Les5 - Beschrijvende Statistiek
Leerdoelen
De student kent / kan :
- Beschrijvende statistiek uitvoeren in R
- Data visualiseren met behulp ggplot2
- De distributie van een dataset bepalen
Introductie
In de VL2 cursus TLSC-ibip-24 programmeren in R hebben jullie al kennisgemaakt met het data analyse stappenplan. Om je geheugen op te frissen, worden de vijf stappen hieronder kort beschreven. In deze cursus gaan we hetzelfde stappenplan gebruiken om data te analyseren in R (zie figuur 47).
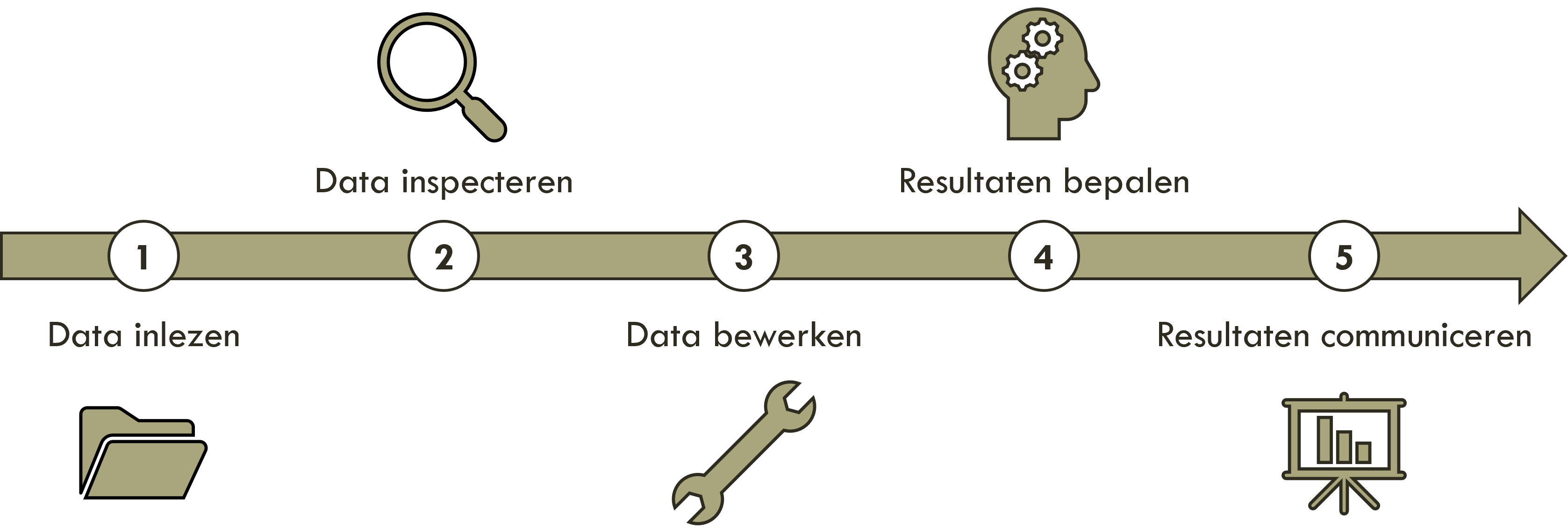
Figure 47: Data analyse stappenplan
Stap 1: data inlezen
- Data inlezen in R.
- Controleren of het inlezen goed is gegaan (bijv. is tekst ingelezen als tekst en zijn nummers ingelezen als nummers).
- Controleren of er missende waarden aanwezig zijn en of die correct zijn gecodeerd.
- Data omzetten naar een tidy format.
Stap 2: data inspecteren
- Wat is er gemeten? Welke variabelen zijn er? Hoeveel observaties zijn er?
- Vaststellen of er uitschieters (‘outliers’) in de data aanwezig zijn en deze outliers eventueel verwijderen.
- Vaststellen hoe de data verdeeld is (bijv. normaal verdeeld of niet).
- Controleren of de data van voldoende kwaliteit is om te gebruiken voor verdere analyses (‘quality control’).
Stap 3: data bewerken
- De dataset voorbereiden voor het beantwoorden van de onderzoeksvraag (bijv. door variabelen te filteren of nieuwe variabelen te bepalen).
Stap 4: resultaten bepalen
- Beschrijvende statistiek om de eigenschappen van de dataset in kaart te brengen
- Inductieve statistiek gebruiken om te bepalen of het effect van een experimentele behandeling statistisch significant is
Stap 5: resultaten communiceren
- De statistische analyse grafisch weergeven in informatieve grafieken.
- De complete data analyse uitwerken in een rapport dat gemakkelijk gebruikt kan worden door andere onderzoekers om jouw bevindingen te herhalen/controleren.
Data management
Vanaf les5 t/m les8 gaan we alleen maar gebruik maken van R functies voor de beschrijvende en inductieve statistiek. Het is daarom belangrijk dat we de server goed inrichten.
Ga naar bijlage3 voor instructie over:
- Hoe maak je een R project aan
- Hoe maak je een R script aan
- Welke mapjes moeten er aanwezig zijn in mijn homefolder
- Hoe kopiëer ik bestanden van de gedeelde folder naar de juiste folder in mijn homefolder
LET OP: In les5 t/m les8 wordt alleen de R code gegeven en NIET de output van de R code. Om de R code en de bijbehorende output goed te kunnen begrijpen moet je zelf de code uitvoer in Rstudio. De code kan ook bewaard worden in een script en het script kan opgeslagen worden in de scripts folder. Hetzelfde geldt voor het maken van de opdrachten. Sla de code op in een script en bewaar in de scripts folder in je home-account. Op deze manier kan je de opdrachten altijd weer (reproduceerbaar) herhalen.
R packages
Voordat we beginnen met de beschrijvende statistiek, zorg er voor dat je de benodigde packages activeert in de R console met de library() functie
library(tidyverse)
library(ggplot2)Data structuur en tidy data
Voordat we de data gaan beschrijven, eerst een herhaling over tidy data. Data komt vaak in verschillende kolommen (zie figuur 48) waarbij iedere kolom een experimentele conditie is.
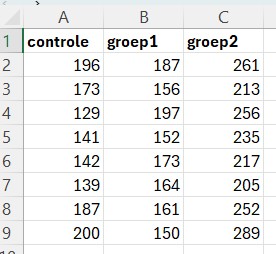
Figure 48: Data set met verschillende kolommen
Als we data inlezen in R dan bevat het R object voor iedere experimentele groep 1 kolom
# Aanmaken van een tibble data object. De data wordt opgeslagen in object dataset1
dataset1 <- tibble(controle=c(196,173,129,141,142,139,187,200),
groep1=c(187,156,197,152,173,164,161,150),
groep2=c(261,213,256,235,217,205,252,289)
)Als we voor iedere kolom de maximale waarde willen bepalen kan dit met de volgende R code:
# Selectie van een data kolom van object dataset1 d.m.v. het $ teken
sum(dataset1$controle)
sum(dataset1$groep1)
sum(dataset1$groep2)Maar als we 100 kolommen hebben in een dataset dan moeten we de code 100 keer herhalen. In een script herhalen we nooit de code!!!
Een alternatieve methode is om gebruik te maken van de map() functie. Er zijn verschillende varianten van de map() functie afhankelijk wat voor data type de output moet zijn. De map() functie voert een functie uit voor iedere kolom in de dataset. Hier maken we gebruik van de map_dbl() functie in combinatie met de sum() functie. De output van deze functie is een vector met getallen. Voor iedere kolom van data-object dataset1 wordt de som uitgerekend.
dataset1 |> map_dbl(sum)Als laatste optie kunnen we de data ook tidy maken. Dit is het standaard dataformat waarop alle functies van de packages tidyverse en ggplot2 werken. Het voordeel is dat meerdere beschrijvende statistieken uitgerekend kunnen worden voor iedere kolom in de dataset
# dataset tidy maken met de pivot_longer functie
dataset1_tidy <- dataset1 |> pivot_longer(cols=c("controle","groep1", "groep2"),
names_to="groep",
values_to="meting")
# uitrekenen van de verschillende beschrijvende statistieken voor iedere kolom m.b.v. de group_by() en summarize() functies
dataset1_tidy |>
group_by(groep) |>
summarize(mean=mean(meting),
median=median(meting),
sd=sd(meting))Beschrijvende statistiek
Beschrijvende statistiek vat data samen om trends of patronen te ontdekken, geeft aan wat de spreiding is van de meetpunten en visualiseert de data in grafieken. Beschrijvende statistiek van een steekproef heeft altijd betrekking op de steekproef zelf en beschrijft niet de populatie waaruit de steekproef afkomstig is.
Steekproeven worden samengevat door een enkele waarde zoals de modus, mediaan of het gemiddelde. Dit wordt een puntschatting genoemd.
Modus
Waarde die het vaakst voorkomt in een dataset:
data set: 2 2 4 5 5 5 8 9 9 12
Modus = 5
Als we de modus willen bepalen van een dataset kunnen we de volgende R code gebruiken:
# data koppelen aan een R object
les5_data1 <-tibble(data=c(2, 2, 4, 5, 5, 5, 8, 9, 9, 12))
# tel hoe vaak iedere waarde voorkomt in de tabel met de count() functie
freq_table <- les5_data1 |>
count(data, name = "frequency")
# sorteer de frequentie tabel van laag naar hoog (eerste waarde is de modus)
freq_table |> arrange(desc(frequency))Mediaan
De mediaan is de middelste waarde van een geordende dataset. De mediaan splitst de data in twee gelijke groepen. De helft van de waarden ligt onder / boven de mediaan:
data set: 2 2 4 5 5 5 8 9 9 10 12
Mediaan = 5
Berekening van de mediaan in R:
# data koppelen aan een R object
les5_data2<-tibble(data=c(2,2,4,5,5,5,8,9,9,10,12))
# bereken de mediaan
median(les5_data2$data)LET OP: als er een NA waarde aanwezig is in de dataset wordt de mediaan zonder correctie in de R code ook NA
# data koppelen aan een R object
les5_data3<-tibble(data=c(2,2,4,5,5,5,8,9,9,10,12,NA))
# bereken de mediaan
median(les5_data3$data)
# de OUTPUT = NAJe moet expliciet aangeven dat de NA waarde verwijderd moet worden uit de dataset met na.rm=T. Dit geldt voor alle R functies die een berekening doen op de data
# data koppelen aan een R object
les5_data3<-tibble(data=c(2,2,4,5,5,5,8,9,9,10,12,NA))
# bereken de mediaan
median(les5_data3$data, na.rm=T)
# de OUTPUT = 5Gemiddelde
Som van alle waarden gedeeld door het aantal waarden.
- Symbool voor het populatiegemiddelde: \(\mu\)
- Symbool voor het steekproefgemiddelde: x̄
Het gemiddelde is het balanspunt van de data. De waarden onder het gemiddelde hebben samen dezelfde totale afwijking als de waarden boven het gemiddelde.
data set: 2 2 4 5 5 5 8 9 9 10 12
gemiddelde: 6,45
Berekening van het gemiddelde in R:
# data koppelen aan een R object
les5_data4<-tibble(data=c(2,2,4,5,5,5,8,9,9,10,12))
# bereken het gemiddelde
mean(les5_data4$data)LET OP: Ook voor het gemiddelde geldt dat je expliciet moet aangeven dat de NA waarde verwijderd moet worden uit de dataset met na.rm=T
# data koppelen aan een R object
les5_data4_NA<-tibble(data=c(2,2,4,5,5,5,NA,8,9,9,10,12))
# bereken het gemiddelde
mean(les5_data4_NA$data, na.rm=T)Als vuistregel kunnen we zeggen dat de data hoogstwaarschijnlijk normaal verdeeld is als de mediaan en het gemiddelde min of meer hetzelfde zijn. Als de mediaan en het gemiddelde veel van elkaar afwijken dan heeft de data een scheve verdeling. Dit is belangrijk voor het bepalen van de juiste statistische toets (zie ook de paragrafen over boxplots en histogrammen)
Spreiding
Een belangrijke vraag is hoe goed de puntschatting de hele dataset vertegenwoordigt? Hiervoor wordt de spreiding van de data berekend en gevisualiseerd. Hoe dicht of ver liggen de individuele datapunten van elkaar en ten opzichte van de puntschatting zoals het gemiddelde? Als de waarden dicht bij elkaar liggen is de spreiding klein. Als de datapunten ver uit elkaar liggen is de spreiding groot. In een experiment streven we er altijd naar dat de biologische replicaties binnen een experimentele groep een zo’n klein mogelijke spreiding hebben.
De spreiding wordt gekwantificeerd met de volgende statistieken:
- Bereik
- Kwantielen
- Inter Quartile Range (IQR)
- variantie en standaarddeviatie
Bereik (range):
Verschil tussen de hoogste en de laagste meetwaarde
data set: 2 2 4 5 5 5 8 9 9 12
bereik = 12 - 2 = 10
Berekening van het bereik in R:
# data koppelen aan een R object
les5_data5<-tibble(data=c(2,2,4,5,5,5,8,9,9,12))
# verkrijg de maximale waarde van de dataset
max_value <- max(les5_data5$data)
# verkrijg de minimale waarde van de dataset
min_value <- min(les5_data5$data)
# bereken de range
bereik <- max_value-min_value
bereikKwantielen
Waarden van de dataset die de geordende dataset opdelen in een aantal groepen.
Kwartielen verdelen geordende data in vier gelijke groepen:
data set: 2 2 4 5 5 5 8 9 9 10 12
eerste kwartiel (25%) = 4
tweede kwartiel (50%) = 5
derde kwartiel (75%) = 9
Het tweede kwartiel = mediaan
Berekening van kwantielen in R:
# data koppelen aan een R object
les5_data6<-tibble(data=c(2,2,4,5,5,5,8,9,9,10,12))
# bereken de kwantielen
quantile(les5_data6$data, type=2)
# er zijn verschillende definities van quantiles:
# het middelste punt van een dataset of het middenpunt van twee opeenvolgende getallenBinnen de quantile() functie kan je specifiek aangeven welke kwantiel er uitgerekend moet worden
quantile(les5_data6$data, 0, na.rm = TRUE, type=2) # q0 = minimum waarde
quantile(les5_data6$data, 0.25, na.rm = TRUE, type=2) # q25 = eerste kwantiel
quantile(les5_data6$data, 0.50, na.rm = TRUE, type=2) # q50 = tweede kwantiel = mediaan
quantile(les5_data6$data, 0.75, na.rm = TRUE, type=2) # q75 = derde kwantiel
quantile(les5_data6$data, 1, na.rm = TRUE, type=2) # q100 = maximale waardeInter Quartile Range (IQR): verschil tussen derde en eerste kwartiel:
In het bovenstaande voorbeeld is de IQR: 9 - 4 = 5
# bereken de IQR
IQR(les5_data6$data, type=2)De IQR wordt gebruikt om uitbijters te definiëren (zie les6)
Variantie en standaarddeviatie
De variantie en de standaarddeviatie geven aan hoe ver de datapunten gemiddeld verwijderd zijn van het gemiddelde (figuur 49, gemiddelde = rode lijn).
De standaarddeviatie is een afgeleide van de variantie waarbij
variantie = standaarddeviatie2
of andersom
standaarddeviatie = \(\sqrt{variantie}\)
Het symbool voor de variantie van een steekproef: s2
Het symbool voor de standaarddeviatie van een steekproef: s
Het stappenplan om de variantie van een steekproef uit te berekenen (zie figuur 49):
- Voor elke meetwaarde: bereken het verschil (groene pijlen) met het gemiddelde (rode lijn)
- Kwadrateer dit verschil
- Alle gekwadrateerde verschillen worden opgeteld (= totale gekwadrateerde afwijking)
- De totale gekwadrateerde afwijking wordt gedeeld door de steekproefgrootte min 1 (n-1)
- Om de standaardeviatie (s) uit te rekenen wordt de wortel genomen van de variantie
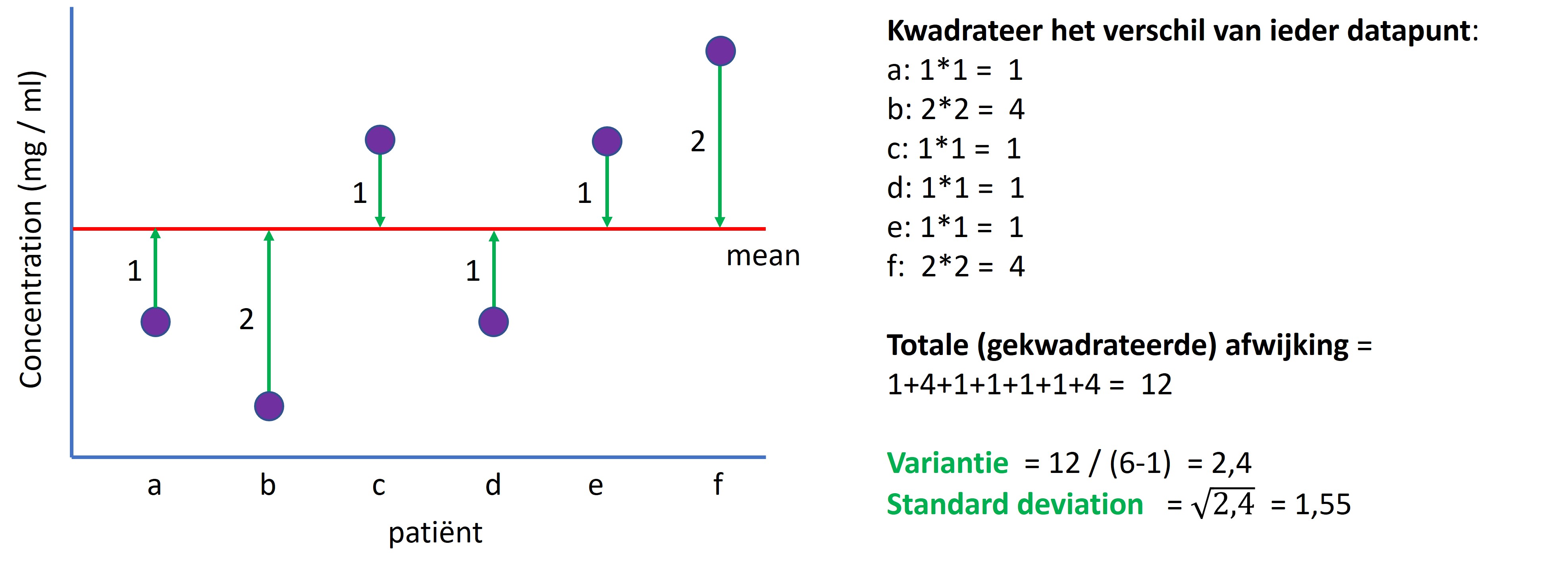
Figure 49: Stappenplan voor het berekenen van de variantie en de standaarddeviatie
De variantie wordt uitgerekend met de var() functie.
De standaarddeviatie wordt uitgerekend met de sd() functie.
BELANGRIJK: het gemiddelde en de standaarddeviatie worden in grote mate beinvloed door uitbijters. Het is daarom belangrijk om uitbijters op te sporen in een dataset en indien verantwoord, te verwijderen (zie les6).
Variatie coëfficient (Coefficient of variation (CoV))
Een gemiddelde zonder standaarddeviatie heeft geen betekenis en de standaardeviatie is alleen zinvol in relatief tot het gemiddelde
steekproef 1: gemiddelde = 50, standarddeviatie = 10
steekproef 2: gemiddelde = 20, standarddeviatie = 10
Beide steekproeven hebben een standaarddeviatie van 10. Maar een spreiding van 10 ten opzichte van 50 is minder dramatisch in vergelijking met 10 ten opzichte van 20. De standaarddeviatie in relatie tot het gemiddelde wordt uitgedrukt met de Variatie Coëfficient
CoV: standarddeviatie gedeeld door het gemiddelde van de steekproef maal 100
steekproef 1: gemiddelde = 50, standarddeviatie = 10, CoV = 10 / 50 = 20%
steekproef 2: gemiddelde = 20, standarddeviatie = 10, CoV = 10 / 20 = 50%
Als vuistregel: een CoV < 10 is heel goed, tussen 10-20 is goed and tussen 20-30 is redelijk.
Visualisatie van data
Een belangrijke stap in de statistiek is om de data te visualiseren. Data visualisatie dient verschillende doelen binnen de statistiek:
- Visualisatie of de data normaal is verdeeld
- Wat is de spreiding van de data?
- Spotten van uitbijters
- Wat zijn de trends / patronen / relaties in de data?
- Is er een verschil tussen de experimentele condities?
- Samenvatten van complexe data in begrijpbare figuren
Om grafieken te maken in R gebruiken we het ggplot2 package. Voor een introductie in het gebruik van ggplot2 zie les2 van de cursus tlsc-ibip2v-24
Dotplot
Gebruik een dotplot om de frequentie en het bereik van discrete data te visualiseren.
Met de functie geom_dotplot() van ggplot2 maken we een dotplot in R:
# data koppelen aan een R object
les5_data1<-tibble(data=c(2,2,4,5,5,5,8,9,9,12))
# maak een dotplot met ggplot2
les5_data1 |>
ggplot(aes(x = data)) +
geom_dotplot(
binwidth = 1, # de data wordt verdeeld met een stap van 1
dotsize = 1) + # de grootte van de "dots"
scale_x_continuous(
breaks = seq(0, 12, 1), # streepjes op de x-as("tick marks")
limits = c(0, 12)) + # bereik van de x-as
scale_y_continuous(NULL, breaks = NULL) # verwijder de y-as
# Opmerking: in deze dataset zien we dat de maximale waarde 12 is.
# Bij een onbekende dataset kan je de waarde van 12 vervangen door max(r-object$kolom)
# zodat automatisch de maximale waarde bepaald wordt.
# vervang r-object en kolom met de naam van het object en naam van de kolom die gebruikt zijn in je R codeBoxplot
Een boxplot wordt gebruikt om de verdeling van discrete en continue data te visualiseren met behulp van de kwartielen (Figuur 50). Een boxplot geeft ook uitbijters aan. Het eerste en derde kwartiel vormen de onder- en bovenkant van de box, en de mediaan wordt weergegeven met een horizontale lijn in de box. De verticale lijnen onder en boven de box geven de hoogste en laagste waarden weer die geen uitbijters zijn.
Een meet waarde wordt als uitbijter beschouwd als deze meer dan 1,5x de IQR overschrijdt en wordt aangegeven als een losse datapunt in de boxplot. De grenszen voor uitbijters zijn:
- Q1 - 1.5 x IQR
- Q3 + 1.5 x IQR
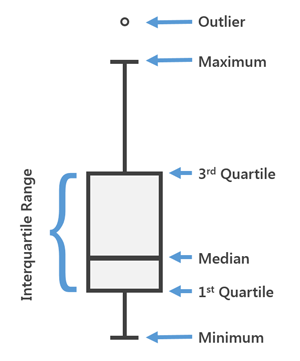
Figure 50: Interpretatie van een boxplot
Met de functie geom_boxplot() van ggplot2 maken we een boxplot in R:
# data koppelen aan een R object
les5_data2<-tibble(data=c(2,2,4,5,5,5,8,9,9,10,12))
# maak een boxplot
les5_data2 |>
ggplot(aes(x = "data", y = data)) +
geom_boxplot() +
labs(x = NULL,
y = "Values")Het is ook mogelijk om meerdere boxplots in één figuur te maken. We maken gebruik van het interne databestand “iris” om dit te illustreren. Voordat we een boxplot gaan maken willen we eerst de data inspecteren. Hoeveel rijen, kolommen, kolomnamen enzovoorts zodat we weten hoe de data is georganiseerd en welke informatie er in het bestand staat.
# namen van de kolommen (en dus ook hoeveel kolommen)
colnames(iris)
# laat de eerste 6 regels zien van het bestand
head(iris)Als we de data verder willen inspecteren kunnen we de dimensies bepalen (aantal rijen en kolommen) en tellen hoeveel unieke iris Species er aanwezig zijn in de dataset
# aantal kolommen en rijen
dim(iris)
# tellen hoe veel verschillende iris species aanwezig zijn in kolom "Species"
iris$Species |> unique()We zien dus dat er drie soorten iris aanwezig zijn (setosa, versicolor en virginica) en dat voor iedere soort 4 eigenschappen zijn gemeten (Sepal.Length, Sepal.Width, Petal.Length en Petal.Width). We kunnen voor iedere eigenschap en iris soort een boxplot maken. In dit voorbeeld worden voor de 3 iris soorten de meetwaarden van Sepal.Length geplot:
iris |>
ggplot(aes(x = Species, y = Sepal.Length)) +
geom_boxplot() +
theme_minimal() +
labs(
title = "Kelkbladlengtes voor de verschillende irissoorten",
x = "Soort iris",
y = "Kelkbladlengte (cm)"
)Met een boxplot (Figuur 51) kunnen we ook de verdeling van de data beoordelen. De verdeling van de (continue) data bepaalt welke statistische toets kan worden uitgevoerd (zie les6 en les7)

Figure 51: Boxplots and distributions
- Bij een gelijke verdeling is de (grijze) box in twee gelijke delen verdeeld.
- Bij een positieve scheve verdeling (positive skew) is de (grijze) box niet in twee gelijke delen verdeeld. De rechter helft is groter dan de linker helft.
- Bij een negatieve scheve verdeling (negative skew) is de (grijze) box niet in twee gelijke delen verdeeld. De linker helft is groter dan de linker helft.
les5_opdracht
In bestand les5_opdracht1.txt staan de concentraties van een metaboliet in het bloed (ng/ml) van 4 verschillende patiëntgroepen
- Kopiëer bestand les5_opdracht1.txt vanuit de gedeelde map (/home/data/mizi3v/les5) naar de map mizi3v/data/les5 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Importeer het bestand in R (voor instructie over data importeren in R zie les2 van de cursus tlsc-mizi2v-24)
- Bereken voor iedere groep de IQR, gemiddelde en de mediaan m.b.v de functies
group_by()ensummarize() - Maak voor iedere groep een boxplot
Interpreteer de boxplots:
- Vergelijk groep1 met groep2. Welke boxplot heeft de grootste IQR?
- Benoem voor iedere boxplot hoe de data is verdeeld (normaal, negatief of positef scheef) (je kan hiervoor ook ook het gemiddelde en de mediaan gebruiken)
Klik voor het antwoord
library(tidyverse)
library(ggplot2)
les5_opdracht1<-read_tsv("data/les5/les5_opdracht1.txt")
# Berekenen voor iedere group de IQR, gemiddelde en de mediaan
# Gebruik hiervoor de group_by(), summarize() en de iqr(), mean(), median() functies
les5_opdracht1 |>
group_by(groep) |>
summarize(
IQR=IQR(bloedmetaboliet, type=2),
gemiddelde=mean(bloedmetaboliet),
mediaan=median(bloedmetaboliet)
)
# Maak Boxplots mbv ggplot() en de geom_boxplot() functies
les5_opdracht1 |>
ggplot(aes(x=as.factor(groep), y=bloedmetaboliet))+
geom_boxplot()+
theme_minimal() +
labs(
title = "distributies met verschillende eigenschappen",
x = "groep",
y = "bloedmetaboliet (ng/ml)"
)Histogram
Een andere manier om de verdeling van de meetwaarden weer te geven is met een histogram. Een histogram geeft weer hoeveel meetwaarden er zijn die binnen een bepaald bereik vallen. Het bereik wordt ook wel een bin genoemd en het aantal bins (en daarmee ook het bereik) wordt automatisch bepaald door de geom_histogram() functie. Om een histogram te maken maken we gebruik van een dataset die afkomstig is van het het R package “dslabs”. Dit package bevat verschillende datasets om mee te oefenen binnen R.
- Installeer het “dslabs” package in Rstudio
install.packages("dslabs")
library(dslabs)- Voor het maken van een histogram gebruiken we dataset ‘olive’ van de dslabs package
De ‘olive’ dataset bevat de samenstelling in percentage van acht vetzuren gevonden in de lipidefractie van 572 flessen Italiaanse olijfolie.
- Inspecteer de dataset
# data inspectie van het olive object
view(olive) # laad de data in de Rstudio viewer
dim(olive) # hoeveel rijen en kolommen zijn aanwezig
olive |> count(region, area) # tel hoeveel waarnemingen er zijn voor iedere regio en areaWe selecteren alleen de meetwaarden van de regio “Northern Italy” met de filter() functie en visualiseren de verdeling van de meetpunten voor het vetzuur palmitic:
olive |>
filter(region=="Northern Italy") |>
ggplot(aes(x=palmitic))+
geom_histogram(binwidth = 0.2)Met een “gladde” histogram kan je beter inschatten of de data normaal is verdeeld. Voor een “gladde” histogram maken we gebruik van de geom_density() functie:
olive |>
filter(region=="Northern Italy") |>
ggplot(aes(x=palmitic))+
geom_density()En voor het detecteren van uitbijters maken we gebruik van de geom_boxplot() functie:
olive |>
filter(region=="Northern Italy") |>
ggplot(aes(x=palmitic))+
geom_boxplot()Dus, gebruik een combinatie van figuren om de verdeling van de data en uitbijters te visualiseren (zie figuur 52)
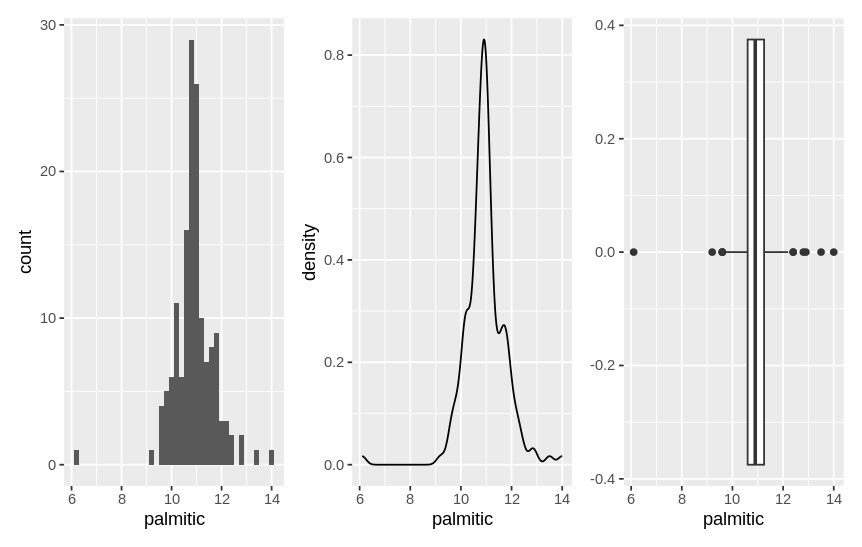
Figure 52: Verdeling van palmitic meetwaarden in olijfolie uit Northen Italy
Als de data niet normaal verdeeld is zien we een scheve histogram (zie figuur 53)
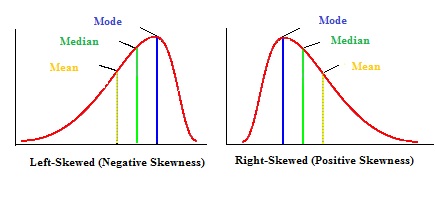
Figure 53: Scheve verdelingen
- Bij een normale verdeling is het histogram symmetrisch verdeeld
- Bij een positieve scheve verdeling (positive skew) heeft het histogram een staart naar rechts. Het gemiddelde is groter dan de mediaan (zie figuur 53)
- Bij een negatieve scheve verdeling (negative skew) heeft het histogram een staart naar links. Het gemiddelde is kleiner dan de mediaan (zie figuur 53)
Naast een positieve of negatieve scheve verdeling kunnen we ook een bimodale verdeling waarnemen (Figuur 54). Dit gebeurt wanneer er twee of meerdere subpopulaties aanwezig zijn binnen de populatie die is gemeten.
Bijvoorbeeld, als we de verdeling analyseren van alle meetwaarden van het vetzuur palmitic (zonder rekening te houden met de drie verschillende regio’s) zien we twee verschillende pieken (zie figuur 54).
olive |>
ggplot(aes(x=palmitic))+
geom_density()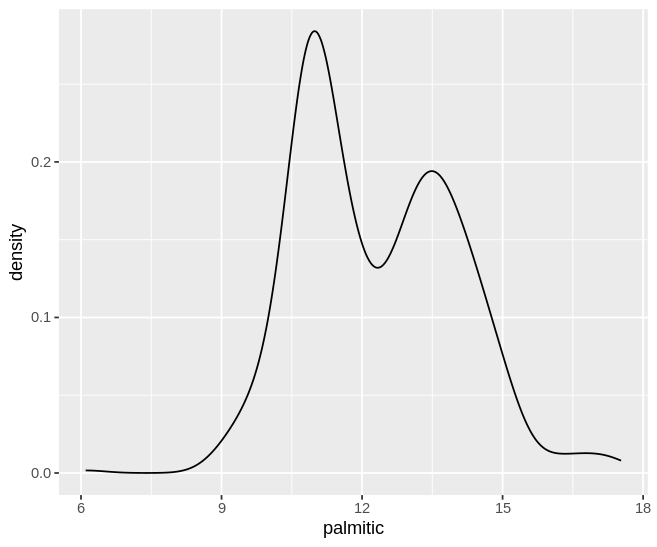
Figure 54: Bimodal distributie
Als we de verdeling van de verschillende regio’s willen zien waarbij de verdelingen niet overlappen (zie figuur 55) maken we gebruik van de geom_density_ridges() functie van het ggridges packages.
install.packages("ggridges")
library(ggridges)olive |> ggplot(aes(x = palmitic, y = region, fill = region, color = region)) +
geom_density_ridges(alpha = 0.5, show.legend = FALSE)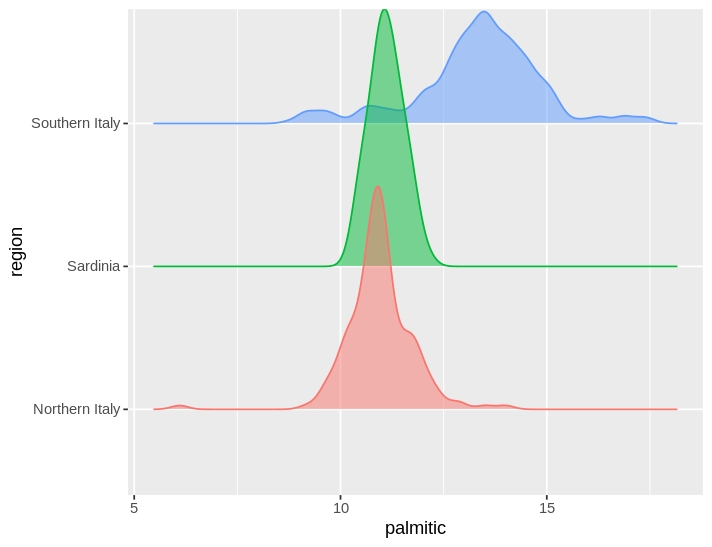
Figure 55: Bimodal distribution
les5_opdracht
Voor deze opdracht gebruiken we de dataset ‘mice_weights’ van de ‘dslabs’ package.
Voor een verdere beschrijving van de data:
- Klik op Packages (in de menubalk van het venster met de bestanden, rechtsonder in Rstudio)
- In de zoekbalk typ ‘dslabs’ en klik vervolgens op de link van ‘dslabs’
- Aan de linkerkant zoek op de data set ‘mice_weights’ en klik op de link
- Bij details staat een beschrijving van alle variabele in de dataset
De data van ‘mice_weights’ is bewaard in bestand les5_opdracht2_3.csv en staat in de gedeelde map van de server
- Kopiëer bestand les5_opdracht2_3.csv vanuit de gedeelde map (/home/data/mizi3v/les5) naar de map mizi3v/data/les5 in je homedirectory (zie ook bijlage 3 hoe je data kopiëert op de server)
- Importeer het bestand in R (voor instructie over data importeren in R zie les2 van de cursus tlsc-mizi2v-24)
- Inspecteer de data in R
- Maak vier boxplots van de variabele ‘body_weight’ voor de 4 experimentele groepen
- Maak een “gladde” histogram van de variabele ‘bone_weight’ voor de 4 experimentele groepen met behulp van de ggridges package. Maak hiervoor een nieuwe kolom aan in het data object met de
mutate()functie waarbij je kolom ‘sex’ en ‘diet’ aan elkaar plakt met depaste()functie. In deze nieuwe kolom staan dus de 4 experimentele groepen (combinatie van sex en diet).
Experimentele groepen:
(1) mannetjes muizen (M) -> dieet chow
(2) mannetjes muizen (M) -> dieet high fat (hf)
(3) vrouwtjes muizen (F) -> dieet chow
(4) vrouwtjes muizen (F) -> dieet high fat (hf)
Klik voor het antwoord
# inlezen van de data
mice_weights_tbl <-read_csv("data/les5/les5_opdracht2_3.csv")
# data inspectie
view(mice_weights_tbl) # laad de data in de data-viewer van Rstudio
dim(mice_weights_tbl) # hoeveel rijen en kolommen zijn aanwezig
colnames(mice_weights_tbl) # hoeveel kolommen en wat staat er in
unique(mice_weights_tbl$sex) # hoeveel categoriëen zijn aanwezig in variabele sex
unique(mice_weights_tbl$diet) # hoeveel categoriëen zijn aanwezig in variabele diet
# tel aantal metingen voor iedere experimentele groep: sex (F,M) en diet(chow, hf)
mice_weights_tbl |>
group_by(sex,diet) |>
count()# Maak boxplots m.b.v. ggplot() en de geom_boxplot() functies
mice_weights_tbl |>
ggplot(aes(x=sex, y=body_weight, fill=diet))+
geom_boxplot()+
labs(
title="Verdeling van de variabele 'body_weight' voor de experimentele groepen",
x="geslacht",
y="lichaamsgewicht (g)")+
theme_minimal()# voeg een extra kolom toe met de experimentele groepen
mice_weights_tbl_groups <- mice_weights_tbl |>
mutate(groups=paste(sex,diet,sep="_"))
# maak histogrammen m.b.v. ggplot() en de geom_density_ridges() functies
mice_weights_tbl_groups |>
ggplot(aes(x=bone_density, y=groups, fill=diet))+
geom_density_ridges(alpha = 0.5, show.legend = FALSE)+
labs(
title="Verdeling van de variabele 'bone_density' voor de experimentele groepen",
x="bone density",
y="experimentele groep")+
theme_minimal()Staafdiagram
De dotplot, boxplot en histogram worden gebruikt om de spreiding en verdeling van de meetpunten te visualiseren. Deze grafieken worden gebruikt om te bepalen of de meetwaarden normaal verdeeld zijn.
In een OFAT experiment zijn er twee of meerdere experimentele groepen waarvan we de meetwaarden willen vergelijken om te bepalen of er een verschil is tussen de experimentele groupen. Per groep wordt het gemiddelde en de standaarddeviatie uitgerekend en weergeven met een staafdiagram + foutenbalken. Met de functie geom_col() van ggplot2 maken we een staafdiagram in R. In paragraaf Resultaten communiceren van les3 van de cursus tlsc-ibip2v-24 staat uitgelegd hoe een staafdiagram+foutbalken gemaakt wordt.
les5_opdracht
Gebruik het bestand les5_opdracht2_3.csv van opdracht2.
- Bereken het gemiddelde, standaarddeviatie en de CoV van de variabele ‘body_weight’ van alleen de vrouwtje muizen (sex = F).
- Maak een staafdiagram + errorbars van het gemiddelde + standaarddeviatie met behulp van ggplot.
Klik voor het antwoord
# gebruik het object mice_weights_tbl van opdracht2
# filteren op vrouwlijke muizen
mice_weights_tbl_F <- mice_weights_tbl |>
filter(sex=="F")
# beschrijvende statistiek voor alleen de vrouwtjes muizen
mice_weights_F_summary <- mice_weights_tbl_F |> # object met de gefilterde data voor sex =F
group_by(diet) |>
summarize(mean=mean(body_weight), # gemiddelde
sd=sd(body_weight), # standaarddeviatie
cov=(sd/mean)*100) # coëfficient of variation # Staafdiagram + errorbars met behulp van ggplot
mice_weights_F_summarize |> ggplot( aes(x = diet, y = mean)) +
geom_col() +
geom_errorbar(
aes(ymin = mean - sd,
ymax = mean + sd),
width = 0.2) +
labs(
x = "Dieet",
y = "lichaamsgewicht (grams)",
title = "Effect van dieet op lichaamsgewicht van vrouwtjes muizen na 19 weken") +
theme_minimal()Spreidingsdiagram
Een spreidingsdiagram wordt gebruikt om relaties (verbanden, correlaties) tussen twee variabelen aan te geven. Bijvoorbeeld is er een verband tussen body_weight en bone_density van de ‘mice_weights’ datsaet van opdracht2 en opdracht3. Hier maken we voor iedere experimentele condities een scatter plot waarin de meetwaarden van de ‘bone_density’ worden uitgezet tegen de meetwaarden van ‘body_weight’. Om vier aparte grafieken te verkrijgen maken we gebruik van de facet_wrap() functie. Om een regressie lijn in de grafieken te plaatsen maken we gebruik van de geom_smooth() functie in combinatie met de lm (lineair method) optie
mice_weights_tbl |>
ggplot(aes(x=body_weight, y=bone_density, color=diet))+
geom_point()+
facet_wrap(diet~sex)+
geom_smooth(method = "lm", se = FALSE, color = "black")+
labs(
title="correlatie tussen body_weight en bone_density in muizen (M, F) bij verschillende dieten",
x="lichaamsgewicht (g)",
y="bone density")+
theme_minimal()les5_opdracht
Gebruik de iris dataset om voor iedere iris soort een verband aan te tonen tussen ‘Sepal.Length’ en ‘Sepal.Width’ met behulp van een spreidingsdiagram. Gebruik ook de functies geom_smooth om een regressielijn aan te geven en facet_wrap() om voor iedere iris soort een aparte figuur te maken
Klik voor het antwoord
iris |>
ggplot(aes(x=Sepal.Length, y=Sepal.Width, color=Species))+
geom_point()+
facet_wrap(~Species)+
geom_smooth(method = "lm", se = FALSE, color = "black")+
labs(
title="correlatie tussen Sepal.Length en Sepal.Width van 3 iris soorten",
x="Sepal.Length (cm)",
y="Sepal.Width (cm)")+
theme_minimal()Casus
In de casus gaan we de eigenschappen van het menselijk genoom beschrijven. Het genoom bestaat uit verschillende fucntionele elementen zoals protein coding genen, long non-coding RNAs (lncRNA) en microRNAs. Vanuit de ensembl databank zijn alle functionele elementen bijbehorende eigenschappen verkregen. De ensembl data is opgeslagen in bestand les5_casus_uniq_ensembl_GRCh38.tsv
- Kopiëer het bestand van de gedeelde folder naar de folder mizi3v/data/les5 in je home-account
- Lees het bestand in en inspecteer de data
- Hoeveel rijen en kolommen zijn aanwezig?
- Wat zijn de kolomnamen?
- Hoeveel protein_coding, lncRNA en miRNA genen zijn aanwezig per chromosoom?
- We willen graag de eigenschappen (Transcript_length, Gene_%_GC_content en Transcript_count) van protein_coding genes en lncRNAs met elkaar vergelijken:
Is er een verschil in de grootte van de Transcript_length tussen protein_coding genes en lncRNAs?
- Bereken het gemiddelde en de mediaan van de ‘Transcript_length’ van de protein_coding en lncRNA genen
- Gebaseerd op het gemiddelde en de mediaan, wat voor verdeling heeft de ‘Transcript_length’ van de protein_coding genes en lncRNAs?
- Gebaseerd op het gemiddelde en de mediaan, wat voor verdeling heeft de ‘Transcript_length’ van de protein_coding genes en lncRNAs?
- Maak een boxplot van de ‘Transcript_length’ van de protein_coding genes en lncRNAs
- Maak een ‘gladde histogram’ van de ‘Transcript_length’ van de protein_coding genes en lncRNAs. Gebruik de
geom_density_ridges()functie
- Ieder gen kan meerdere transcripten produceren (o.a. door splicing). En ieder transcript codeert weer voor een ander ander eiwit. We willen graag weten of er een verschil in het aantal transcripten (Transcript_count) tussen protein_coding genes en lncRNAs?
- Bereken de kwantielen van de ‘Transcript_count’ van protein_coding genes en lncRNAs
- Wat is je conclusie?
Protein-codings zijn verrijkt voor CG nucleotiden (Gene_%_GC_content) in vergelijking met genome regios’s die geen genen bevatten. We willen graag weten of er een verschil is in de GC_content (Gene_%_GC_content) tussen protein_coding genes, lncRNAs en miRNAs. In kolom Gene_type staan verschillende type genen (levels) waaronder dus protein_coding genes, lncRNAs en miRNAs.
- Welke levels en hoeveel metingen per level zijn aanwezig in kolom ‘Gene_type’
- Bereken voor protein_coding genes, lncRNAs en miRNAs gemiddelde en de standaarddeviatie van “Gene_%_GC_content
- Maak een staafdiagram + errorbars van de gemiddelde GC waarden en bijbehorende standaarddeviaties
- Wat is je conclusie?