij alle levels van de factoren in alle mogelijke combinaties worden getest (figuur 33B). In deze opzet wordt dus zowel factor1 als factor2 gevariëerd. Dit wordt schematisch weergeven met een vierkant waarin iedere hoek een combinaties is van de levels van de factoren. De data van een full factorial ontwerp wordt statistisch verwerkt met een two-way ANOVA analyse.
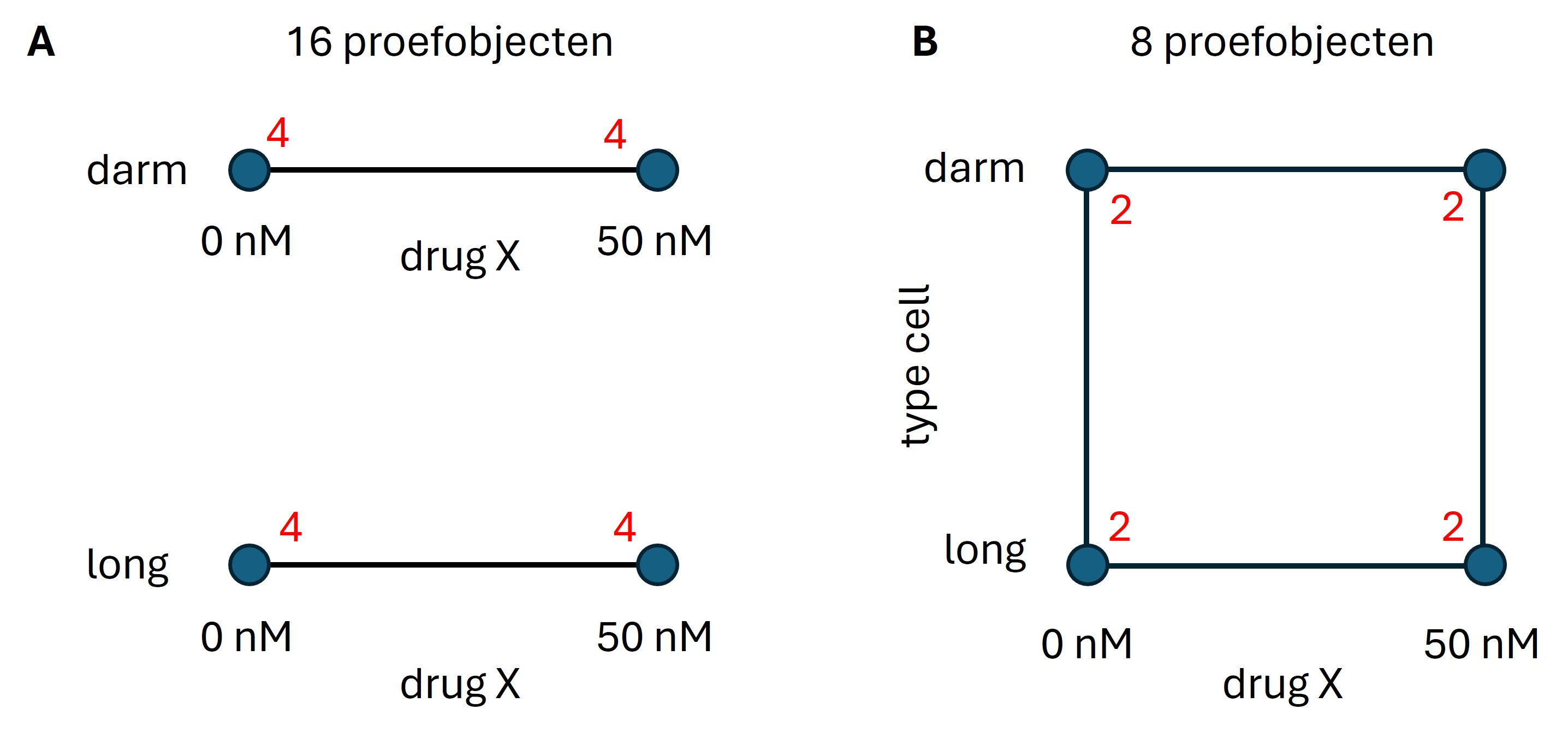
Figure 33: Vergelijking tussen (A) OFAT en (B) full factorial ontwerp om twee factoren te testen
In een full factorial design gebruikt de onderzoeker maar 2 replica’s per conditie dus in totaal 4 condities x 2 replica’s = 8 replica’s. Als we het hoofdeffect van de drug X willen bepalen, negeren we de factor cell type en zijn er voor de conditie van 0 en 50 nM ieder 4 replica’s (zie figuur 34A). Als we het hoofdeffect van het celtype willen bepalen, negeren we de factor drug X en zijn er voor de condities van long en darm ook ieder 4 replica’s (zie figuur 34B). Zowel de hoofdeffecten als de interactie-effecten kunnen worden gevisualiseerd met een staafdiagram of lijnfiguur (zie paragraaf Full factorial: visualisatie van hoofd en interactie effecten
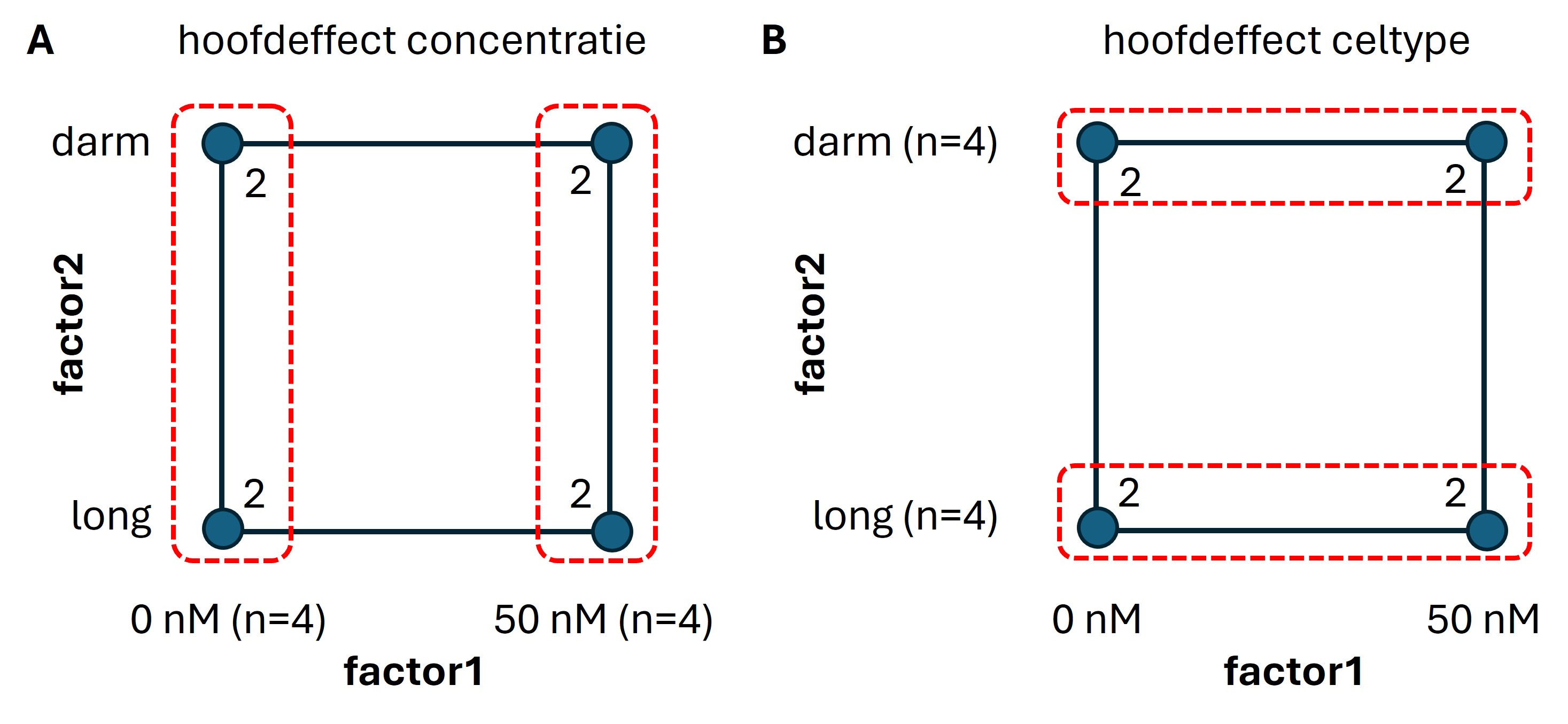
Figure 34: Aantal replica’s voor (A) factor1: drugs X en (B) factor2: cellijn
In een full factorial ontwerp gebruiken we minder replica’s en verkijgen we meer informatie (interactie effecten) in vergelijking met een OFAT ontwerp.
Full factorial: kruisdiagram
Het aantal experimentele condities van een full-factoriaal ontwerp kan berekend worden door het aantal levels van iedere factor met elkaar vermenigvuldigen:
- 2 factoren met ieder 2 levels: 2 x 2 = 4 condities
- 2 factoren met ieder 3 levels: 3 x 3 = 9 condities
- 1 factor met 2 levels en 1 factor met 3 levels: 2 x 3 = 6 condities
- 3 factoren met ieder 2 levels: 2 x 2 x 2 = 8 condities
- 3 factoren met ieder 3 levels: 3 x 3 x 3 = 27 condities
Een full-factoriaal design is het meest optimaal met een beperkt aantal factoren en levels. Als er teveel combinaties zijn om te testen kan er een selectie van combinaties gemaakt worden met behulp van fractional factorial design (zie paragraaf Screening: fractional factorial design)
les4_opdracht
- Hoeveel experimentele condities zijn aanwezig in een full factorial ontwerp met 2 factoren met ieder 10 levels
- Hoeveel experimentele condities zijn aanwezig in een full factorial ontwerp met 10 factoren met ieder 2 levels
Klik voor het antwoord
- 10 x 10 = 100 experimentele condities
- 210 = 1024 experimentele condities
Full factoriaal ontwerpen worden gevisualiseerd met een kruisdiagram waarbij ieder level van de factoren met elkaar worden gekruist (figuur 35A) of met een schema waarbij iedere kolom een aparte factor is en de levels worden aangeven met een getal (figuur 35B). Vaak is dit 0 en 1 (of -1 en 1) maar met drie levels wordt -1, 0 en 1 gebruikt.
LET OP: de 0 waarde verwijst slechts naar een bepaald level en geeft niet aan of het level wel of niet aanwezig is
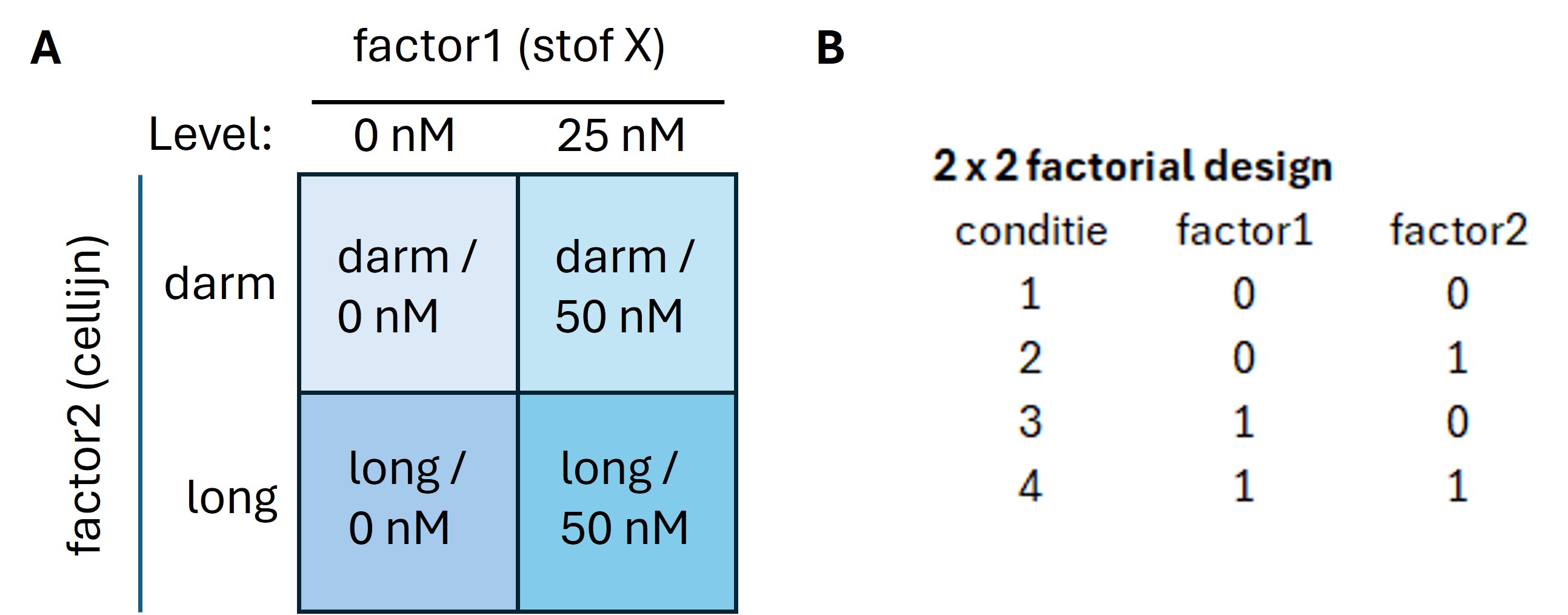
Figure 35: 2 x 2 kruisdiagram van een two-way experimenteel ontwerp. Iedere factor heeft 2 levels
Een factor kan ook meer dan twee “levels” hebben. Bijvoorbeeld welke combinatie van temperatuur en pH geeft de hoogste activiteit van enzym X:
- modelsysteem: enzym X
- factor1: temperatuur (levels: 30 en 37 ° Celsius)
- factor2: pH (levels: 6.5, 7.0 en 8.5)
- afhankelijke variabele: enzym activiteit
In dit geval is er sprake van een 2 X 3 experimenteel ontwerp (figuur 36A) en het bijbehorende schema waarbij iedere kolom een aparte factor is en de levels worden aangeven met -1, 0 en 1 (figuur 36B)
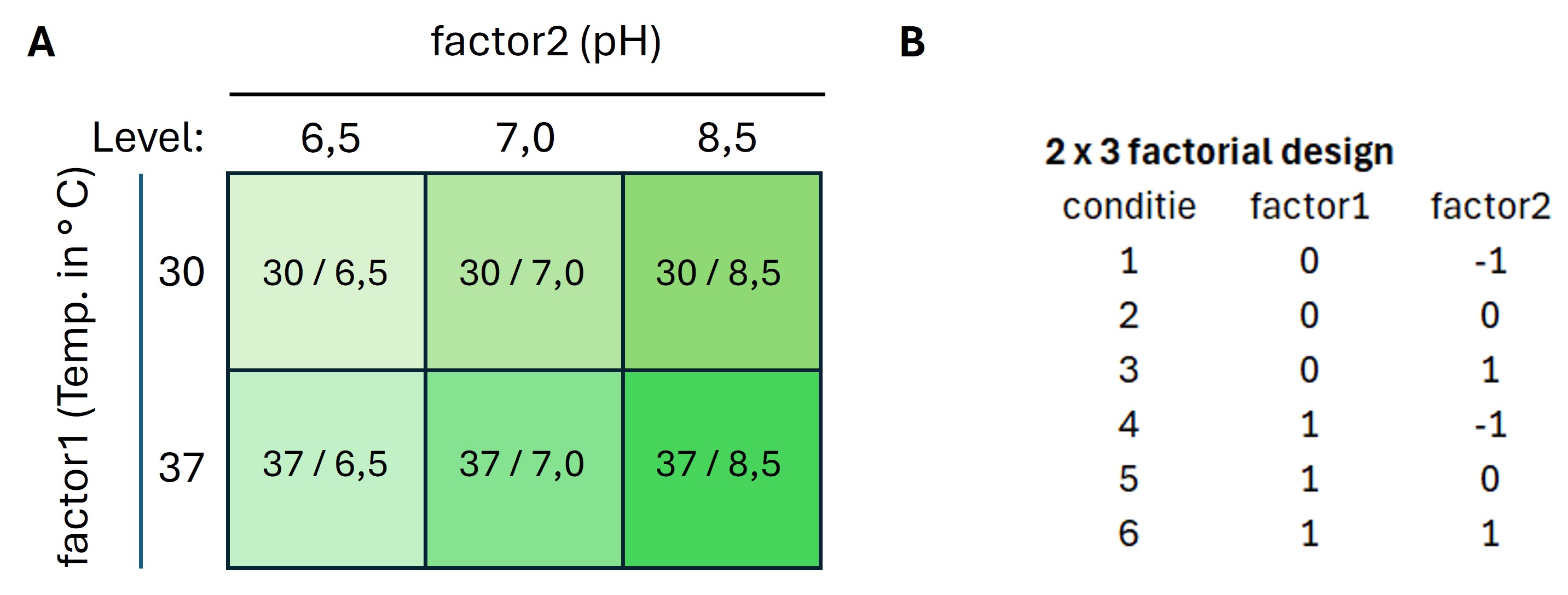
Figure 36: 2 x 3 kruisdiagram van een two-way experimenteel ontwerp. Factor1 heeft twee levels en factor2 heeft 3 levels
LET OP: Als er meer dan twee factoren zijn wordt het lastig om een kruisdiagram te maken en wordt een full factorial design altijd weergegeven met een schema zoals weergegeven in figuur 35B en 36B
Een full factorial design wordt gemaakt door de volgende R code met het FrF2 package. In het voorbeeld hieronder wordt een full factorial design gemaakt voor 3 factoren met ieder 2 levels. In totaal zijn er dan 23 = 8 runs
# Installatie van het FrF2 package indien het nog niet is geïnstalleerd.
if (!require("FrF2")) {
install.packages("FrF2")
library(FrF2)
}# Algemene naam van de factoren. Pas A, B, C enzovoorts naar keuze aan
factors_names<-c("A", "B", "C")
# maak het ontwerp met de FrF2 functie()
ff_design <- FrF2(nruns=8, # aantal runs: 2^3 = 8 -> full factorial design
nfactors = 3, # aantal factoren wat getest wordt
factor.names = factors_names)
# print het fractional factorial FrF2 ontwerp
print(ff_design)
# Optioneel: view the design information (aliases)
design.info(frf2_design)De output van de R code staat in de tabel hieronder. De volgorde van de runs kan verschillen van de output van de R code maar alle combinaties van de levels zijn hetzelfde
Tabel: Full factorial design met 3 factoren en levels. De levels worden weergegeven met -1 en 1.
| Run | Factor A | Factor B | Factor C |
|---|---|---|---|
| 1 | -1 | 1 | 1 |
| 2 | 1 | -1 | -1 |
| 3 | -1 | 1 | -1 |
| 4 | -1 | -1 | 1 |
| 5 | -1 | -1 | -1 |
| 6 | 1 | 1 | 1 |
| 7 | 1 | -1 | 1 |
| 8 | 1 | 1 | -1 |
Full factorial: visualisatie van hoofd en interactie effecten
De eerste stap in de analyse van een full factoriaal design is om de data te visualiseren en te kijken of er hoofd en interactie-effecten aanwezig zijn. Als er een verschil wordt waargenomen tussen de levels van de afzonderlijke factoren (hoofdeffecten) of als er interacties effecten aanwezig zijn dan moet dit altijd statistisch aangetoond worden met behulp van een two-way ANOVA.
LET OP: Als er twee factoren worden getest (factor A en factor B ) dan wordt een hoofdeffect genoteerd met de naam van de factor (A of B) en een interactie effect wordt altijd genoteerd als een samenvoeging van de factoren (AB, AxB of A:B).
Hieronder drie verschillende voorbeelden hoe je hoofd- en interactie-effecten kan aflezen in een grafiek:
Voorbeeld1 (zie figuur 37)
- Er is een hoofdeffect van de stof op de groeisnelheid: de groeisnelheid wordt verlaagd bij 25 nM (linker figuur)
- Er is geen hoofdeffect van celtype op de groeisnelheid: de groeisnelheid is gelijk in beide celtypes (middelste figuur)
- Er is geen interactie-effect: het verschil in groeisnelheid na de behandeling met de stof is gelijk in beide celtypes (rechter figuur)
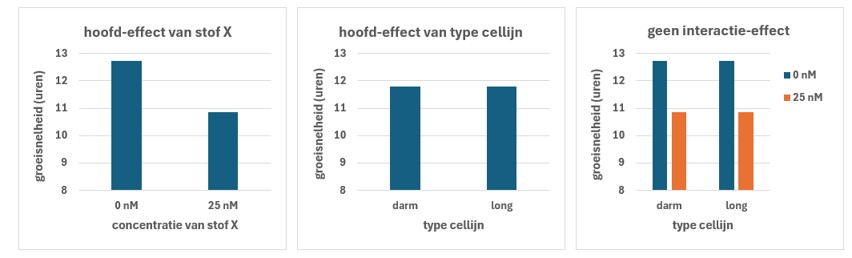
Figure 37: Visualisatie van hoofd- en interactie-effecten
Voorbeeld2 (zie figuur 38):
- Er is een hoofd-effect van de stof op de groeisnelheid: de groeisnelheid wordt verlaagd bij 25 nM (linker figuur)
- Er is een hoofd-effect van celtype op de groeisnelheid: de groeisnelheid is niet gelijk in beide celtypes (middelste figuur)
- Er is geen interactie-effect: het verschil in groeisnelheid na de behandeling met de stof is gelijk in beide celtypes (rechter figuur)
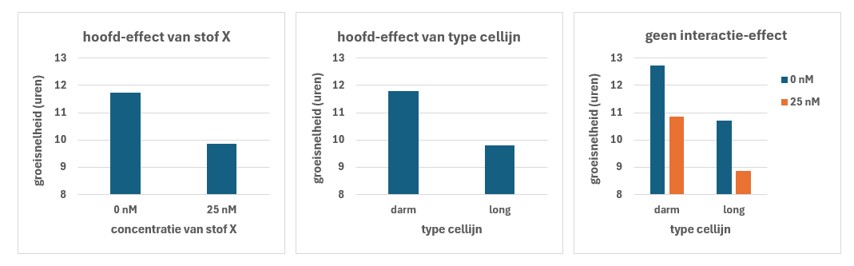
Figure 38: Visualisatie van hoofd- en interactie-effecten
Voorbeeld3 (zie figuur 39):
- Er is een hoofd-effect van stof X op de groeisnelheid: de groeisnelheid wordt verlaagd bij 25 nM (linker figuur)
- Er is een hoofd-effect van celtype op de groeisnelheid: de groeisnelheid is niet gelijk in beide celtypes (middelste figuur)
- Er is een interactie-effect: het verschil in groeisnelheid na de behandeling met stof is niet gelijk in beide celtypes (rechter figuur)
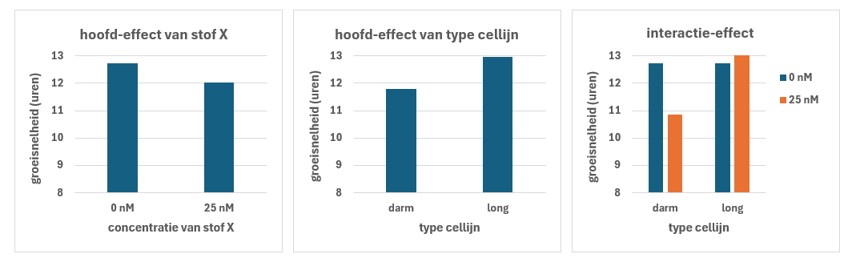
Figure 39: Visualisatie van hoofd- en interactie-effecten
les4_opdracht
Bestudeer de onderstaande grafieken:
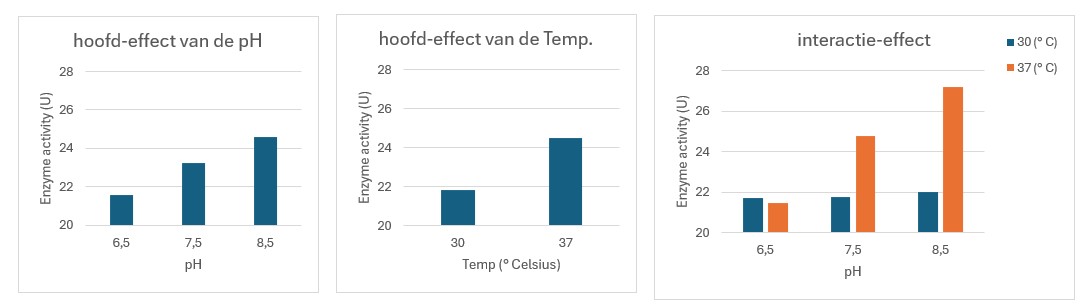
Figure 40: Visualisatie van hoofd- en interactie-effecten
Vul in:
Er is wel / geen hoofdeffect van de pH op de enzymactiviteit want …
Er is wel / geen hoofdeffect van de Temperatuur op de enzymactiviteit want …
Er is wel / geen interactie-effect op de enzymactiviteit want …
Klik voor het antwoord
Er is wel hoofdeffect van de pH op de enzymactiviteit want oplopende pH verhoogt de enzymactiviteit
Er is wel hoofdeffect van de Temperatuur op de enzymactiviteit want oplopende Temp verhoogt de enzymactiviteit
Er is wel interactie-effect op de enzymactiviteit want de pH heeft alleen maar een effect bij 37 °C en niet bij 30 °C. De temperatuur beinvloed het effect van de pH
LET OP: Als er een interactie-effect is kan je de hoofd-effecten niet interpreteren. In de linker figuur is te zien dat de pH een invloed heeft op de enzymactiviteit, maar dit is alleen van toepassing bij 37 °C en niet bij 30 °C (zie rechter figuur, vergelijk oranje staven met de blauwe staven)
Screening: inleiding
Een screening design identificeert factoren die effect hebben op de response (=afhankelijke variabele) (figuur 41). Met een beperkt aantal experimentele condities (ook wel runs genoemd in dit soort designs) kunnen we efficiënt een groot aantal factoren testen.
Figure 41: Identificatie van factors die invloed hebben op de afhankelijke variabele
Screening: Plackett-Burman
Als we een groot aantal factoren, dat is zes of meer factoren waarbij iedere factor twee levels heeft, snel en efficient willen testen kan het Plackett-Burman design gebruikt worden. De voorwaarde is wel dat de factoren elkaar niet beïnvloeden; de factoren zijn onafhankelijk en hebben geen interacties met elkaar. We meten alleen de hoofdeffecten!
Een voorbeeld van een Plackett-Burman screening assay in de Life Science is het bepalen welke factoren invloed hebben op de productie van eiwitten. Recombinanten eiwitten worden op grote schaal geproduceerd in de farmaceutische industrie en voedingsindustrie. Denk bijvoorbeeld aan stollingsfactoren, antilichamen of specifieke enzymen. Een veelgebruikt modelsysteem om eiwitten te produceren is E. coli. Na toevoeging van een inducer (IPTG) wordt het eiwit van interesse in grote hoeveelheden aangemaakt vanaf een plasmide. Naast IPTG zijn er andere factoren die een rol spelen in de eiwitopbrengst (zie Tabel I)
Tabel I: Factoren die de opbrengst van eiwitproductie kunnen beïnvloeden
| Factor | Description | Low Level (-1) | High Level (+1) |
|---|---|---|---|
| IPTG | Inducer concentration | 0.1 mM | 1.0 mM |
| Temp | Induction temperature | 20 °C | 37 °C |
| OD600 | OD600 at induction | 0.4 | 0.8 |
| Tijd | Induction duration | 4 h | 16 h |
| pH | Medium pH | 6.5 | 7.5 |
| Glucose | Glucose concentration | 1 g/L | 5 g/L |
In een Plackett-Burman design zijn er altijd 12 testcondities als het aantal factoren dat je wilt testen kleiner is dan 11 (ter vergelijking, met een OFAT experiment zijn er 36 testcondities nodig: 6 factoren x 2 levels x 3 replica’s (per level) = 36 testcondities en in vergelijking met een full factorial design zijn er 26 = 2 x 2 x 2 x 2 x 2 x 2 = 64 testcondities nodig om alle combinaties te testen).
In een Plackett-Burman ontwerp worden de verschillende factoren en levels op een “slimme” manier gecombineerd door middel van bepaalde wiskundige principes zodat met een minimale hoeveelheid runs er maximale informatie behaald kan worden uit een experiment.
Een Plackett-Burman design wordt gemaakt door de volgende R code met het FrF2 package
# Install if not already installed
install.packages("FrF2")
# Load the package
library(FrF2)
# Naam van de factoren. Pas A, B, C enzovoorts naar keuze aan
factors_names<-c("A", "B", "C", "D", "E", "F")
# maak het ontwerp met de pb functie()
pb_design <- pb(nruns= 12, # aantal runs
nfactors = 6, # aantal factoren wat getest wordt
factor.names = factors_names)
# print het PB ontwerp
print(pb_design)De uitkomst van de bovenstaande R code staat in figuur 42 (De laatste kolom bevat dummy data en is niet onderdeel van de output)
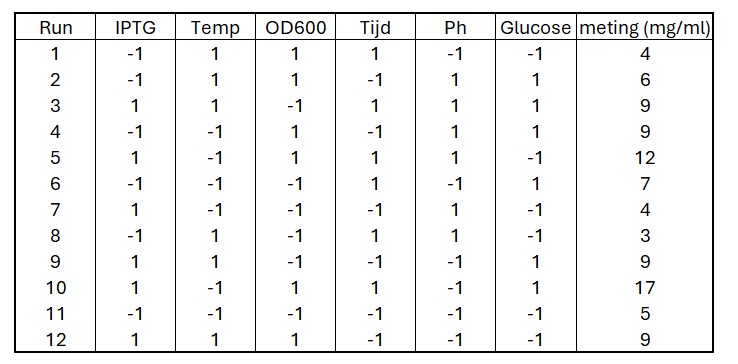
Figure 42: Voorbeeld van een Plackett-Burman design met zes factoren met ieder twee levels. De -1 en de 1 staan voor de verschillende levels van iedere factor
In een PB design is er in iedere kolom (= factor) evenveel van level -1 als level +1 aanwezig. In het geval met een ontwerp van 12 runs, is er in iedere kolom 6 keer -1 aanwezig en 6 keer +1. Het PB design dient tevens als pipeteerschema als we de codering van -1 en +1 vervangen voor de waarden van de levels van de factoren (zie Tabel I). Vervolgens wordt (na verdere opwerking in het lab) de eiwitconcentratie van iedere run gemeten (zie de laatste kolom van figuur 25. Dit is een fictieve dataset en dient alleen als rekenvoorbeeld voor figuur 26)
In een experimenteel ontwerp worden de levels van een factor gecodeerd met -1 en 1 (en met drie levels -1, 0 en 1). Iedere regel in het ontwerp is een test conditie en staat voor een bepaalde combinatie van factoren en de bijbehorende levels. Als je de codering vervangt voor de echte waarden van de levels verkrijg je een pipeteerschema voor in het lab
Na de uitvoering van het experiment willen we graag weten welke factor het meeste invloed heeft op de response. De meest simpele methode is om voor iedere factor het gemiddelde uit te rekenen van de -1 en +1 levels en vervolgens het verschil uit te rekenen tussen de levels zoals uitgelegd aan de hand van fictieve data in Tabel II.
Tabel II: Effect van factor A en B op de response. Iedere factor heeft 2 levels
| A | B | Response |
|---|---|---|
| -1 | -1 | 10 |
| +1 | -1 | 14 |
| -1 | +1 | 12 |
| +1 | +1 | 20 |
Hoofdeffect factor A:
Factor A level +1 = [(14 + 20)/2] = 17
factor A level -1 = [(10 + 12)/2] = 11
Verschil tussen level + 1 en -1 = 17 -11 = 6
Hoofdeffect factor B:
Factor B level +1 = [(12 + 20)/2] = 16
Factor B level -1 = [(10 + 14)/2] = 12
Verschil tussen level + 1 en -1 = 16 -12 = 4
Factor A heeft een groter verschil tussen de levels (6) in vergelijking met factor B (4). Conclusie: factor A heeft een groter effect dan factor B
In het voorbeeld van de eiwitconcentratie van Tabel I zijn er 12 runs en 6 factoren. Iedere factor heeft voor ieder level 6 metingen. Het stappenplan voor iedere factor is als volgt:
- Sorteer op kolom IPTG en bereken de gemiddelde eiwitopbrengst van de -1 en de + 1 levels…
- Bereken het verschil tussen de levels…
- Herhaal voor de 2de factor enzovoorts
Een R script om data van screenings-assays te visualiseren kan hier gedownload worden. Dit script gebruikt het ontwerp en de data van figuur 42. Het inlezen van data bestanden in R en het maken van grafieken met ggplot2 is uitgelegd in les2 van de cursus TLSC-IBIP2V-24. Het script is nodig voor de casus dus bestudeer het goed.
Het resultaat van de gemiddelde levels per factor staat in figuur 43
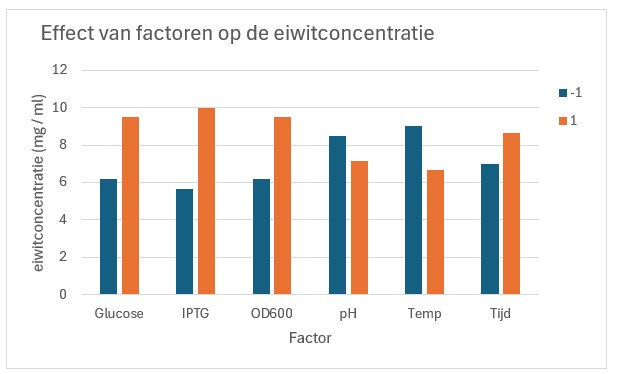
Figure 43: Data analyse van een PB design met 6 factoren
De factor met het grootste (positieve) verschil (want we willen een hoge opbrengst) is de factor die het meeste invloed heeft op de eiwitconcentratie. In dit voorbeeld zien we dat een verschil in IPTG concentratie, de meeste invloed heeft op de eiwitconcentratie. Als we dit statistisch willen onderbouwen gebruiken we een ANOVA of een lineaire regressie analyse.
Samenvattend gebruiken we Plackett-Burman design voor een snelle screening van 6 of meer factoren, waarvan de factoren onhankelijk zijn, dat wil zeggen de factoren beïnvloeden elkaar niet.
LET OP: Of factoren elkaar kunnen beïnvloeden moet opgezocht worden in de literatuur. Wat is het (moleculaire) mechanisme hoe een factor een response beïnvloed. Werken de factoren binnen dezelfde moleculaire pathway, binden ze aan dezelfde moleculen (DNA, RNA, eiwitten), vormen ze een complex enzovoorts en wat effect zou dit kunnen hebben op de response?
Screening: fractional factorial design
De voorwaarde van een Plackett-Burman design is dat er geen interacties zijn tussen de factoren. Als er een vermoeden is dat er wel interacties zijn tussen de factoren, kan je een fractional factorial design gebruiken. Een fractional factorial betekent een gedeelte van een full factorial design (zie tabel III).
Tabel III: Aantal runs die nodig zijn in een full factorial ontwerp voor 2 t/m 10 factoren met 2 levels
| Factor | Runs |
|---|---|
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
| 5 | 32 |
| 6 | 64 |
| 7 | 128 |
| 8 | 256 |
| 9 | 512 |
| 10 | 1024 |
Als we niet alle runs willen testen, maar slecht een beperkt aantal dan verliezen we informatie (want niet alle combinaties tussen factyoren en levels kunnen dan getest worden). Dit wordt aangegeven met de resolutie van een fractional factorial design. De resolutie wordt weergegeven in figuur 44
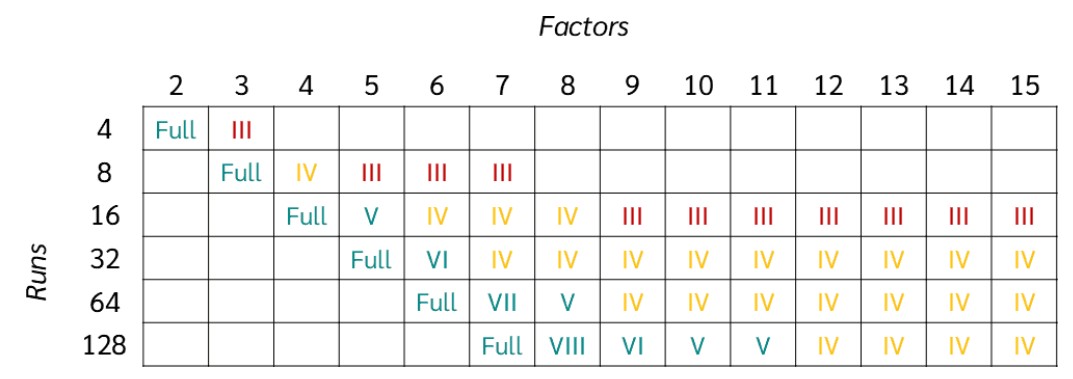
Figure 44: Resolutie van fractional factorial designs
Als we naar de kolom kijken met 6 factors zien we dat er 64 runs nodig zijn voor een full factorial experiment. We willen dit terugbrengen naar minder runs om tijd en kosten te besparen zonder dat we teveel informatie verliezen. Als vuistregel kiezen we voor een resolutie van IV of hoger. In het voorbeeld van de eiwitproductie, waarin we 6 factoren testen, kunnen we dit dus reduceren tot 16 runs zodat het experiment een resolutie heeft van IV. Dit zijn 4 runs extra in vergelijking met de Plackett-Burman design, maar we kunnen nu wel, tot op zekere hoogte, ook interacties in kaart brengen.
Het ontwerp kunnen we laten genereren door R met het FrF2 package:
# Install if not already installed
install.packages("FrF2")
# Load the package
library(FrF2)
# Algemene naam van de factoren. Pas A, B, C enzovoorts naar keuze aan
factors_names<-c("A", "B", "C", "D", "E", "F")
# maak het ontwerp met de FrF2 functie()
frf2_design <- FrF2(nruns=16, # aantal runs
nfactors = 6, # aantal factoren wat getest wordt
factor.names = factors_names)
# print het fractional factorial FrF2 ontwerp
print(frf2_design)
# Optioneel: view the design information (aliases)
design.info(frf2_design)De uitkomst van de bovenstaande R code staat in figuur 45
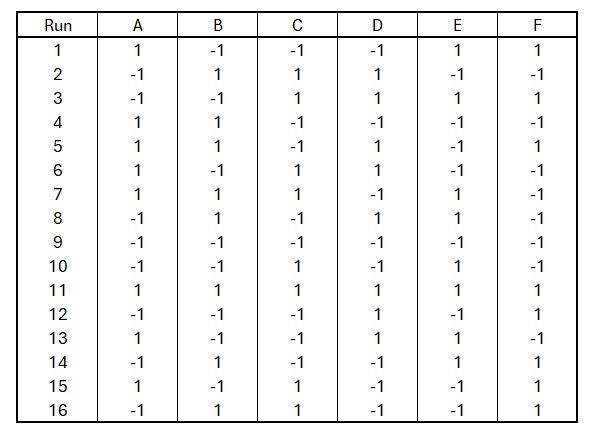
Figure 45: Voorbeeld van een fractional factorial design met zes factoren met ieder twee levels. De -1 en de 1 staan voor de verschillende levels van iedere factor. Het ontwerp heeft een resolutie van IV
Het ontwerp ziet er hetzelfde uit als met een Plackett-Burman design (zie figuur 42). In iedere kolom staat een factor en de levels zijn gelijkmatig verdeeld in de kolommen. In dit ontwerp is er in iedere kolom 8 keer -1 en 8 keer 1 aanwezig omdat er in totaal 16 runs zijn.
LET OP: de ontwerpschema’s van Plackert-Burman en fractional factorial design lijken op elkaar maar conceptueel zijn het verschillende ontwerpen!!
De initiële data-analyse van een factorial factor ontwerp is hetzelfde als voor een Plackert-Burman ontwerp. Voor iedere factor wordt het gemiddelde uitgerekend van de -1 en 1 levels en de grootte van het verschil bepaald in welke mate de factor een effect heeft op de response. Interactie effecten kunnen gevisualiseerd worden met behulp van staafdiagrammen. Voor de verdere statistische analyse gebruiken we een ANOVA of een lineaire regressie analyse.
Samenvatting
Gebruik dit stappenplan om een experimenteel ontwerp te maken en de data te analyseren:
Beperkt aantal factoren met 2 of 3 levels om interacties in kaart te brengen -> Full factorial
Data analyse:
Hoofd- en interactie-effecten aflezen in grafiekScreening:
- 6 of meerdere factoren -> Plackett-Burman (onder de voorwaarde dat er geen interacties zijn tussen de factoren)
- 5 of minder factoren -> full of fractional factor design (gebruik resolutie IV)
Data analyse:
- Bereken het verschil tussen het gemiddelde van iedere level per factor
- Factor met het grootste verschil levert de meeste bijdrage aan de response
Casus
Deel 1
In het artikel van Jia is een combinatie van 5 verschillende drugs getest op de levensvatbaarheid van prostaatkanker cellen. Ze hebben hiervoor een full factorial ontwerp gebruikt. Bestudeer de volgende secties, tabellen en figuren van het artikel:
- Introduction
- Material and methods
2.1. Anti-tumor drug combination experiments
2.2.1. Full factorial design (eerste 10 regels)
- Results and discussion
- Tabel 1
- Tabel 2
- figuur 1
Beantwoord de volgende vragen over het experimentele ontwerp:
- Onafhankelijke variabele:
- Welke factoren worden getest?
- Wat zijn de levels van de factoren?
- Modelsysteem
- Welke cellijn is gebruikt als modelsysteem.
- Wat is dit voor cellijn. Zoek informatie op m.b.v. [co-pilot] (zie bijlage2)
- Hoe lang zijn de cellen blootgesteld aan de verschillende drugs
- Wat is de afhankelijke variabele:
- Wat is er gemeten?
- En welke assay hebben ze daarvoor gebruikt
- De data van tabel 2 staat in bestand les4_casus_data.txt
- Analyseer de data in R. Maak een staafdiagram voor iedere factor en levels
Pas het R script van figuur 42/43 aan om de data uit te werken
- Welke factor(en) hebben de meeste invloed op de response?
- Is er een interactie effect tussen D1 (Doxorubicin) en D2 (Docetaxel) (zie figuur 46). Indien aanwezig, wat voor type interactie effect is het?
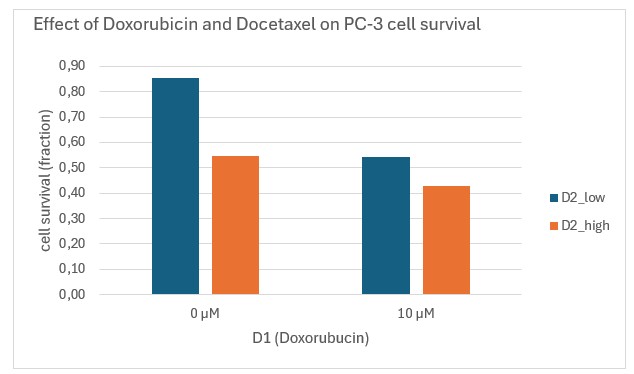
Figure 46: Weergave van interactie-effecten van D1 en D2
Deel 2
De onderzoekers willen dezelfde screening uitvoeren met minder runs.
- Maak een Plackert-Burman ontwerp in R om de 6 factoren te testen.
- Maak een fractorial factorial ontwerp in R om de 6 factoren te testen.
- Welk ontwerp (Plackert-Burman of fractorial factor) ga je gebruiken. Leg uit?